对我个人而言,最快的学习方式都是一边用一边学,于是继一年前通过9块9的在线课程入门后,最近半年都在频繁使用python开发一些小工具。
python真的是个有趣的东西,在以前真的很难想象,我在学习和工作的同时,后台还跑着两个刚入门的我写的程序,不停的帮我自动处理各种数据。
最近自己的两个小项目觉得都特别有意义,决定把hexo同步文章到公众号这个分享出来。相信对很多人而言,比我更有用处(毕竟我只会玩点技术,运营就是渣渣)。
这篇文章重点参考了 Python爬取网上文章并发表到微信公众号 ,我针对接口调整和自己实际情况,进行了一些调整。感谢作者的分享。
准备 设计结构 由于之前的实践,我先做了一种假设:
1、在本地运行hexo,然后通过 requests 和 BeautifulSoup 爬取和解析列表存到本地sqlite数据库,然后内容和样式爬下来;
2、将相关图片从对象存储下载下来,调用公众号接口上传到微信公众号素材;
3、组装好所有内容,调用公众号接口上传到草稿箱;
4、确认内容,调用公众号接口发布。
这里面有个问题,是后面才发现的,所以实际上的流程并不是这样,下面我会说。
验证设想 设想有了,就构造各种方法,每个方法都测试一下。
验证过程就省略了,说下最后的流程和如此选择的原因。
实际上我从本地运行的hexo站点爬完所有内容进行测试的时候,本希望直接上传爬到的样式,公众号就能够完美呈现。然而我想多了,很多样式会被吃掉,而且有的样式在公众号呈现的结果和网页并不一样。
因此,我最后选择了直接用本地的markdown文件解析为最基本的html文档结构,然后参照 mdnice 的样式以及微信公众号自带编辑器的样式,对html重新定义样式。
那么废话少说,开工。
实践 抓取、构造数据 首先是爬取列表,定义一个获取列表内容的方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import osimport timeimport reimport requestsimport yamlimport sqlite3import loggingimport logging.configfrom my_fake_useragent import UserAgentfrom bs4 import BeautifulSoupconfig_file = open ('config.yml' , encoding="utf-8" ) conf = yaml.safe_load(config_file) def getPostList (): posts_arr = [] index = 0 max = conf["source" ]["max_page" ] for i in range (1 , max ): list_url = conf["source" ]["url" ]+'page/%s' %(i) if i == 1 : list_url = conf["source" ]["url" ] r = requests.get(list_url, headers=getRandomUA(), verify=False ) root = BeautifulSoup(r.content, 'html.parser' ) node_arr = root.select('#main section.post a' ) for node in node_arr: date_str = node.time.text.replace('年' , '-' ).replace('月' , '-' ).replace('日' , '' ) timeArray = time.strptime(date_str, "%Y-%m-%d" ) ret = int (time.mktime(timeArray)) posts_arr.append({'url' : node.attrs['href' ], 'title' : node.h1.text, 'summury' : node.p.text, 'time' : ret, 'date' : date_str, 'index' : index}) index += 1 posts_arr.sort(key=posts_sort, reverse=True ) for post in posts_arr: insert2Db(post['url' ], post['title' ], post['summury' ], post['time' ]) logger.info('All posts inserted!' ) def posts_sort (k ): return k['index' ]
接下来按列表来爬取详情,特别说明一下,这里的 formatApiHighlight 方法是调用了一个接口来格式化代码高亮,实际上本地是可以用 pygments 库来处理的,处理完后把css样式代码赋值给html代码即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 def dealPostList (max_posts ): cur = con.cursor() index = 0 try : cur.execute('select url,summury,title,time from posts where complete is null order by time' ) results = cur.fetchall() logger.info('共查询到{}篇需要上传草稿的文章,预计将要处理{}篇' .format (len (results), max_posts if max_posts > -1 else len (results))) for result in results: logger.info('开始处理第{}篇需要上传草稿的文章' .format (index+1 )) md_file_path = conf["source" ]["system_path" ] + result[0 ].strip("/" ) if os.path.exists(md_file_path + '.md' ): md_file_path += '.md' else : md_file_path += '.markdown' with open (md_file_path, 'r' , encoding='utf-8' ) as f: text = f.read() html_content = mistune.html(text) key_word = '<hr/>' html_content = html_content[html_content.find(key_word)+len (key_word):] key_word = '<hr />' html_content = html_content[html_content.find(key_word)+len (key_word):] root = BeautifulSoup(html_content, 'html.parser' ) title = result[2 ] content_arr = root.find_all(recursive=False ) logger.info("初步处理的Html原始内容:" +str (content_arr)) new_content_arr = [] for content in content_arr: new_node = content if content.name == 'p' : content.attrs['style' ] = "padding-top: 8px; padding-bottom: 8px; line-height: 26px;" if content.img: content.attrs['mpa-paragraph-type' ] = "image" content.attrs['align' ] = "center" else : content.attrs['mpa-paragraph-type' ] = "body" if content.code: content.code.attrs['style' ] = "font-size: 14px; padding: 2px 4px; border-radius: 4px; margin-right: 2px; margin-left: 2px; color: rgb(30, 107, 184); background-color: rgba(27, 31, 35, 0.05); font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace; word-break: break-all;" elif content.name == 'blockquote' : content.attrs['style' ] = "border-top: none; border-right: none; border-bottom: none; font-size: 0.9em; overflow: auto; border-left-color: rgba(0, 0, 0, 0.4); background: rgba(0, 0, 0, 0.05); color: rgb(106, 115, 125); padding: 10px 10px 10px 20px; margin-bottom: 20px; margin-top: 20px;" content.attrs['mpa-paragraph-type' ] = "quote" content.attrs['class' ] = "multiquote-1" elif content.name == 'code' : lexer = 'bash' if content.has_attr('class' ) and 'language-' in content.attrs['class' ]: lexer = content.attrs['class' ][content.attrs['class' ].rindex('-' )+1 :] new_node = formatApiHighlight(content, lexer) if not new_node: return False elif content.name == 'pre' : if content.code: lexer = 'bash' if content.code.has_attr('class' ) and 'language-' in content.code.attrs['class' ]: lexer = content.code.attrs['class' ][content.code.attrs['class' ].rindex('-' )+1 :] new_node = formatApiHighlight(content.code, lexer) if not new_node: return False elif content.name == 'h1' : content.attrs['style' ] = "margin-top: 30px; margin-bottom: 15px; font-weight: bold; font-size: 24px;" elif content.name == 'h2' : content.attrs['style' ] = "margin-top: 30px; margin-bottom: 15px; font-weight: bold; font-size: 22px;" elif content.name == 'h3' : content.attrs['style' ] = "margin-top: 30px; margin-bottom: 15px; font-weight: bold; font-size: 20px;" if not new_node: new_content_arr.append(content) else : new_content_arr.append(new_node) if len (new_content_arr) < 1 : logger.exception('新内容节点数太少,请检查问题!' ) return False res = dealPostDetail(title, result[1 ], new_content_arr, conf["source" ]["public_url" ]+result[0 ]) if res: markAsComplete(result[0 ], res) index += 1 if max_posts > -1 and index >= max_posts: exit() except Exception as e: logger.exception('文章内容处理失败' ) return False
