社恐人必备,一键完成第五人格小丑助力活动。
可无限助力,输入助力链接自动提取邀请码自动助力。
不管是自用还是用来引流,都是很好的小工具。
教程下载地址
🔗 点击下载
截图预览
社恐人必备,一键完成第五人格小丑助力活动。
可无限助力,输入助力链接自动提取邀请码自动助力。
不管是自用还是用来引流,都是很好的小工具。
🔗 点击下载
别看现在看好短剧的人多,但是其实短剧热度不如之前了。
但是作为一个引流工具也是有好过没有。
而且这套资源特别简单,小白也能很快上手。
如果有渠道的话,可以快速搞一波。
🔗 点击下载-资源1
🔗 点击下载-资源2

因为最近又忙了起来,好多事情要做,经常忘记签到。就想起来以前听说过的青龙面板了,确实有很多现成的脚本可以很方便的实现自动签到。
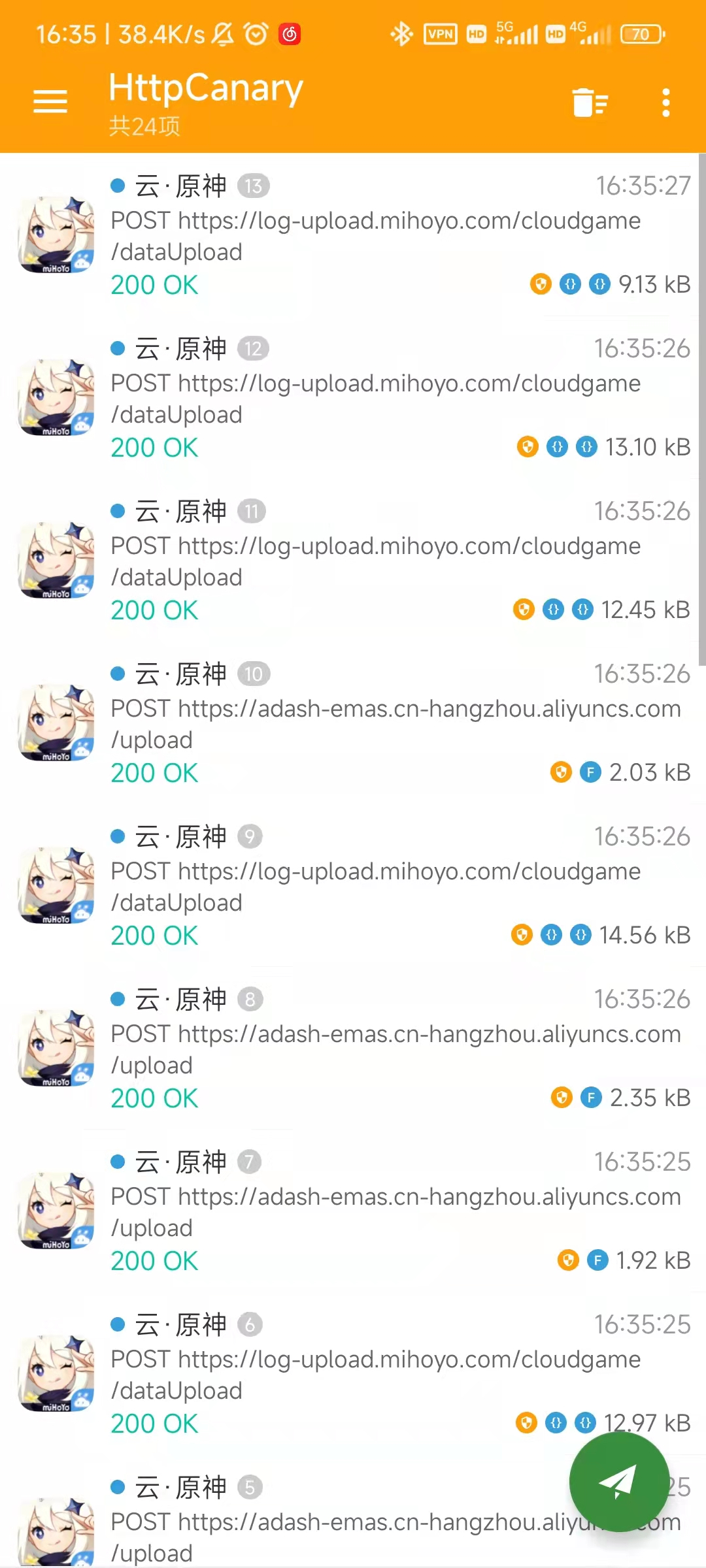
但是也出现了一些问题,例如一些app的安全等级比较高,则需要用到抓包工具来获取cookie一类的数据了。
由于安卓7引入了 SSL pinning,用户所安装的证书不再被系统信任,导致不能抓取 HTTPS 流量。想要在 Android 7~12 中抓取HTTPS,需要手机解锁并ROOT权限。 这个操作无需电脑,仅需要手机即可实现抓包。我的操作环境是 红米 K60 + MIUI 14 + KernelSU 11326 + LSPosed 1.9.2 。
先确保 KernelSU(or Magisk) 和 LSPosed(or Xposed) 已经安装完毕。网上教程很齐全,就不赘述了。
主要是按顺序刷入各个模块:HttpCanary、HttpCanary System CA Mounter、JustTrustME、TrustMeAlready。刷入完成以后重启即可,HttpCanary就会出现并可以使用了。
这种情况下,证书会自动处理好,直接抓包即可。
你肯定见过闲鱼上1元钱卖短剧、小说、教程,
可能也想到了可以通过这类资源引流广告。
在这个文章里我将陆续收录这些资源,
你可以自己大饱眼福,也可以拿去引流,
这些资源对我来说很好找,只是花点时间整理一下。
对需要它们的你来说,怎么使用才是考验,加油!
🔗 点击访问
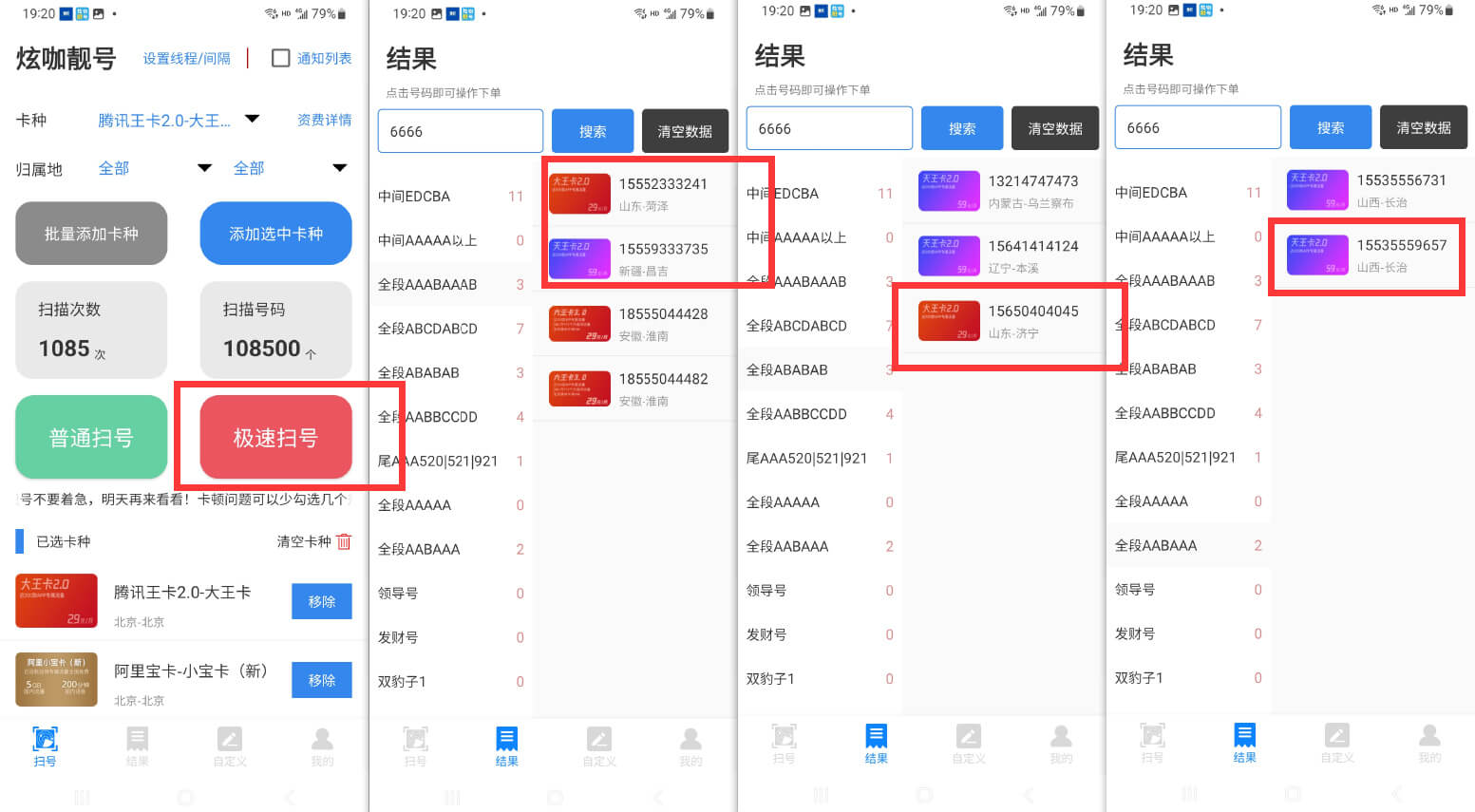
手机卡靓号扫号器,安卓手机App。
软件一直在做维护更新,功能比较完善,
经过测试是可以使用的,确实能跑出来一些靓号,
而且每天靓号都是更新的,今天不满意,次日再扫就可以。
放在闲鱼、小红书一类的引流很不错。
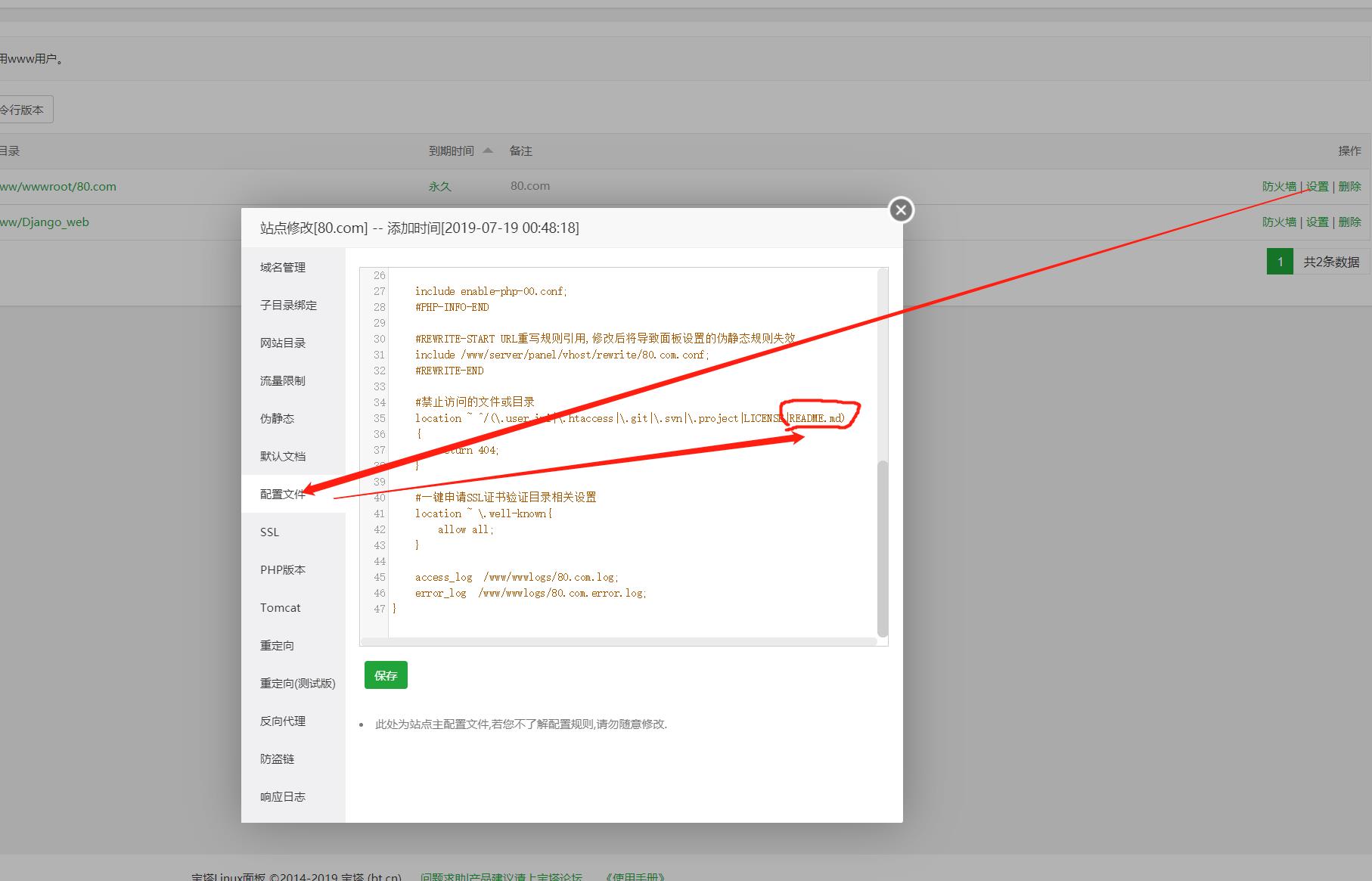
另外,可以看到我也挂了流量卡入口的,
所以,也可以试试在选择喜欢的号段之后,去看看能不能走佣金渠道。
有时候机会就是一个闪现的思路。
对于没有流量需要做推广的朋友,这个方法不只是省钱的问题,
关键是省时省力效果还好。
虽然有时候弯路必须要走,但是能少走点就少走点。
🔗 点击下载-线路1
🔗 点击下载-线路2
一个网赚大咖分享的,据说这个市场还挺大,并且涉足的人不多。
又是一个信息差挣钱的项目,外面代查一次可是要10-20块钱。
虽然是懂原理了直接秒查的玩意,但是咱可不管那些。
能迅速挣块钱的,直接开干就完了。
🔗 点击下载-线路1
🔗 点击下载-线路2

不蒜子绝对是静态博客的福音,速度快,功能强,接入极为简单。
1 | <script async src="//busuanzi.ibruce.info/busuanzi/2.3/busuanzi.pure.mini.js"> |
1 | <!--pv方式 --> |
1 | <span id="busuanzi_container_page_pv"> |
删除原本引入语句:
1 | <!-- <script async src="//busuanzi.ibruce.info/busuanzi/2.3/busuanzi.pure.mini.js"></script> --> |
在 pjax:end 部分动态引入脚本:
1 | $(document).on('pjax:end', function(){ |
自己深度测试过,对于B站和微博都非常好用。
尤其是对于B站而言,要是推的视频爆了,是可以直接变现的。
提个几十块非常容易!
站长的管理非常人性化,每周还有抽奖。
奖品的特权一可以搂到不少流量,幸运星在B站基本上就可以爆视频了。
同时网站群里面的朋友也会分享一些心得,可以学习。
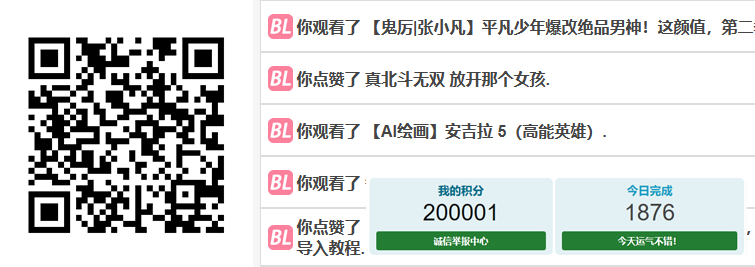
这是用最低积出价分引流的效果,如果高分出价效果拔群。
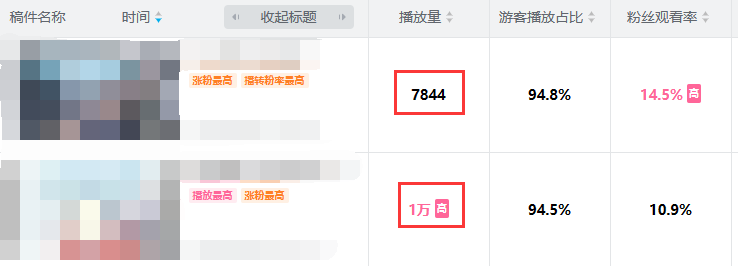
网站是好网站,但是手动操作还是费时费力。所以我自己做了工具软件,在不违反网站规则的前提下,自动完成浏览、点赞等操作。
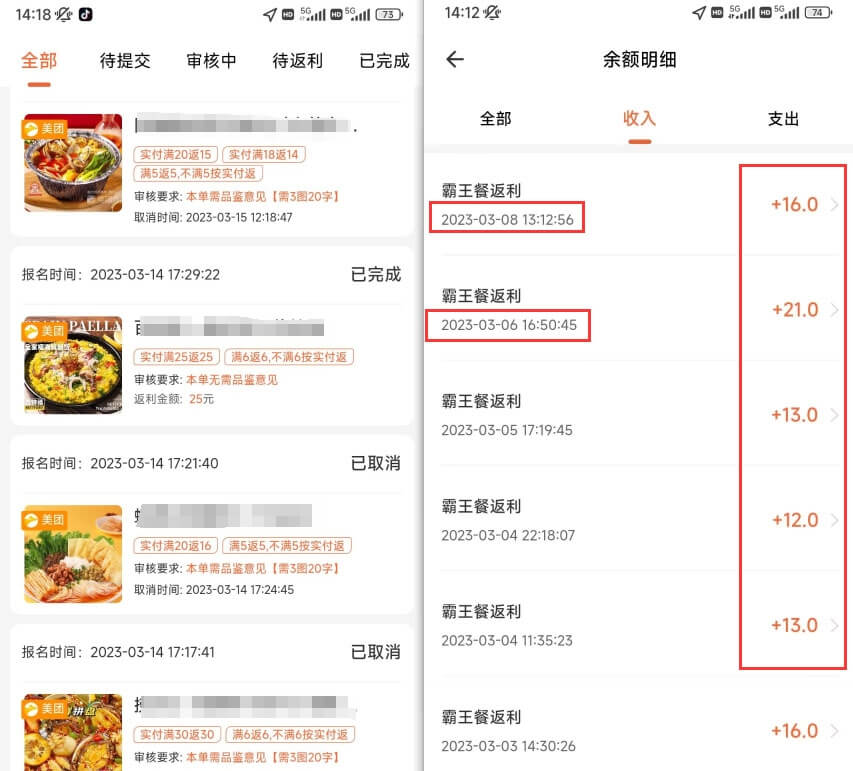
可以很便宜吃到外卖的小程序,主打一二线城市的霸王餐,绝对比领什么饿了么/美团红包实惠的多了。
目前共有2家长期平台,服务地区不同,玩法一样。
具体得自己注册看看你们地区是否能使用,如果能用的话,有些店铺是可以0-5块吃一顿饭。
我这里一顿省10+轻轻松松,自己也经常用。
具体看截图吧,爱吃外卖的话,每天3顿饭能省不少钱。
不管怎么说,省到也算是赚到吧。


提现没有门槛,而且到账都很快。
其实网赚项目相当多,每天都会出很多玩法,但是hui色、坑人的不少,个人会筛选并只推荐安全的项目。
另外有一些项目我不会直接分享出来,因为知道的人越多,大家能分到的越少。
所以这里设置一个VIP门槛,88一年,198永久。通过页面底部的 🔗 二维码付款 后,添加QQ:3765242328,我拉你进群。
说明:🔗 可点击链接;🔒 VIP项目。
一句话总结:资源随时更新,引流or走量or自用?关键看你自己。
推荐度:⭐⭐⭐⭐⭐
📅 2024.3.31
一句话总结:亲测好用,省到就是赚到。
推荐度:⭐⭐⭐⭐⭐
📅 2024.3.25
一句话总结:社恐玩家必备,可自用可引流。
推荐度:⭐⭐⭐⭐⭐
📅 2024.4.11
一句话总结:趁着短剧还有些许热度,搭建个自己的平台赶个尾巴。
推荐度:⭐⭐⭐⭐⭐
📅 2024.4.7
一句话总结:靓号扫描工具,无论自用还是引流都非常合适。
推荐度:⭐⭐⭐⭐
📅 2024.3.31
一句话总结:引流从来都是思路,方法可以千变万化。
推荐度:⭐⭐⭐⭐
📅 2024.3.28
一句话总结:又是信息差项目,王者荣耀热度一直都有。
推荐度:⭐⭐⭐⭐⭐
📅 2024.3.26
一句话总结:象棋直播本身是有流量的,这个资源也很全,但是直播需要自己迈出第一步。
推荐度:⭐⭐⭐⭐
📅 2024.3.25
一句话总结:信息差项目,赚钱引流都是相当棒的工具。
推荐度:⭐⭐⭐⭐⭐
📅 2024.3.25
一句话总结:需要一些时间,学习成本不高。
推荐度:⭐⭐⭐⭐
📅 2024.3.25
一句话总结:小羊毛,很好完成,适合挣点小零花钱。
推荐度:⭐⭐⭐⭐
📅 2024.4.3
一句话总结:最近比较火,日本综艺确实很好看,做搬运引流不错。
推荐度:⭐⭐⭐⭐⭐
📅 2024.4.1
一句话总结:B站微博推广神器,也能直接挣钱。
推荐度:⭐⭐⭐⭐⭐
📅 2024.3.26
一句话总结:刚出来的时候很火爆,现在连资源都被封了很多。
]]>更多项目整理中…

终于又一个历史遗留问题得到了解决。
起因是打算把平时经常接触到的网赚信息分享出来,几年了,自己又不太用得上,就这么都浪费了挺可惜的。但是如果没有评论系统的话,很影响互动,所以无论如何也要先修复了。
这次一共有两个问题:第一是 av-min.js 又报错了,大概是被 LeanCloud 拒绝访问了;第二个是 LeanCloud 里的历史评论无法显示出来。
本来一开始没有想到需要替换掉评论系统,只是偶然google到一个博主的博文中,提到了 Waline (https://waline.js.org/)这个从 Valine 衍生的带后端评论系统。据说可以将 Waline 理解为 With backend Valine。
仔细阅读了以后,发现极为符合我的需求。首先,客户端不再直接连接 LeanCloud ,也就是说有一个 Waline 官方提供的统一服务端来处理与 LeanCloud 的交互,非常有可能我们不用再处理 LeanCloud 频繁改动带来的连接问题;其次,Waline 不但提供了极其丰富的自定义配置和部署方式,而且文档比较完备,步骤相当简单。
当然,缺点也不是没有。一方面是依赖于 Waline 的核心服务端代码,另一方面最简单的迁移方式还是需要 LeanCloud 的服务,总之就是高度依赖于第三方服务。然而这点问题对于它给我带来的好处而言,完全可以忽略不计。
这里的步骤已经非常清晰了(https://waline.js.org/guide/get-started/),而且由于 Waline 的数据结构完全兼容 Valine,所以工作量非常小,跟着教程走就行。
这里只简单说一下几个要点:
1、国内版 LeanCloud 必须使用有备案的域名,并且由于 Waline 要使用api接口,所以还需要在 Vercel 中配置 LEAN_SERVER 这个变量, 而这个变量在 LeanCloud 上进行绑定时,部署证书的时间长得可怕,而且没有部署完是无法正常访问评论的。这一步一定耐心等待(除非你不打算用 LeanCloud ,而改用其他数据库)。
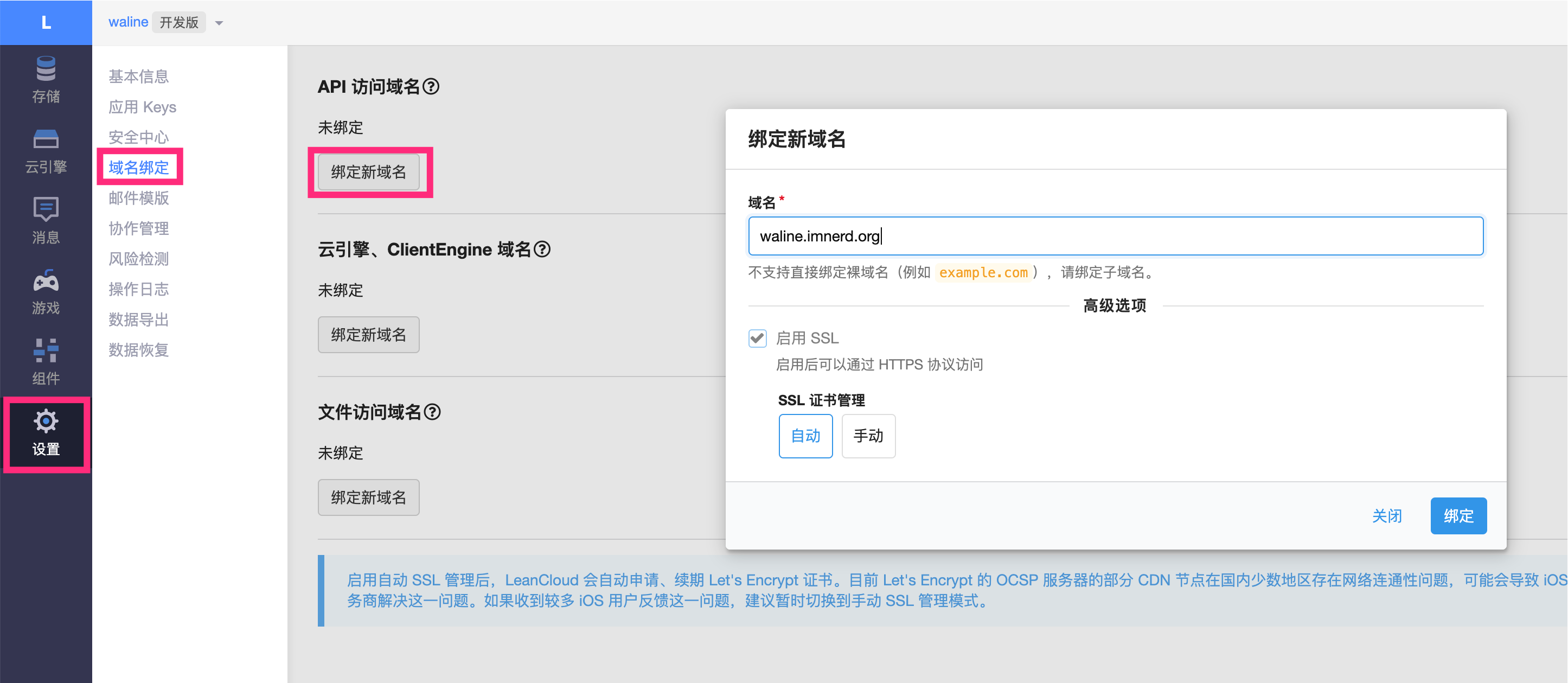
LEAN_SERVER 变量对应 “Vercel 部署 (服务端)” 的第4步
2、后端评论管理只需要记住 [二级域名].vercel.app 就可以了,没有必要自己绑定专有。这里对应 这一步。
3、客户端引入的时候,如果是普通的浏览器脚本引入方式,例如:
1 | <script src="https://cdn.jsdelivr.net/npm/@waline/client@3/dist/waline.umd.min.js"></script> |
那么初始化部分记得写成:
1 | Waline.init({ |
这里对应 “HTML 引入 (客户端)” 的第2步。
4、最后记得先去 [二级域名].vercel.app/ui/register 注册成为管理员,这样可以更方便的通过域名进行评论管理。
其实问题我早就猜到了,但是由于前面 Valine 访问 LeanCloud 的问题,修改了也看不到,无法验证。
在彻底换成 Waline 以后,问题也就轻易的暴露出来,就是我修改了文章的路径,评论系统无法通过 url 参数获取到对应的评论了。所以数据导出来,一个python脚本搞定,再导回去就结束了。
其实在过程中我也看了关于 Valine 的解决方案,这里也推荐大家有时间也可以搜索了看一下,其实对理解它的工作流程很有帮助,这也有助于自己进行项目设计,规避设计风险。
在 Waline 的实施过程中,其实我还尝试了 Vercel 和 腾讯云CloudBase 两种部署方式,也尝试了 LeanCloud 、MongoDB 、MySQL 、 SQLite 和 腾讯云CloudBase 五种数据库连接方式。其中 腾讯云CloudBase 因为现在是要收费的,不推荐, MongoDB 服务端无法访问(端口确认开放,域名也加入白名单,目前没能找到解决方案)。这个过程中我发现 Waline 开发者相当用心,因为文档详尽才能让我快速的尝试这么多方案,而 快速上手文档 中则是选择了可行性最高、最易操作的组合,真是非常棒!