组织草稿内容 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 def dealPostDetail (title, summury, content_arr, origin_url ): logger.info("======================================" ) logger.info('开始处理[标题]《{}》的文章...' .format (title)) cover_id = None s = requests.session() s.keep_alive=False for content in content_arr: link_node = content.a if link_node: del content.a["href" ] img_node = content.img if img_node: logger.info("图片节点信息:" +str (img_node)) logger.info("开始处理图片[url]{}..." .format (img_node['src' ])) src_url = img_node['src' ] a = urlparse(src_url) file_name = os.path.basename(a.path) if not os.path.exists("tmp" ): os.mkdir("tmp" ) if not os.path.exists("tmp/images" ): os.mkdir("tmp/images" ) img_path = 'tmp/images/' +file_name if not os.path.exists(img_path): try : tmp = s.get(src_url, stream=True , headers=getRandomUA()) if str (tmp) == '<Response [200]>' : with open (img_path, 'wb' ) as f: f.write(tmp.content) else : logger.info("博客图片下载失败:" +src_url) continue except : logger.exception("博客图片下载失败:" +src_url) continue image_valid = imageBrokenCheck(img_path) if not image_valid: os.remove(img_path) continue if not cover_id: cover_id = uploadWxCover(img_path, title) logger.info("[图片]{}的尺寸为:{}" .format (src_url, os.path.getsize(img_path))) if os.path.getsize(img_path) > 1048576 : compress_image(img_path) new_url = uploadWxImg(img_path) if not new_url: exit() content.img['src' ] = new_url if os.path.exists(img_path): os.remove(img_path) if not cover_id: api_src_url = conf["source" ]["404_cover_url" ] try : api_tmp = s.get(conf['tool' ]['api_src_url' ], headers=getRandomUA()) resJson = api_tmp.json() if str (resJson['code' ]).strip() == '200' : api_a = urlparse(resJson['imgurl' ]) api_file_name = os.path.basename(api_a.path) if not os.path.exists("tmp" ): os.mkdir("tmp" ) if not os.path.exists("tmp/images" ): os.mkdir("tmp/images" ) api_img_path = 'tmp/images/' +api_file_name api_img_tmp = s.get(resJson['imgurl' ], stream=True , headers=getRandomUA()) with open (api_img_path, 'wb' ) as f: f.write(api_img_tmp.content) else : return False except : logger.exception("api随机图片下载失败:" +api_src_url) return False cover_id = uploadWxCover(api_img_path, title) if os.path.exists(api_img_path): os.remove(api_img_path) content_str = '<section style="font-size: 16px; color: black; padding-right: 10px; padding-left: 10px; line-height: 1.6; letter-spacing: 0px; word-break: break-word; text-align: left;">' for content in content_arr: content_str += str (content) content_str += '</section>' content_str = dealWxKeyword(content_str) logger.info('组装好的文章内容:' ) logger.info(content_str) res = uploadWxPost(title, summury, content_str, cover_id, origin_url) if res: logger.info('已处理完[标题]《{}》的文章' .format (title)) logger.info("======================================" ) return res logger.error('处理[标题]《{}》出现严重错误,自动中断' .format (title)) exit()
上面的方法中涉及到了2个额外的方法。其中之一,是上传头图,这张图必须用单独的公众号接口,因为我们需要它的媒体ID。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def uploadWxCover (src_url, title ): url = 'https://api.weixin.qq.com/cgi-bin/material/add_material?access_token={}&type={}' .format (wx_token, 'image' ) ext_name = os.path.splitext(src_url)[-1 ] request_file = { 'media' : (title+ext_name, open (src_url, 'rb' ))} try : wx_res = requests.post(url=url, files=request_file) obj = json.loads(wx_res.content) logger.info('[uploadWxCover]get wx response:' ) logger.info(obj) return obj['media_id' ] except Exception as e: logger.exception('上传封面图到微信错误:' +str (e)) return False
另一个方法就是上传正文图片,然后拿到url。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def uploadWxImg (src_url ): wx_img_url = 'https://api.weixin.qq.com/cgi-bin/media/uploadimg' file_name = os.path.basename(src_url) request_file = { 'media' : (file_name, open (src_url, 'rb' )) } data = { 'access_token' : wx_token } try : wx_res = requests.post(url=wx_img_url, files=request_file, data=data) obj = json.loads(wx_res.content) logger.info('[uploadWxImg]get wx response:' ) logger.info(obj) return obj['url' ] except Exception as e: logger.exception('上传内容图到微信错误:' +str (e)) return False
上传草稿 因为自己使用的关系,代码比较随意,上传草稿的接口在上面的代码里其实已经调用了,就是 res = uploadWxPost(title, summury, content_str, cover_id, origin_url) 这段。方法内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 def uploadWxPost (title, summury, content, cover_id, content_source_url ): if len (title) > 64 : title = title[:63 ] if len (summury) > 120 : summury = summury[:119 ] url = 'https://api.weixin.qq.com/cgi-bin/draft/add?access_token=' +wx_token data = { "articles" : [ { "title" : title, "author" : conf["wx" ]["author" ], "digest" : summury, "content" : content, "content_source_url" : content_source_url, "show_cover_pic" : 1 , "need_open_comment" : 0 , "only_fans_can_comment" : 0 , "thumb_media_id" : cover_id } ] } try : wx_res = requests.post(url=url, data=json.dumps(data, ensure_ascii=False ).encode("utf-8" )) logger.info(wx_res) obj = json.loads(wx_res.content) logger.info('[uploadWxContent]get wx response:' ) logger.info(obj) return obj['media_id' ] except Exception as e: logger.exception('上传所有内容到微信错误:' +str (e)) return False
发布文章 特别提醒 :如果你需要勾选 原创 或者 赞赏 ,那么先不要发布!一定先到后台手动编辑!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 def publishPostList (max_posts ): cur = con.cursor() index = 0 try : cur.execute('select url,m_id,title,time from posts where p_id is null order by time' ) results = cur.fetchall() logger.info('共查询到{}篇需要发布的文章,预计将要处理{}篇' .format (len (results), max_posts if max_posts > -1 else len (results))) for result in results: logger.info("======================================" ) logger.info('开始发布[标题]《{}》的文章...' .format (result[2 ])) if not result[1 ]: logger.error('文章缺少媒体ID,无法发布,略过' ) continue p_id = publishWxPost(result[1 ]) if p_id: markAsPublish(result[0 ], str (p_id)) time.sleep(30 ) getSingleArticleId(str (p_id)) else : logger.exception('发布[标题]《{}》出现严重错误,自动中断' .format (result[2 ])) index += 1 if max_posts > -1 and index >= max_posts: exit() except Exception as e: logger.exception('发布[标题]《{}》出现严重错误,自动中断' .format (result[2 ])) return False def publishWxPost (m_id ): url = 'https://api.weixin.qq.com/cgi-bin/freepublish/submit?access_token=' +wx_token data = { 'media_id' : m_id } try : wx_res = requests.post(url=url, data=json.dumps(data, ensure_ascii=False ).encode("utf-8" )) obj = json.loads(wx_res.content) logger.info('[publishWxContent]get wx response:' ) logger.info(obj) return obj['publish_id' ] except Exception as e: logger.exception('发布微信文章错误:' +str (e)) return False
至此,发布完成。接下来可以在公众号后台进行后续操作。
微信Token 前面一直没有提,相对的,我也觉得这一步其实没有什么说的必要,因为任何微信接口肯定都需要token。
但是一路写下来,好像每个步骤都在提微信token,那就还是给它露个脸吧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def getWxToken (): if not os.path.exists("tmp" ): os.mkdir("tmp" ) token_path = 'tmp/token.txt' if os.path.exists(token_path): with open (token_path, 'r' , encoding='utf-8' ) as f: data = json.load(f) if data and data['access_token' ]: t = time.time() if data['expires_in' ] > int (t) - data['time' ]: print ('[Suprise!] local wx access_token valid! ' , data['access_token' ]) return data['access_token' ] try : wx_res= requests.get('https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid={}&secret={}' .format (conf["wx" ]["app_id" ], conf["wx" ]["app_secret" ])) obj = json.loads(wx_res.content) logger.info('[getWxToken]get wx response:' ) logger.info(obj) t = time.time() obj['time' ] = int (t) with open (token_path, 'w' , encoding='utf-8' ) as f: f.write(json.dumps(obj)) return obj['access_token' ] except json.decoder.JSONDecodeError as e: logger.exception("微信Token接口数据解析错误..." +str (e)) return False except Exception as e: logger.exception('微信Token获取失败' ) return False
遇到的问题 本人也算是个python小白,所以实现过程中自然也有很多问题,大致梳理了一下。
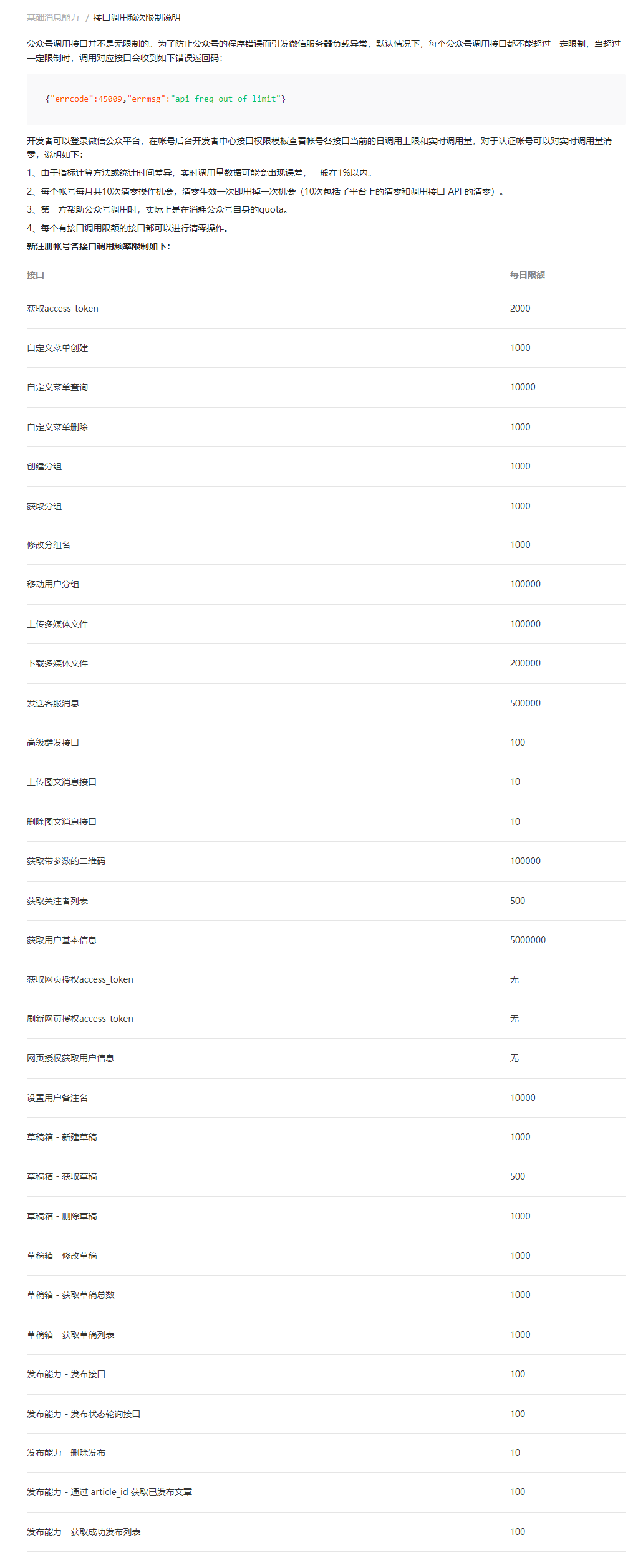
接口次数 这个就是前面提到把微信Token存下来的好处,我一直忽略了微信接口有次数的问题。由于尝试的次数太多,微信直接丢给我 errcode: 45009,我才查到这个问题。接口频次限制如下:
当然,也可参见 基础消息能力 /接口调用频次限制说明 。
文章格式优化 这个问题是比较意外的,耽搁了很久。毕竟我以为直接把带样式的html文本发过去就完了,结果居然样式全乱了。而且现在也不是最理想的状态,先将就了。
接口次数限制也是由于这个问题才发现的 😂
大神们有更好的处理办法也请分享,谢谢!
原创与赞赏 翻找了很久,发现微信开放社区有人跟我一样的疑问,为什么没有原创与赞赏接口。然后我确定了,的确没有,需要自己手动操作。
emmm🤔,懒得吐槽了,寄人篱下,多低头
资源管理 这个目前对我而言其实算不上问题,因为我是完全同步博客,不需要资源管理。
但是如果要管理,其实可以参考我十分熟悉的wordpress,以及fastadmin,用一张表单独存储附件信息,然后跟文章关联起来。思路十分简单。
使用到的接口文档 草稿箱 /新建草稿
素材管理 /新增永久素材
发布能力 /发布接口
openApi管理 /清空api的调用quota
开始开发 /获取Access token
♦ 本文固定连接:https://www.gsgundam.com/2022/2022-12-04-python-sync-hexo-to-wechat/
♦ 转载请注明:GSGundam 2022年12月04日发布于 GSGUNDAM砍柴工
♦ 本文版权归作者,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。
♦ 原创不易,如果页面上有适合你的广告,不妨点击一下看看,支持作者。(广告来源:Google Adsense)
♦ 本文总阅读量