这其实已经是很久之前自己就遇到过的问题了,今天有个朋友也问到了百度云加速提示证书的问题(其实我很奇怪,现在全面收费了,还折腾这个做什么?),所以顺手记录一下。
方法来自 这里。
1、打开网址:https://myssl.com/chain_download.html;
2、在输入框中填上自己的域名(不要带 http:// 或 https:// ),点击获取证书链按钮;
3 、把获取到的 RSA 证书链里的所有内容放到百度云加速的证书上传框里即可。
]]>
每天事情多得要命,全靠2毛一袋的咖啡和 精神氮泵 续命。所谓精神氮泵,自然是来自网易云音乐的给力歌曲了。
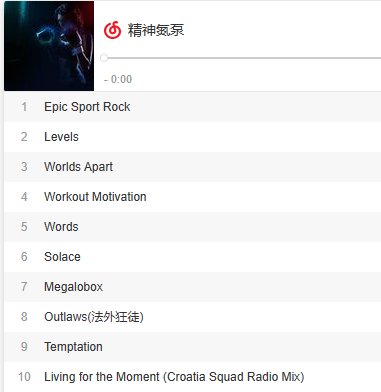
一直想整合网页版播放器到博客里跟大家一起嗨。但是放在博客里是必须要改造目前的博客,如果不进行改造,跳转页面肯定会引起播放器中断。1月份的时候尝试利用 Pjax 的特性(尝试改造Hexo主题以兼容Pjax),局部加载核心内容,而不影响播放器,可惜失败了。不过我这个人有个毛病,就是总会反复做一些事情。不信邪的我又翻出 Pjax 来研究了,别人都可以用,我相信一定有方法可以用上。
当然,这次不一样。我成功了!
我最终找到了 t0ur1st 的博客作为对比目标进行分析。首先跟我之前最大的区别是我使用了独立版的 Pjax :
1 | <script src="https://cdn.jsdelivr.net/npm/pjax@VERSION/pjax.min.js"></script> |
然而他使用了jquery版本:
1 | <script src="https://cdnjs.cloudflare.com/ajax/libs/jquery.pjax/2.0.1/jquery.pjax.min.js"></script> |
既然Gacman主题本来就用到了 jQuery ,人家都已经成功了,何必还要去折腾呢?我选择躺平!
Gacman主题继承自已经废弃的老版Jacman主题,各个模板之间的确都有些不太一样。模板不同的确会给 Pjax 改造带来一些困难,但我的Gacman其实已经大幅统一了,十分符合只更新核心部分、不更新页头/页脚和侧边栏的需求,所以不应该有这种阻碍才对。
通过一番寻找,最大的问题就是在改造响应式风格的时候,layout.ejs 对于body模块内容的适配太零散了,分别在 article.ejs 等模板里单独做了嵌套结构和样式适配。而对于我这个模板来说,其实完全可以统一起来。于是 layout.ejs 中body部分变成了:
1 | <div class="container"> |
然后在 after_footer.ejs 模板中加入 Pjax 相关代码进行测试:
1 | <script src="/js/jquery-2.2.4.min.js"></script> |
测试一下,初步运行成功了!
其实这步挺简单的,主要是个思路的问题。最佳方案是把所有零散的代码分类组合成方法,然后再看哪些方法是进网站加载一次就行的、哪些是需要跳转页面后再次加载的动态内容。
例如我的评论所使用的 Valine ,就需要在每次文章详情页中重新初始化。那就是定义好相关方法 commentInit,然后在合适的地方添加:
1 | $(document).ready(function(){ |
那么这一步验证成功后,接下来就把相关的搜索功能依葫芦画瓢就行。当然,实际上很多js是不需要动态执行的,这个要按需规划。
我这里什么插件都没有用到,直接在 footer.ejs 中增加网易云官方给出的 iframe 解决方案:
1 | <!-- 网易云音乐插件 --> |
像 <%=theme.music.src%> 这类常量当然是在 _config.yml 中配置好了。
测试一下,非常完美!
有时候其实就差那么一点顿悟,上次折腾了好几天还没能解决的问题,这次多少是让人有点兴奋。赶紧把网站更新上来,有问题也好速速改掉。
]]>将所有数据都打印出来以后,发现问题实际上是出在 strtotime 函数上。通过百度服务器获取到的时间是正确的,但是转换以后的时间戳多了8个小时出来。这明显就是时区问题了。
然而在terminal里 date 出来的时间也是对的,那么问题就极有可能是WordPress搞出来的了。我印象里 wpjam 的作者 Denis 有文章提到过他的插件有相应的转换功能。
经过简单的搜索,确实找到了文章。如果网站本身就用到了 wpjam basic 插件,那么只需要把 strtotime 替换为 wpjam_strtotime,所有问题都迎刃而解。这个函数做了这样一件事情:
1 | function wpjam_strtotime($string){ |
我突然又想到了另外一个问题,我的代码中还用到了 time() 和 date() 函数,那它们的结果正确吗?
经过测试,我这里得到了正确结果。但是抱着怀疑的态度,我还是再次上网查询。结果网上的建议是不要使用PHP原生的 time() 和 date() 函数,应该使用 current_time( 'timestamp' ) 和 wp_date() 。出于个人的谨慎,在反复确认结果无误以后,我把相关函数都换成了 current_time( 'timestamp' ) 和 wp_date() ,谨防出现新的问题。
这个问题似乎有点蠢,但是很遗憾,我的见闻里真的充满了这样的商业游戏案例,也包括多年前的自己干的傻事。很多人都是因为喜欢游戏,所以想做游戏。但是作为一个商业产品,一个游戏它总有一个市场目标,或许是为了盈利,或许是为了宣传,或许是为了进行某种验证。只有明确了这个目标,从而拆解出子目标和路径,才可能真正有目标的去完成一个商业游戏。
明确了为什么要做游戏之后,就需要明确游戏的用户群体。不同的用户群体,对游戏的需求、游戏时间、付费习惯等等都是不同的。再深入一点,不同的游戏题材、游戏类型,也会对用户群体有所影响。对目标群体越明确、精准,尤其是能够找到潜在用户群体中的痛点,进行一些独特的游戏设计,成功率就会高一些。
对于一个成熟的公司,基于一些调研和数据积累,可能会有一个比较明确的用户画像。但是对于一个缺少数据的公司或团队,经验和“第六感”就很重要了。这个时候,就需要对游戏的题材、类型、玩法、画风等等进行一些分析,然后结合自己的经验和感觉,来确定一个用户群体。
这是个很有意思的命题。对于一个游戏来说,核心玩法和核心体验是相辅相成的,核心玩法是核心体验的基础,核心体验是核心玩法的体现。所以很难说哪个更重要,哪个更需要先确定。但是从开发的角度来说,核心玩法是游戏的基础,是游戏的骨架,是游戏的灵魂。所以在确定核心体验之前,通常情况下,先确定核心玩法,是一个比较好的选择,可操作性强。
核心玩法在游戏设计中通常通过三个方面体现:战斗机制、经济体系、社交系统。其中,战斗机制往往是最重要的部分,甚至有时候核心玩法就是指的战斗机制。毕竟战斗是支撑玩家向前推进游戏最重要的部分,也是玩家在游戏中最多花费时间的部分。
战斗机制可以拆解为战斗公式、战斗规则、战斗策略、关卡机制等。经济体系包含了游戏中的货币体系、道具体系、商店体系、掉落体系等。社交系统包含了游戏中的社交关系、社交玩法、社交奖励等。当然,这三个方面的体现是有交叉的,比如战斗机制中的战斗公式,往往也会影响到经济体系中的道具体系,社交系统中的社交关系,也会影响到战斗机制中的战斗策略。
上述内容在游戏介绍的时候往往会概括成一句话特征,例如“回合制卡牌游戏”,也就是游戏类型。只是这个描述太过于笼统,在确定核心玩法的时候,需要尽可能的细化。
有一篇文章形容核心体验是整个游戏的“调性”,我觉得非常贴切。核心体验可以是一种情绪,也可以是一种感觉,它呈现出设计者想要表达的气质。它是一个游戏最抽象的总结,一个玩家在描述这个游戏所用到的关键词,就是他对这个游戏的核心体验的理解。
核心体验好不好决定了游戏的上限和生命周期,它所呈现的气质与目标用户越贴合,就越容易让用户产生共鸣,从而提升用户的新增、留存和付费。
作为一个一直重视游戏体验的人,我自己其实更倾向于先确定核心体验,然后根据用户群体的特性再去找核心玩法,确保核心玩法可以精准的体现核心体验。当然不是说这样做就没有风险,事实上有时候也会因为核心体验的确定,而导致核心玩法的选择受限,使得游戏表现平平无奇。
至于我为什么会有这个倾向,也大概与我的经历有关,尽管我经常标榜自己为一个独立开发者,但实际上我曾经为了了解游戏产品全过程而大幅降薪去从事运营和产品工作。在此期间经历过多款游戏产品,从玩法上来说平平无奇,但是由于结合运营手段,把各类用户体验做到极致,从而在商业上获得成功。加之我本身是一个注重体验的人(可能也与我本科专业有关),所以在做游戏的时候,更倾向于先确定核心体验。
当然,无论体验还是玩法,即便是在游戏上线之后,也都是需要不断迭代的。
明确了核心玩法和核心体验,就可以在此基础上进行系统规划。当然在进行规划时,一定要时刻牢记系统定位。一旦系统定位模糊不清,就非常可能导致后续的设计和开发跑偏。所以在进行系统规划时,一定要把系统定位列出来,包含多个维度、多个功能、多个目的,不能只列一个总的。这样在后续的设计和开发中,就可以时刻检查是否偏离了系统定位,保证每个设计都可以达成它的设计目的,保证游戏系统正常运转。
我之前跟其他入行策划的新同事聊天时,总会尝试跟他们聊聊规划的重要性。曾经不止一个游戏人跟我说过,自己的游戏自己还不清楚吗?放现在我一定会说,或许现在清楚,但未必过一周还清楚。就个人开发而言,如果没有对规划进行记录,那么在产生新的设计想法的时候,就很容易忘记之前的设计目的,从而导致设计的偏离。而对于团队开发而言,系统规划设计是作为大家沟通的基础,如果没有规划,那么就很容易出现沟通不畅、设计不统一的问题。
属性是构成整个游戏的基础元素,是玩法设计的最小体现。而规则可以看做是每个系统的“关键词”,同时它也是各个属性、系统之间的“纽带”。
常常会有人先去做系统和模块的详细设计,然后来总结属性和规则。这当然是可以的。但是我个人会倾向于先根据核心玩法和核心体验,总结出属性和规则,然后去做系统和模块的详细设计,再返回来查漏补缺。这样做的好处仍然是保证系统设计的目的性,同时也可以保证系统设计的完整性、一致性。
这个部分和后面的世界观是更多人关注的、也是更多人擅长的部分。这个部分是在系统规划的基础上,根据核心玩法和核心体验,进行更加具体的设计。理论上来说,只要按照总的规划来设计,不跑偏,不作妖,不会出太大的问题。
我个人一直推崇思维导图的方式进行系统设计,它可以很好的把握系统的整体性,确保所有散开的枝叶之间保持联系。当然,用其他的方式也是可以的,比如表格、流程图等。
世界观是我个人一直特别感兴趣的东西。但是它的重要性对于一个商业产品而言,更多取决于产品性质和它面向的用户群体。部分用户群体,对于世界观的要求并不高,甚至可以说不在意,那对于开发者而言,就应该把更多的精力放在核心玩法和核心体验上。
但是作为游戏的外衣,世界观绝对是不可或缺的。所有的故事情节、角色设定、画面表现,都是以世界观为基础,这样才能保持整个游戏的一致性。这层外衣通过文字表述和视觉效果共同呈现,对于重视世界观的用户群体,甚至会因为某个角色人设好、某个道具设计好,而产生强烈的共鸣,愿意为其付费。
说到这里,我也会想到过去有些特别重视世界观的游戏(特别是IP类),其实核心玩法并不突出。以至于我在想它们应该是从世界观开始设计的,然后再去找核心玩法,这样的游戏也是因为世界观的吸引力获得了成功。
当然,世界观也是可以在后续的开发中进行调整的,但是一旦调整核心部分,就会牵一发而动全身,所以在确定世界观之后,一定要尽量保持稳定。
体验设计这个东西其实特别难以量化,它可以是基于个人经验对于事实的总结,也可以基于数据分析。但是无论是哪种方式,都需要在对游戏设计有比较深入的了解、且形成一套逻辑清晰的方法论前提下,才能做出比较准确的判断。
如何进行体验设计,目前我还没有发现一个具体的规范,实施方法和过程因人而异。就我个人而言,我习惯于先构思游戏的核心循环,然后围绕这个循环,结合目标用户群体的特征去进行设计。
其实在我入行大概2年多(也就是大约15年前),我还不知道核心循环对于一个商业游戏的重要性。核心循环揭示了我们设计的游戏如何运转、驱动力来自于哪里。例如我跟老肖聊到的卡牌游戏,其核心循环可以极致简化为:关卡→养成→迭代,核心驱动力就是收集。当然,写到策划案里面并不是这么简单一句话,核心循环包含了所有玩家游戏主要行为、展示了每个部分的相关动机,与商业化循环构成一个双循环闭环。
每个类型的游戏核心驱动力各不相同,但是都基于人的天性,例如“收集”、“成长”、“竞争”、“探索”等等。可以突出某一个方面,也可以结合运用。
核心循环更像是一个分析的过程,我们通过这个模型来精准的找到重要的体验节点,从而把握住玩家体验的轻重缓急。
由于缺乏数据支撑,因此心智模型某种程度上可能是使体验设计难以量化的一大重要原因。幸运的是我们可以通过阅读和学习,来了解一些前人、专家的心智模型,然后结合自己的经验,归纳总结分析,得出自己的理论模型。
我不确定是否所有游戏策划都赞同需要这个东西,也可能是因为我大学专业的缘故把心理学在游戏中的应用放到了一个很重要的位置。但我认为,构建一个能够对玩家行为进行有效的解释和预测的模型,可以让我们能够有效地理解玩家想要什么、他们为什么想要这些,以及应该以什么样的方式满足他们的需求。
我一直赞同一个理念——“体验存在于玩家头脑里”。这来自于我职业生涯中素未谋面的策划导师 天之虹 所翻译并推荐的书《游戏设计的艺术》。至于为什么赞同,我觉得看过这本书的人应该比较容易理解。
一个游戏为什么让人沉迷?这或许是让有些人觉得游戏是一种x品的原因。但实际上它与让部分人沉迷的书本没有任何区别。但凡经历过“心流”(flow)的人,都会对那种体验难以忘怀,那是一种持续地专注、愉悦和快乐的状态。而一个拥有良好体验的游戏,一定设计了这样的体验流程,让玩家在游戏中不断地进入心流状态。
怎么去设计这样的体验流程?书里的几个关键词已经给出了思路:“清晰的目标”、“任务聚焦”、“直接的反馈”、“连续的挑战”。
记得我第一次将数据纳入我的游戏策划知识体系,是2009年接触到 天之虹 的博客。加之后来与他的简单交流(包括我去从事产品运营工作,一定程度也参考了他的建议),我将数据采集、数据沉淀、数据分析放在了相当重要的位置,也作为构建游戏之处就需要考虑的方面。
当然,这部分内容在10多年后的今天,已经不是什么新鲜话题了,早已深入游戏开发者的心中。所以我就简单说说。
数据埋点和初步分析需要在游戏开发的早期就开始进行,一方面用于验证设计的有效性、指导后续设计,另一方面为后续的数据分析提供基础。通常我们要收集的信息包括:用户基础信息、成长数据、战斗数据、经济数据、社交数据等等。
在进行数据分析前,肯定得明确我们到底需要什么:是想知道用户新增/流失情况?还是付费点与ROI的关系?
通常必要的数据分析,都包含了:用户留存、关卡流失(包括战斗平衡性)、游戏时长(包括系统使用时长)、付费点、付费习惯、付费转化率。
通常需要用到的方法包括:漏斗分析、折线图分析、对比分析、回归分析。
这个部分在小型团队其实通常不太被重视,这也是可以理解的,小型团队通常一个人要当几个人使,一个项目的生命周期通常也不会太长。而数据应用在短期内并不会带来明显的收益,从性价比来说的确非常不划算。但是对于大型团队或者公司来说,这就好比BI软件之于企业一样,是必不可少的,是后续产品不断迭代、创新的坚实基础。
数据应用包括了:数据驱动的设计、数据驱动的运营、数据驱动的迭代。就像我之前说的体验设计是可以基于数据分析的,但首先必须有足够的数据支撑。基于这些数据构建模型,从而反哺设计、运营、乃至新项目的立项,形成一个良性循环。
感觉罗里吧嗦了一大篇,大部分还是纯理论和概念的东西。但这也是无可奈何,游戏设计是实在一个庞大的体系。就这样写下来,包括商业循环、节奏、概率与奖池等东西都没涉及到。以后有机会再聊吧。
]]>Pjax 其实非常依赖布局的一致性。而目前自己名为 Gacman 的主题,本质是脱胎于老版本的 Pacman ,各个页面结构差别较大,而 Pjax 在检测到布局差别大的页面时,会自动重新拉取页面,从而失去了局部刷新的特性。
Pjax 通过ajax从服务器获取HTML,然后用加载的HTML替换页面上容器元素的内容。然后,它使用pushState更新浏览器中的当前URL。即 pjax = pushState + ajax 。
它最大的优势在于,可以在网站本身无刷新的情况下,局部刷新内容,同时在现代浏览器中支持前进和后退,由于局部加载的数据量极小,加载速度极快,因此可以最大程度的提升用户体验。
它的天生劣势在于,默认配置对 SEO 并不友好,需要大量改造来优化。
最早的时候,Pjax 是一个基于 jQuery 的插件,后来推出了完全独立的版本,适应更广泛的应用场景。
很多较早使用 Pjax 的 Hexo 主题,都使用了基于 jQuery 的版本。由于我是新引入,所以使用了最新的独立版本的 Pjax ( https://github.com/MoOx/pjax )。
1 | <script src="https://cdn.jsdelivr.net/npm/pjax@VERSION/pjax.min.js"></script> |
其实原因超简单,因为最近迷上了 精神氮泵 ,也是晚上肝代码肝图的有效工具。于是在网易云音乐做了个专辑,想放到博客里。
但是如果不进行改造,跳转页面肯定会引起播放器中断,于是就想到了利用 Pjax 的特性,局部加载核心内容,而不影响播放器。
查了不少资料,整体是参考 Volantis6 主题 Pjax 版的开发文档。
首先独立版的 Pjax 工作方式其实特别好理解。例如初始化:
1 | document.addEventListener('DOMContentLoaded', function () { |
然后是标签部分,当然,在我主题中是轻量使用 Pjax,所以主要是用在以下场景:
1 | <div class="pjax">我是将被pjax重载的内容</div> |
看上去都很顺畅,但是后来实际测试问题非常多。
我为了模块化管理,把一些脚本都放到各个模块的 ejs 中了,这就造成管理重载内容非常麻烦,需要每个地方单独改,否则就需要整理到一个地方统一处理。总之都很麻烦。
然而我还是耐着性子花了几乎一个通宵处理好了所有模板(除了评论外)。
这个是最严重的问题,独立版的 Pjax 会自动检测布局变化,如果变化过大,则会重载整个页面。
实际测试就发现非常容易触发重载,尤其是 page 和 post ,因为这两个部分原本的处理就完全不同。测试了一下,如果完全相同,则不会触发重载。
所以,最终由于这个原因,我给 Pjax 版的博客打了个分支,还是继续使用老版的主题了。

还是因为 Python 的问题,古董 Macbook Pro 2010 也登场了。过不了引导,就重装了系统。然而问题卡在了账号登录以后,条款和条件无论如何也无法同意,同意按钮是灰色的。
“智慧”的度娘没有给出任何有用的建议,还是谷哥厉害,一击解决。

网页还列出了所有会出现这个问题的系统版本,出乎意料的多:
然而,解决方案也出乎意料的简单,在登录账号的时候,点击上方的链接小字 稍后设置 ,跳过登录就完事儿了。
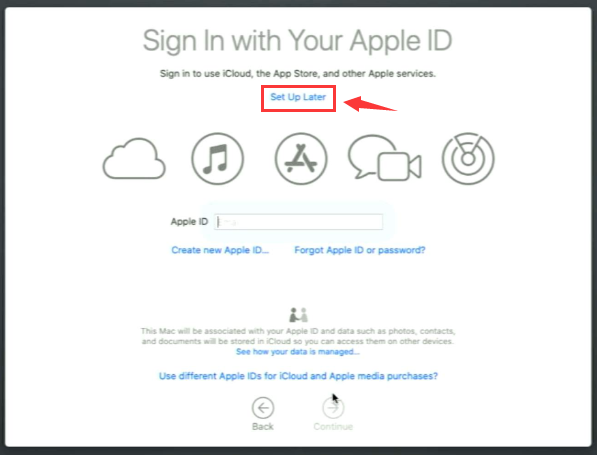
PS:顺便吐个槽,网上那些回答为了得点积分、得点流量,什么乱七八糟的、一点也不解决问题的、相关不相关的、驴头不对马嘴的答案全都出来了。咱还是留点脸行不行,不会就不会,不要浪费搜索资源。
]]>
跟大神们学习做点小东西,然后发现他们都是 Linux 和 macOS ,写出来的python代码最初是没有考虑 Windows 的。自己跑起来还是有些问题,就打算在Windows下的子系统Ubuntu来运行。
PS:那句话真是不假,除了自己的破烂系统,微软做的 Linux 和 macOS 甚至手机上的相关软件和平台真是不错 😁
这个过程挺简单,因为已经在商店安装过WSL了,因此只需要打开命令行,先检查一下是不是 v2 版本,不是就切换一下,然后升级。
1 | C:\WINDOWS\system32>wsl -l -v |
搞定。然后就是折腾 Python 版本的问题。
首先,Python3.10 并不在 Ubuntu 20.04 的默认官方源中,需要添加源单独安装。
1 | gsgundam@NUCHome:~$ sudo add-apt-repository ppa:deadsnakes/ppa |
1 | sudo apt install python3.10 |
很简单的就安装完了 Python 3.10 ,现在可以使用命令 python3 --version 打印版本,这个时候发现仍然是老版本。
1 | gsgundam@NUCHome:~$ sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.8 1 |
这里将 3.10 作为可选版本加入了,并设置为了自动选择的版本。
这个时候如果用 pip 命令来安装依赖,还是会报错。执行以下命令来修复:
1 | gsgundam@NUCHome:~$ sudo apt remove --purge python3-apt |
再跑 pip install -r requirements.txt,然后 python3 main.py,一切正常。收工。
Wordpress v6 版本下的样式问题。链接:https://pan.baidu.com/s/1rfZqL6QUx2VLjrJcfNzANw?pwd=tuy1
提取码:tuy1
注意:解压密码需要关注公众号以后,回复 emwi2023 获取。
这里可以直接关注公众号。

默认情况下,将图像添加到WordPress媒体库需要您将图像导入或上传到WordPress站点,这意味着站点中必须存储图像文件的副本。本插件允许您通过添加链接到远程图像地址的URL,将存储在外部站点中的图像添加到媒体库。通过这种方式,您可以将图像托管在除WordPress站点之外的服务器中,并且仍然可以通过各种仅从媒体库中获取图像的各类图像插件来显示它们。
该插件在“媒体”->“添加新媒体”页面、媒体上传面板和专用的“导入外链媒体”子菜单页面中提供按钮和输入框。因此,您可以在编辑任何文章或页面之前(或之后)添加外部媒体,也可以在编辑文章或页面的过程中添加外部媒体而不中断编辑过程( [GSGundam]:Wordpress V6会中断的,以后尝试修复 )。
1.将插件文件上传到 /wp-content/plugins/external-media-without-import 目录,或直接通过WordPress插件屏幕安装插件。
2.通过WordPress中的“插件”屏幕激活插件。
然后,您可以使用插件添加外部媒体而无需导入到本地。
1.单击“媒体”->“媒体库”页面中的“新增文件”按钮,将显示媒体上传面板,其中有一个“导入外链媒体”按钮。单击它。
2.或单击侧栏中的“导入外链媒体”子菜单。
3.填写要添加的图像的URL链接。您可以填写多个URL,每个URL填写一行。
4.单击“添加”按钮,将添加远程图像。
单击媒体上传面板中的“导入外链媒体”按钮,将显示“从链接导入媒体”面板:
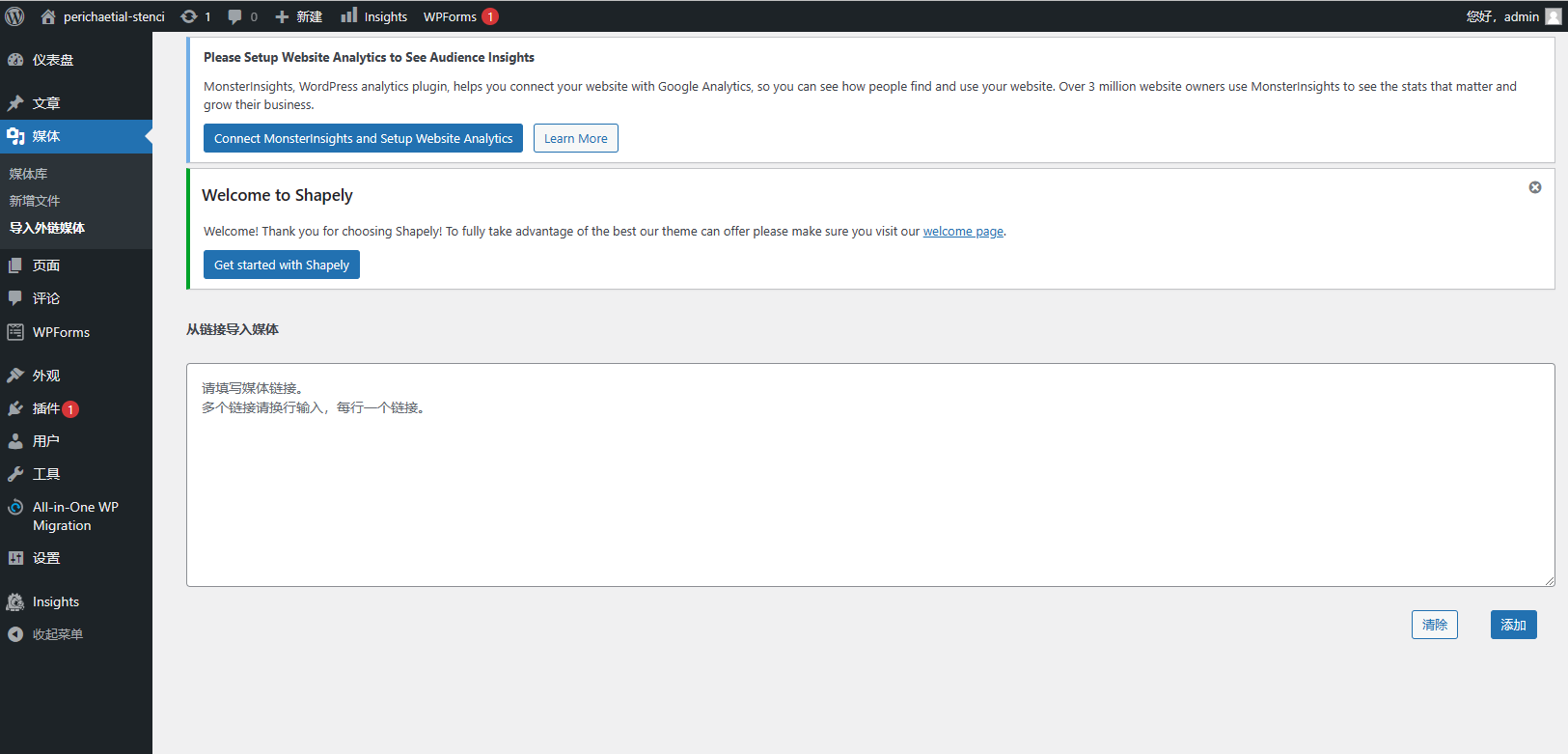
输入要添加到媒体库的外部媒体的URL,然后单击“添加”:
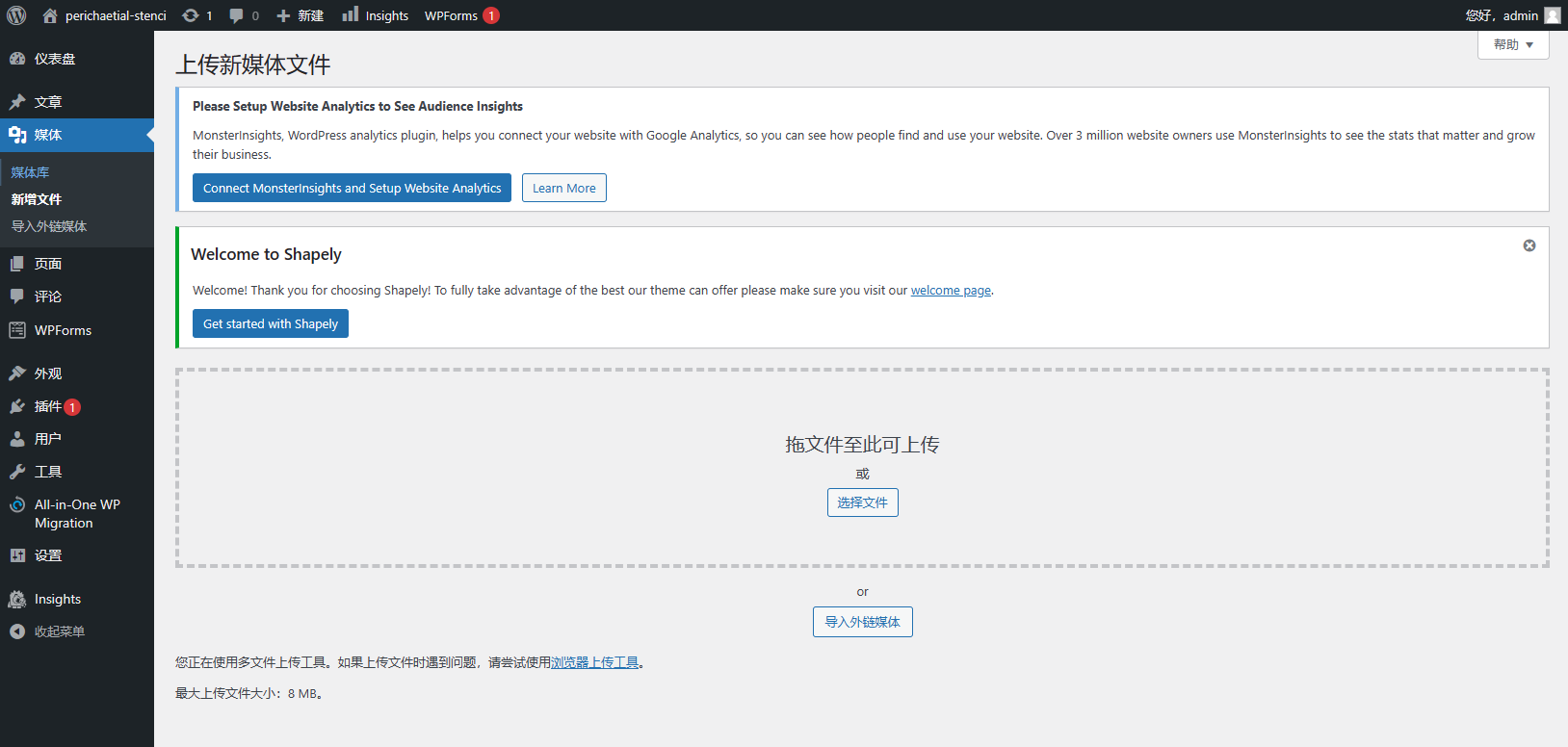
您可以填写多个URL,每个URL填写一行:

您也可以在编辑文章或页面的过程中添加外部媒体,方法是单击“新增媒体”->“上传文件”,然后在上载面板中单击“导入外链媒体”。将出现相同的输入界面。
注意,WordPress需要提前知道图像的宽度和高度,以便在媒体库页面和任何帖子/页面中正确显示图像。在大多数情况下,插件会自动解析这些属性。但在极少数情况下,插件可能无法获得您指定的图像的宽度和高度。在这种情况下,将显示一些输入字段,并允许您手动填写属性。
Version 1.1.2 - 2023.1.12
[GSGundam]
汉化插件。
优化 在 WordPress 6 中的样式。
Version 1.1.2 - 2018.12.2
Fix: external images added in WooCommerce Product gallery disappear when clicking Publish/Update.
Similar issue of other plugins may also by chance be fixed.
Detailed information of this issue:
https://github.com/zzxiang/external-media-without-import/issues/10
https://wordpress.org/support/topic/product-gallery-image-not-working/
Version 1.1.1
Debug warnings are fixed.
Version 1.1
Multiple URL links can be added in batch to the media library, with one URL per line in the text box.
Version 1.0.2.1
Just changed the readme file, the changelog in previous readme file seems not work.
Version 1.0.2
Fixed XSS Security Vulnerabilities and bug with mime types including ‘+’ such as ‘image/svg+xml’.
Thank Mike Vastola.
Click to see detailed information of this bug.
Version 1.0.1
Fixed a bug which causes HTTP 500 - internal server error.
The error occurs in previous version when the plugin fails to get the image size and MIME type. The HTTP 500 error causes the plugin message not correctly displayed in the media upload panel. It also causes the Add External Media without Import page broken.
]]>
最近接触了很多PHP的东西,也学到了很多新的,就想着也利用热乎的知识优化一下基于 Wordpress 的极风游官网。
实际操作过程中,发现其实除了php的知识以外,wordpress也还是有很多自己的东西,而这些东西它不仅仅是一个概念,主要是深入到了主题及插件开发的方方面面。比如题目中的 taxonomy、category 和 term,就让我花了好些时间去理解。记录一下吧。
作为分类法,必须和 Category(分类) 撇清关系。首先它用来对你的数据进行分类并且把他们分组到数据集或子集中。
简单理解,无论系统默认的 Category,还是 Tag(标签) ,都是一种分类法。
当然,我们还可以创建自定义分类法,例如 工单 和 常见问题 ,这给文章提供了独立的分类方式。
Term 其实就是分类法的一个子集,它进一步细分了分类法。
接着分类法的例子,我们可能还会创建 计费问题、 售后问题、 服务问题 等作为 工单 的子类。
Category 是一个Wordpress系统内置分类法,与 Tag 相对应。前者是一个具有层级结构的分类法,而后者是非层级结构的。
那么,根据之前我们说的,这里新建分类,例如 最新 和 精选,实际上就是新建了2个 Term。
来看图说话吧,下图是数据库设计。
分类法和分类项相关内容存储于下面的数据表中:
这些都理解了,那么诸如 register_taxonomy 、get_terms 之类的方法,也就知道什么时候使用了。
其实感觉wordpress还是一直在努力与时俱进的,虽然感觉为了向前兼容真的妥协了很多东西,但是总的来说,仍然不失为一个好用的CMS系统。
]]>
微信审核团队还是挺给力的,只要讲道理,还是很容易过审。
稍微完善了一下,增加 BiliBili热门 的结果展示。
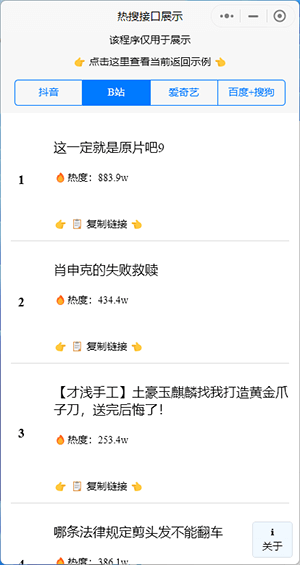
扫码即可体验:

有什么需要完善和增加的,也请告诉我。我也会按自己的设想持续更新。
]]>直入主题,网上的所有内容绝大多数都是抄来抄去,完全不去实践。记得一定要像我一样,在复制了一个电源计划以后,用 powercfg /s 去执行这个得到的 GUID 。

最好用管理员身份运行命令行或者 PowerShell ,以防出现权限问题。然后可以直接看到自己所有电源计划 GUID 的命令是 powercfg -l。
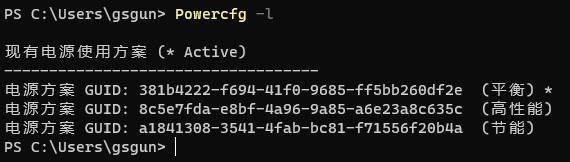
这样就可以参照你自己的 GUID 来运行了,如果 powercfg /s [GUID]不能生效的话,还有一个命令也可以的,powercfg -SETACTIVE [GUID]。
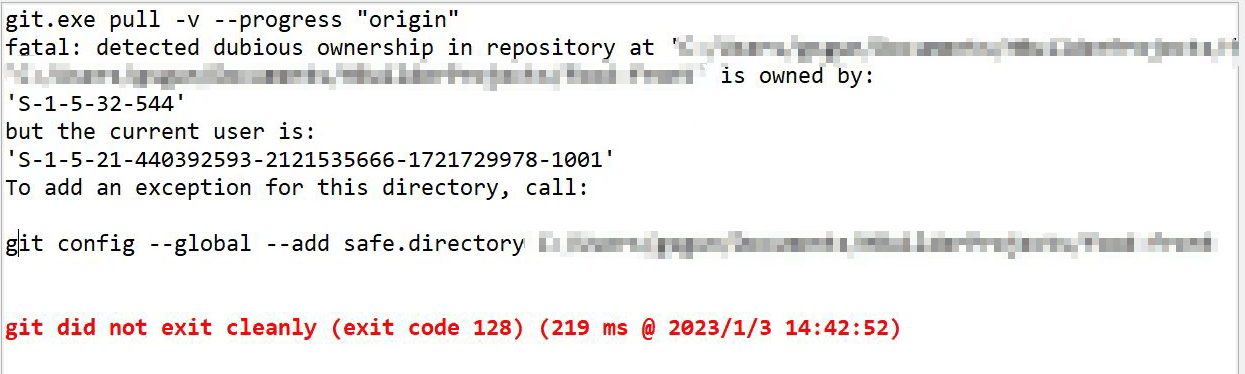
其实提示已经非常明确了,发现可疑目录权限,使用下面的命令排除这个目录:
1 | > git config --global --add safe.directory C:\░░░░░░░░░░░ |
执行了就好了,这个肯定是目录权限的问题,因为这台surface pro只有C盘,而且全部目录都属于管理员。
要以绝后患,还可以执行:
1 | > git config --global --add safe.directory "*"; |
或者干脆在文件夹的属性里面,更改所有者,并应用到所有的子目录和文件。
]]>
凌晨更新了上一篇就睡了,早上起来才发现 GitHub Action 竟然运行失败了。
第一条就算了,存储满了,很明确。但是后面怎么出来几条别的警告?
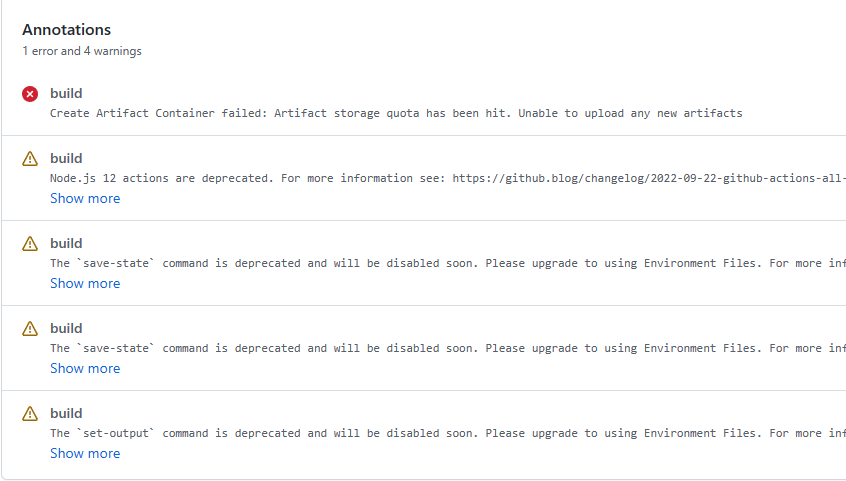
这个提示再明确不过了,输出存储配额满了。
说来一开始我就觉得奇怪,因为在做 GitLab CI/CD 配置的时候,其中就有关于这方面的过期配置,但是 GitHub 却没有。今天查了下,2020年10月14日的时候他们加上了(https://github.com/orgs/community/discussions/25458),所以只要我们在 upload-artifact 部分加上相关配置即可:
1 | - name: Upload artifacts |
当然,因为满了,所以还得把以前的全都删了 🙄 。搜索了下,市场里有一个第三方提供的相关操作(https://github.com/marketplace/actions/remove-artifacts):
1 | name: Remove old artifacts |
此外,还可以在项目设置的 Action 中,找到 Artifact and log retention ,把存储保留的时间调整更短(目前我还没有找到手动删除日志的方法,知道的朋友可以分享一下)。
官方在 upload-artifact 的 issue 中也提到,清除了存储以后,可能计费系统还需要一点时间同步。所以等一等就好了。
原来如此,由于我上次解决 Node.js 高版本报错时(参见《解决Hexo在 Node.js 14 下出现的 Accessing non-existent property ‘xxx’ of module exports inside circular dependency 问题 》),只修改了 GitLab 的 CI/CD 持续集成配置,没有修改 GitHub 这边,所以还在用老版本安全稳当的跑着。
解决方案自然也简单,我修改为了 16.16.0 LTS 版本。
1 | jobs: |
save-state command is deprecated同时警告的还有图中 set-output 这个命令,但是我在 yml 文件里却并没有找到相关内容。那猜想大概就是用到的几个 action 内置操作了吧。
于是把 checkout 、 cache 、 upload-artifact 都从 @v2 改为了 @v3。
似乎一切正常了。
]]>这不,昨天是新年的第一天,起床就在想新年是不是该有点什么新气象?新?要不就看看有什么新鲜事。

好家伙,哪怕只想了解最核心的,也要去几个网站和App才行。那我自己能不能统一到一个地方看呢?要不就做个网站或者小程序吧。做饭的时候一边查资料一边整理思路。本来是打算用爬虫来实现的,这样数据也很可控。但是转念一想,如果有现成api岂不是更快?
结果还真能找到一些,虽然实际上离我的需求还有点距离,但不管怎样,先把东西做出来看有没有用,如果真的可用再快速迭代。
这个阶段没花什么功夫,UniApp 直接就被选中,主要是可用的插件库很丰富,对 ‘node modules’ 的支持也是很不错的。
选择依赖也没花太多时间。之前就在跟李嘉吐槽,有个项目在插件搭配上很糟心,总想着用一些看起来好像很酷炫的东西,但其实背后结构和设计思路一团糟。这次的ui库直接用 uni-ui ,网络库直接用 axios,确保最快最稳的开发出来。
PS:有个小插曲,直接 npm install axios --save 安装最新的版本是跟 uniapp 不兼容的,一定要用 ^0.27.2 版本才行。
其他方面,布局方面用到了 limm-windi-css-uniapp ,图片懒加载用到了 zero-lazy-load。还有一些日期、转换类的js小工具就用的自己以前建起来的私人类库。
先给 axios 安排上适配器和拦截器。
1 | // utils/http.js |
然后再统一管理API:
1 | // utils/api.js |
毕竟是免费api,一方面要考虑高频请求被ban的情况,另一方面也想要避免滥用所带来的问题(我自己很热衷于开放各种免费服务,深知滥用的烦恼),所以需要结合 vuex 和 storage 来解决数据缓存。
1 | // store/index.js |
咱们主要是搞功能,先把东西呈现出来就行了,不搞复杂。
除了图片外,都是 uni-ui 的组件,简单但是高效,好像没什么好讲的。直接上图吧
其实我自己看起来是很难受的,因为好歹也是学过平面设计和网页设计的人。但是为了效率和进度,必须忍住 😂
结果没想到最花时间的是这一步。我以为个人小程序只是不许发布自己加工的信息而已,没想到这种公共接口提供的信息也没法审过。
来回折腾了2次,加上要等审核,时间直接从1月1日来到了1月2日。最后果断放弃个人小程序这条路,直接换公司以前废弃的小程序号来审核试试吧。
其实一开始并没有想到这个东西会有什么大用。但是在快要做完的时候,突然发现这不就是之前学运营课的时候常说要参考的互联网热点吗? 😲 如果真的有用就太好了。个人是特别喜欢做实用的东西。
希望小程序能早点审过,到时候大家帮忙测一测,也看看还可以怎样扩展用途。我也会抽空继续完善。
]]>NumPy 和 Pandas 一直都在入门过程中。总不能一直这样,赶紧抽时间往前推进,也记录一下笔记。整理学习内容是巩固和结构化存储知识的一个非常有用的办法。

PS:文中大量借用了 《A Visual Intro to NumPy and Data Representation》 的图片。这是一篇很好的直观入门教程。但是相信我,最好不要看国内网上到处机翻的这篇文章,要么看原文,要么另找国内大神的教程!切记!!
NumPy是Python中科学计算的基础包。它是一个Python库,提供多维数组对象,各种派生对象(如掩码数组和矩阵),以及用于数组快速操作的各种API,有包括数学、逻辑、形状操作、排序、选择、输入输出、离散傅立叶变换、基本线性代数,基本统计运算和随机模拟等等。
NumPy包的核心是 ndarray 对象。它封装了python原生的同数据类型的 n 维数组,为了保证其性能优良,其中有许多操作都是代码在本地进行编译后执行的。
这里有个习惯,那就是引入 NumPy 所实用的别称:
1 | import numpy as np |
刚才就提到了,数组就是 NumPy 的核心了。使用NumPy提供的这些数组,我们就可以以闪电般的速度执行各种有用的操作。
我们可以通过传递一个 python 列表并使用 np.array() 来创建 NumPy 数组。下面的图片就是简单的示例。

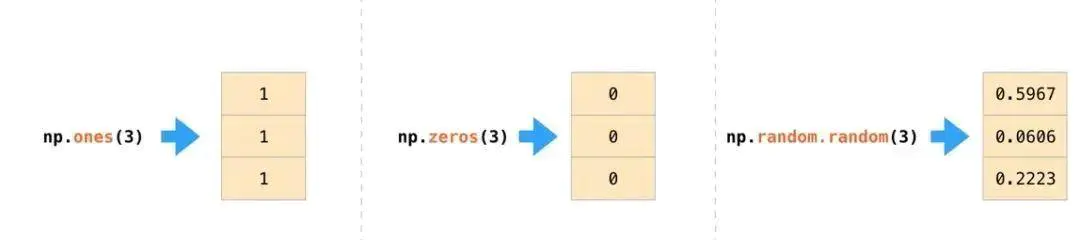
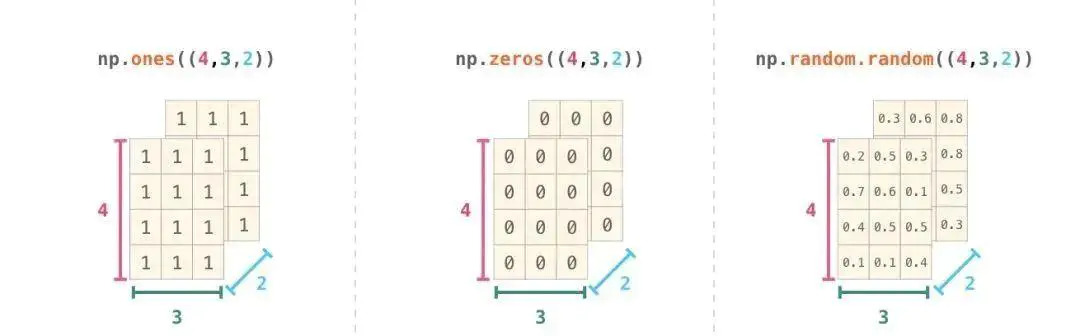
在实际应用中,可能经常会需要初始化数组元素的值,NumPy 很贴心的提供了 ones()、zeros()、random.random() 等方法。这样,我们就只需要传递需要的元素数量即可:
我们使用到 NumPy 了,那就肯定不只是保存数据这么简单,我们需要对数组进行计算。
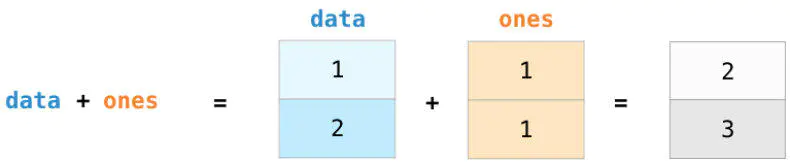
这里我们来定义两个数组 data = np.array([1,2]) 和 ones = op.ones(2) ,然后按元素位置相加,直接输入 data + ones 即可:
同理,不只是加法,减、乘、除都是没有问题,甚至可以像下面 data * 1.6 一样直接很方便的统一运算:

这里引入了 NumPy 的 广播机制,上面的例子中,标量 1.6 被拉伸为张量 [1,2] 的相同尺寸(2,)的向量。标量被拉伸以后的张量尺寸与待运算值完全适配,传递到空缺位进行计算。这个规则在某些地方被称为 “低维有1”,即 数组维度相同,其中有个轴为1 。
但其实个人觉得没有必要这么去理解!
我们可以简单的解释为:广播主要发生在两种情况,一种是两个数组的维数不相等,但是它们的后缘维度的轴长相符,另外一种是有一方的长度为1。再简化一点,两个数组在任意轴上长度或维度(或长度+维度)相等,则可以触发广播。
后面的部分我们再去详细分析。
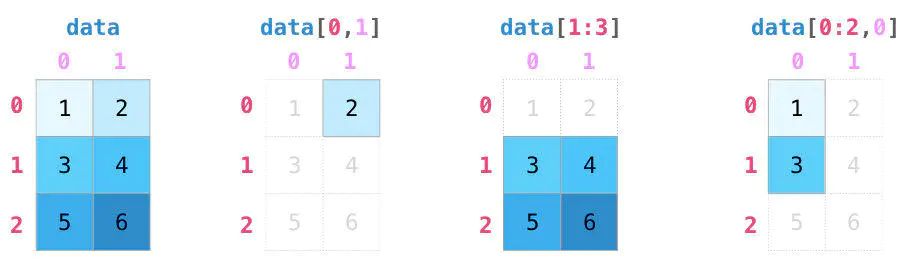
NumPy 的索引应该说非常灵活了,直接上图,非常清晰:

常见的聚合操作 sum、min、max 可以从下图看到运算方式:

当然,NumPy 还支持以下聚合操作:
1 | np.prod(big_array) # 求数组中所有元素的乘积 |
之前一直是从一维数组的角度来初步理解 NumPy 的使用方式,但实际上从二维数组(矩阵)开始,才算是真正有 NumPy 的用武之地。
我们可以使用 np.array([[1,2],[3,4]]) 的方式来创建一个矩阵,也可以使用上个部分提到的 ones()、zeros() 和 random.random() 方法来创建:

如果矩阵尺寸完全一致,那么用算数运算符 加减乘除 来处理自然是不在话下。
但是如果对不同大小的矩阵执行的话,就需要 广播机制 了,比如下面的例子:

这里我们正好可以再深入理解 广播机制 。这里的 ones_row 是二维数组,但是每个维度只有1个元素,那么我们可以理解为: data 和 ones_row 两个数组在维度上相等,可以触发广播。
虽然在这里提点乘方法 dot() ,但是不代表他必须由矩阵使用。在直接上例子说明更好理解:

细心观察,图里特意标红了 3 ,因为该图的作者在强调两个矩阵的临近边必须有相同数量的维度。
简单解析一下点乘的规则。如果我们计算 np.dot(A, B),A为二维m*n的矩阵,B必须为n*l的矩阵,也就是说A有多少列,B就必须有多少行,否则无法运算。下面的图可以简单说明原理:
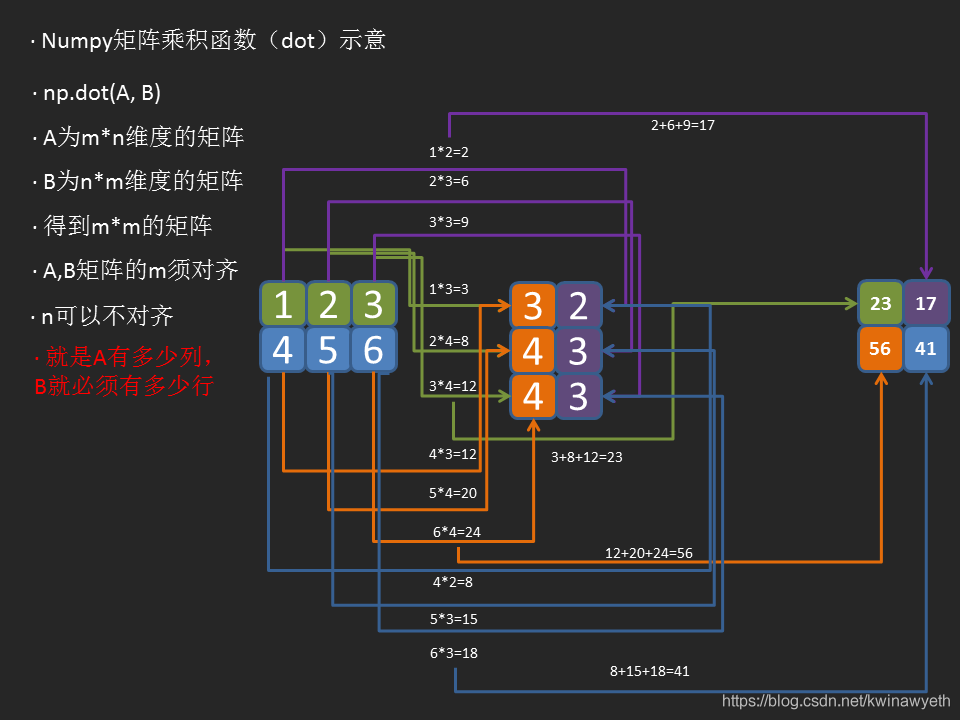
也就是说,可以把开始的那个点乘例子理解为:

矩阵的索引使得我们对数据的操作更加得心应手:
至于聚合,除了之前一维数组提到的基本操作外,我们还可以给出 axis 参数来指定行间、列间的聚合。例如:

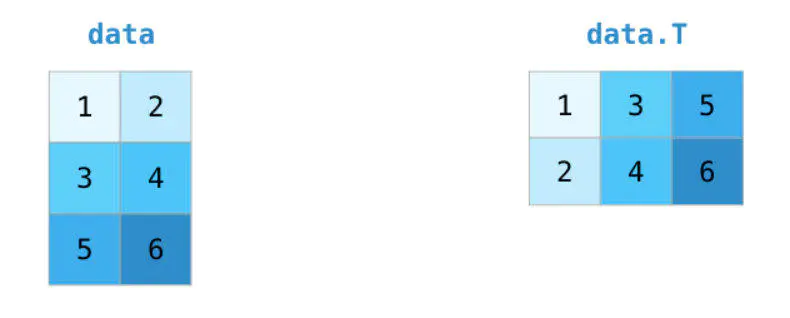
又是两个超实用的方法。首先是旋转矩阵,例如需要对两个矩阵执行点乘运算并对齐它们共享的维度时,我们就可以用方法 T 来执行:
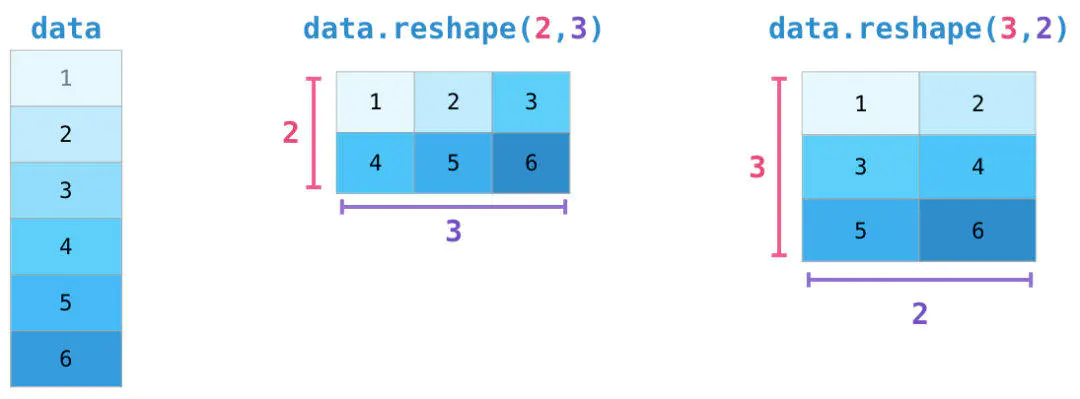
在某些情况下,我们得到的数据(例如问卷采集、爬虫等)并不符合计算模型的要求,这是我们就可以用 reshape() 来重塑这些数据集:
好了,现在可以回到我们一开始提到的 ndarray 对象了, n dimension array ,N维数组。
在 NumPy 中,多加一个维度有时只是多加一个参数的事儿:
其他基础运算无需多提,只是在这里可以特别把三维数组的 广播机制 拿出来强调一下,这样可以加深我们对它的理解。
我们来看这个情况:

这个情况里,(3,4,2) 和 (4,2) 的维度是不相同的,前者为3维,后者为2维。但是它们后缘维度的轴长相同,都为 (4,2) ,所以可以沿着0轴进行广播。
再想象一下其他情况,例如 (4,2,3) 和 (2,3) 是可以计算的,甚至 (4,2,3) 和 (3) 也是可以计算的。只是后者需要在同时两个轴上面进行扩展。
这个部分我还没有学习太多,但是有个初步了解。例如我们可以看到,均方差公式:
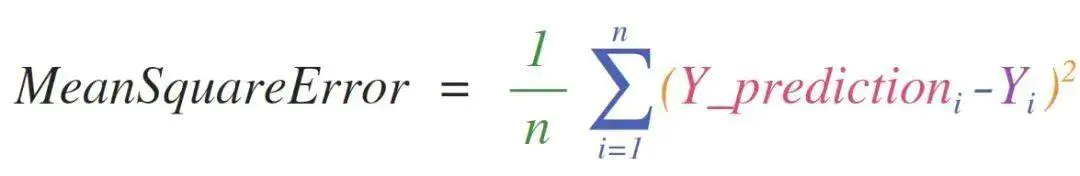
是如何在 NumPy 中实现的:

精彩的就是,NumPy毫不关心 predictions 和 labels 分别有多少个值,只要他们长度对齐,就一定会得出结果。
顺带说下,均方差公式是监督机器学习模型处理回归问题的核心。
其实通过抽象思维,很多现实中的资料、现象都可以数据化,从而进行处理、构建模型。在 NumPy 的学习更深入以后,我会继续学习的 Pandas 也是基于 NumPy 构建的。
表格应该是最好理解的了,因为通常它就是1个或多个二维数组。
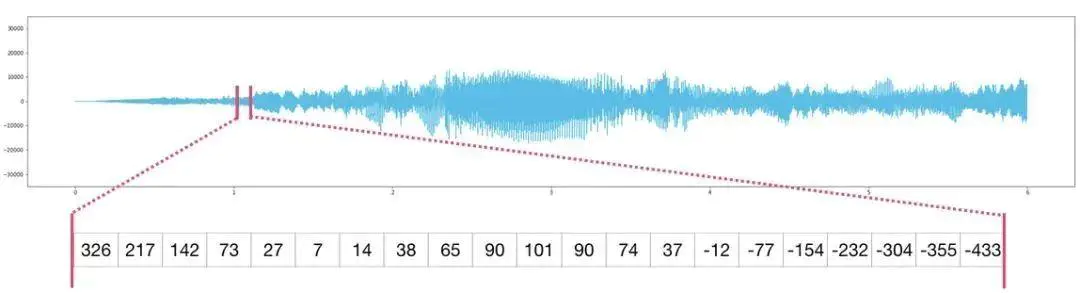
一条音轨可以视为一维数组,每个数字代表音频信号的一部分。例如CD 质量的音频每秒包含 44,100 个样本,每个样本是-65535 到 65536 之间的整数,想要提取音频的第一秒,只需将文件加载到 audio 的 NumPy 数组中,然后获取 audio[:44100]。
图像也是经典的像素矩阵。如果图像是灰度,则每个像素可以使用单个数字表示 0-255 的灰度值,整张图就可以使用二维数组来表达:
如果是彩色图像,那每个像素就需要三个值RGB(如果不考虑透明度的话),那整张图就需要一个三维数组来表达:

这部分挺有意思,虽然我还没有办法实践,但是也花了相当多实践去理解它是如何实现和表达的。
这里有个关键概念 词嵌入(embeddings) 。它是指把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量。
其实最后的数据图相对更难理解,但是我相信通过下图,反而会很好理解:

上图是问卷对于一个人的特征进行表达(参见 《The Illustrated Word2vec》 )。如果能从上图得到一些启发,那么回到我们说的更直观的语言,或者说文学,我们就可以更好的理解了。
首先我们将一段英文按单词拆分为词汇表,然后使用 词汇向量化 转化为 嵌入值(原文是50维词汇向量化)。

这样,就得到了一个基于 词嵌入维度 * 序列长度 的数据表达。别看第一眼觉得好像很抽象,实际上我们平时一致在使用的输入法、智能音箱等等,都在使用相应的自然语言处理相关内容。
emmm…确实没想到只是入个门而已,最后查了无数资料,学了这么久 🤔
多查资料多实践,时刻提醒自己不要妄想妄言。
路还很长,学无止境。
]]>popper 的时候,发现引用地址里分成了 esm、 cjs、 umd 三个路径,我这种半路出家的猿🐒只熟悉 amd 异步模块定义,都不知道这三个是什么。直觉告诉我这里面既然出现了跟 amd 这么相似的 umd,那么跟模块化多少有点关系。赶紧搜索了解学习一下。
学习过程发现最直观的还是看代码。其实几个模式我都用过,只是不知道叫什么,但是只需要看一眼代码,立刻就能找到对应的技术路径分支。
1 | import {foo, bar} from './myLib'; |
对我来说这个形式非常熟悉,因为近几年大量开发 vue、混合app 和 小程序。
个人简单理解:
1、ES 模块是 Javascript 提出的实现一个标准模块系统的方案。
2、具有 CJS 的简单语法和 AMD 的异步。
3、ESM 允许打包器删除不必要的代码,减少代码包可以获得更快的加载。
4、得益于 ES6 的静态模块结构,可以进行 Tree Shaking (例如根据rollup阶段做的标记,进行代码收集,最后生成真正用到的代码,对优化非常友好)。
1 | const doSomething = require('./doSomething.js'); |
显然,我们熟知的 NodeJS 就是使用的 CJS 模式。
个人简单理解:
1、CJS 不能在浏览器中工作。它必须经过转换和打包。
2、在 CJS 中每一个 js 文件都是一个单独的模块。
3、CJS 规范加载模块是同步的,只有加载完成,才能执行后面的操作。
4、所有代码都运行在模块作用域,不会污染全局作用域。
5、模块可以多次加载,但是只会在第一次加载时运行一次,然后运行结果就被缓存了,以后再加载,就直接读取缓存结果。要想让模块再次运行,必须清除缓存。
1 | define(['dep1', 'dep2'], function (dep1, dep2) { |
可能新时代的 Javascripter 不是很熟悉这个模式了,但是作为老人来说,应该是再熟悉不过了,在那个 ESM 还空缺的状态,AMD 简直就是这个领域的救星,例如经典的 RequireJS。
个人简单理解:
1、AMD 允许异步加载模块,并且在加载完成后执行模块的代码。
2、AMD 可以按需加载模块,并且在加载模块时并行执行其他任务,从而提升应用的性能。
3、实现js文件的异步加载,避免网页失去响应;管理模块之间的依赖性,便于代码的编写和维护。
4、AMD 主要作为前端应用,现在已经较少使用。
1 | (function (root, factory) { |
最开始看 UMD 规范的时候,第一感受:这是一坨什么💩。但是自己看了以后发现,这💩好像我还挺熟的。
没错,因为前几个月之前修复一个2018年的链游时,为了服务端(NodeJS)和网站(RequireJS)能公用一些模块,我就干了类似的事情。
个人简单理解:
1、UMD 让模块能在javascript所有运行环境中发挥作用。
2、UMD 最外层是一个自执行函数,这个自执行函数最终可以导出一个模块。
3、它最少包含了适配 AMD 、 CJS 的模块输出。
4、它主要被用于一些第三方库,随着 AMD 应用的逐渐减少,UMD 也会越来越不重要。
其实每个时代都有自己的思想和规范,因为程序入门的时候就走的前端方向,与服务端技术更替的速度相比,前端更是瞬息万变,稍有不注意就会落伍。
曾经跟技术朋友讨论过关于技术迭代的问题,因为不停学习和淘汰也是一件相当耗费精力和时间的事情。但是最后我们还是必须要学起来,有时候更替的不只是技术,更重要的是一种思想。
]]>
大概我自己都时常不记得我本身是个策划,毕竟很多有能力的人都去了大公司,我们这种地方的人就需要身兼数职。大概能用在深入和研究策划设计上的时间,只有程序和美术的1/10不到吧,有点愧对自己的本职工作。
PS:近几年的代码能力真的长进很多,从一开始炜哥给我C++服务器我拿着教程都有点懵杯跑不起来,到现在拿个高级语言看个几天就能开始写东西了。甚至说美术能力都比以前长进了不少,开始理解二次元的画法了。策划其实更是需要大量积累、大量思考才能输出的领域,要更加油才行啊。
周末了,就抽点时间,把这段时间关于随机事件的思考好好总结一下。
万事皆有因。之所以会在这段时间都思考这个东西,是因为现在人员紧缺,但是战舰的设计规模摆在这里,如果砍掉随机事件这个特色的东西,将失去一个重要特色,甚至说游戏本身都不完整了。
好吧,上面说的是我不能放弃随机事件设计的原因。但是不能解释为什么一开始选择了随机事件。显然对于2个人做游戏,就又回到了刚才说到的困境。项目之初我就意识到我们在内容填充上可能存在数量的短板,但是如果内容过少、或补充太慢,游戏肯定是缺乏生命力的。那么这个时候随机事件也同样是一个不错的解决方案。通过各种条件组合到一起的事件(或者也可以称为任务),在有限的时间和素材中,提供了更多可能性。
所以,在项目设计之初,我就十分肯定的采用了大量 Roguelike 元素,不论是 随机性、非线性、还是 复杂性 ,从角色、地图、事件、奖励、全局因素等各方面着手,期待在可控的时间和精力里,创造出一个能让玩家沉浸其中的世界。(当然,很尴尬的是,最后非常不可控 😅 )
其实有这个设计理念并不是一天两天了,也不是一年两年,而是从我还是个少年开始的。因为25年前那个中学生的我,在那个年代接触了一个近两年特别火的游戏设计思路—— 开放世界 。

现在提到开放世界,网游玩家第一个想到的多半是《原神》,主机玩家第一个想到的多半是《塞尔达传说:旷野之息》。其实咱们重庆的本土企业也很热衷于开放世界的,举例就交给诸位看客了😁。而属于我那个年代第一个称得上开放世界的游戏,恐怕得要给《辐射》了。
在前两者推动下,开放世界的概念在当下很多游戏里又被提起,或真或假,或多或少。那到底怎样才算开放世界?
借由知乎的一个名问题我们可以窥见一斑 - 《一个开放世界游戏必须具备哪些东西才能算开放世界游戏?》 。
其中,以下两点是我认为十分重要的内容:
第一、开放世界最基本的要素是玩家在游戏里从某个地点A到某个地点B的移动,其路径应该是不固定的。或者说,对任何一个从某A点移动到某B点的行为,有无数条路线。
第二、开放世界游戏通常会尝试在游戏内按照一些规则建立起一个虚拟的世界。这个世界当中除了玩家角色外,NPC会有他们自己的活动。玩家按照游戏内规则与NPC互动时,NPC会按照规则给出反馈。在理想状况下,游戏内世界可以独立于玩家行为自行运转。
之所以提出来,是因为这两点体现了与传统游戏区别开的决定性因素——非线性设计。
线性故事的优势在于易于设计,叙事清晰,目的明确,也很好烘托剧情和氛围。但这些都是由玩家自身的叙事权利和被动代入为代价的,也就是说,玩家并不是因为自己想要做这件事而做,而是游戏告诉他只能这样做才行。
非线性设计之所以美妙,在于玩家与游戏互动的同时,投入了更多的情感和思考,也就是我们常说的代入感、沉浸感。这种感觉凭借语言是难以准确表达的,就像是你只有身处 《头号玩家》 的世界才能感受到一样。
然而非线性设计也不是完美的存在,无论是 信息不透明、目标不明确、剧情不连贯、还是 逻辑不自洽,任意一点都可以让玩家感到索然无味,毫无游戏动力。
实际上,非线性设计难度极大,以至于我在从业10多年来,自己还没有真正意义上实现过类似的设计。毕竟做设计不难,但是做好设计很难。
所以,我一直以来在思考的,就是如何在这个框框里把非线性设计的优势尽可能的呈现出来,同时,还不会有太多的重复劳动。

回想起来,其实对于开放世界、非线性设计理解的历程,也基本上就是非线性设计思路的深入程度。干脆就顺着这个思路来思考随机事件的设计。
这个应该是最简单的非线性设计了,或者说某种程度上,它应该算是线性设计的变种而已。通过设置不同的选项,得到不同的结果,从而导致另一个事件的发生。
但是假如我们不局限于单向进程,让B任务可以去修改已经完成的A任务的结果,或者说,完成了C任务,就可以再去完成A任务,从而重新选择。这样就开始向非线性设计迈近了一步。
而这确实也是我的项目设计中随机事件的雏形。这个设计有一个后几种设计没有的天然优势,就是可以最大限度维持主线剧情的存在感,叙事依然很清晰。
分支有了,那么是不是可以再进一步。A任务不再是独立的A任务,而是和B、C、D一起组成任务组I。这样的设计,将可能性变得更多,例如 “给任务组I穿插进一些零散的小任务”, “让任务组I和任务组II的选择直接触发E任务”。
这是第二版的设计思路,也是目前正在使用的。事实上,这个设计在测试中已经引起了同事和合作伙伴的好评。它在部分削弱了主线剧情的情况下,提升了游戏世界的代入感,似乎这个虚拟世界真的会发生一些意料之外的事情。
事实上,在这个阶段,我才把 任务系统 改称为 随机事件系统 的。
那为什么不按这个设计继续做下去?因为这个设计量也很大,而且任务之间的穿插很考究合理性,继续往后大量设计,极有可能造成无可挽回的逻辑错误、叙事漏洞。
这个设计与前两个其实并不冲突,它是在这个事件之外设置了一系列玩家不可见的值,通过玩家完成事件所做的一些操作,转化为值的变化,从而引起单个事件或者事件组的变化,甚至可以产生新的事件和结果。
其实已经有相当多的游戏都使用了这个设计,宅如《心跳回忆》,硬如《克苏鲁的呼唤》(常说的SAN值就来自于这里)。也许它本身其实并不是 线性设计 与 非线性设计 的分界线,但是它在 非线性设计 中是可以大放异彩的。
在我的设计中本来是有少量这类全局变量存在的,但实操过程中发现其实很难控制,特别是对于一款没有具体结局的中大型网络游戏,设计的不好就意味着它可有可无,鸡肋一般的存在。因此目前已经废弃。
好吧,这下来到了真正意义上的非线性设计了。在这个设计下面,如果能跳出游戏本身来看,主线剧情看起来其实更像是被硬加进去。因为在这种方式中,设计重点变成了用户如何与NPC、环境来进行交互。换句话说,玩家与它们交互时,它们应该展现出什么样的特点,在什么样的情况下,提供什么样的任务、什么样的选项。
是的,你其实完全可以把这种设计用程序思维表达出来,那就是 面向对象 。
在这个设计中,玩家有足够的自由度,玩家有机会通过行动、思考、表达来书写自己的“异世界故事”。
但是想象一下,假如你迷失在一个这样的世界中不知道该做什么,不知道可以做什么,甚至你做的事情在这个世界里也没有什么影响力,没有情节、没有故事……嗯,这简直是一场世纪灾难。
如果是一个有结局的游戏,那么沙盒游戏多多少少都还维持住自己的游戏性。但是对于一款开放式网游来说,如果不硬加入一条主线剧情,基本上就是应了 沙盒设计 里的 “沙” 字,真是一盘散沙。
这也是我一开始并没有选择这个方向的理由。既要设计众多的交互因子(属性和内容等等一大堆配置),又要设计一条主线剧情,这个设计量实在不是我等小民可以承受的。或者说我一个人可以承受的。
那么,我所寻找的出路在哪里?其实方向已经有了,那就是将游戏交互全面规则化、属性化。
在这个前提下,主线的实现也变成了规则,通过制定世界的规则、阵营的规则、环境的规则,来实现主线的推进。
如何实现?
之前的思路是GPT通过规则来理解世界结构和局部情况,从来构建剧情大纲,确定详细目标(这块表现得并不好)。然后设定各种障碍和目标后,通过强化学习,最终将生成好的特定事件,落实到各个随机生成的有特定属性的NPC或者地点上。
现在正尝试把一些本来期望用AI来实现的内容(特别是剧情大纲),转由传统的代码逻辑实现。
但是具体怎么做?一方面可能是想保密吧,但是另一方面来说,我本来也还在验证阶段,还真的就是只有四个字可说,“无可奉告” 😋 。期待可以早点实现早点面市吧,我们自己也等得太久了。
]]>
最近几个月把所有项目都迁过来 VS Code 了(除了因为Unity调试问题反而用回了 Visual Studio),PHP也就抛弃了最强的 PhpStorm 。
这段时间抽空在帮朋友处理PHP项目,然而从来没有用过PHP调试功能的我,突然发现一个项目的bug,但是却怎么也打印不出东西,并且又不抛出错误。这就很离谱。于是乎,又开始填补自己的知识盲区,咱也要用上PHP的调试功能。
我使用的是WNMP环境,web服务器是 Nginx ,Apache 环境也是一样的流程。
使用默认版本的PHP就相当简单了,直接打开 XDebug调试组件 即可。
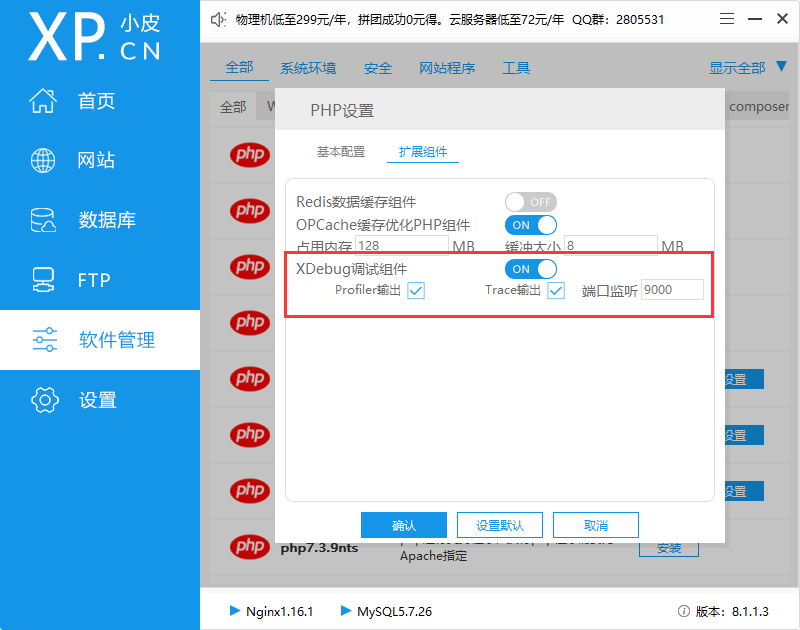
配置好了就可以跳过下面的部分,直接去看 配置 VS Code 。
要不说我这个人做东西怎么慢呢,因为经常想要知道 为什么 和 别的方法。所以我并没有使用默认的PHP版本,而是顺便想要更新到PHP 7.x的最新版。
先到官方网站下载最新的 PHP 7.4.33 - https://windows.php.net/download,我使用的是 nts 版本。下载完成以后放到 phpstudy 的相应目录下,例如 X:\path\to\phpstudy_pro\Extensions\php 。文件夹名称修改为相同规则,例如 php-7.4.33nts 。
刚才下载的包里是不包含 XDebug 插件的,我们需要自己去下载和配置。
XDebug 官方网站有个非常贴心的功能,就是将本地 php_info 输出的信息,粘贴到输入框后,可以帮你分析出要下载的版本,并给出下载地址。到网址 https://xdebug.org/wizard 输入,然后点击 Analyse my phpinfo() output 按钮即可。
把下载好的dll插件拷贝到刚才 php-7.4.33nts\ext 目录中,然后在 php.ini 中加上以下信息(直接加在最末尾即可,确保是在 OPCache 配置的后面):
1 | [XDebug] |
记得把 zend_extension 的值改为你插件实际所在的路径和实际的名称。
首先重启web服务器(无论 Nginx 还是 Apache),然后用 phpinfo() 打印PHP信息,看是否有 XDebug 插件。
确保 VSCode 中已经下载 PHP Debug 插件。可以搜索下载,也可以点击这里跳转后下载 - https://marketplace.visualstudio.com/items?itemName=xdebug.php-debug 。
打开 文件->首选项->设置 , 在配置中添加如下内容:
1 | "php.validate.executablePath": "D:/phpstudy_pro/Extensions/php/php-7.4.33nts/php.exe" |
最后直接点击 运行和调试 按钮,在创建的 launch.json 里添加一个配置,或者找到已存在的配置来修改:
1 | { |
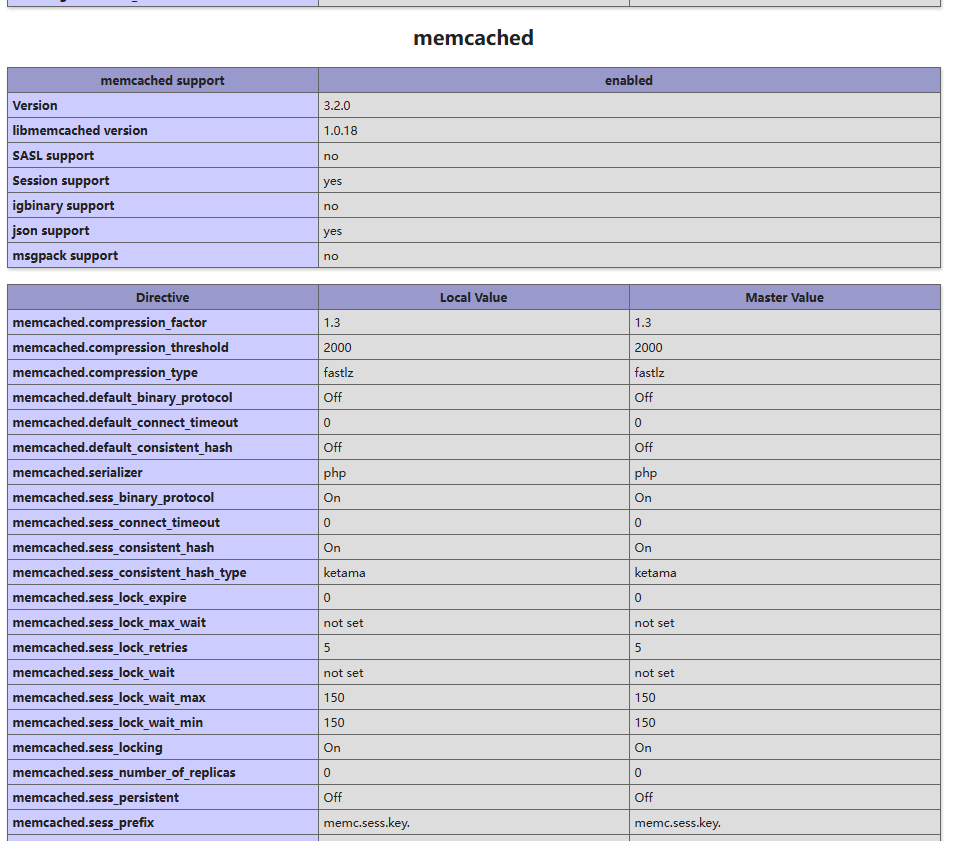
老规矩,我在 二机联盟-知识星球 存了一份我自己配置好的 php7.4.33nts ,只需要修改一下 XDebug dll插件路径即可。同时这个包也配置好了 Memcached ,如果服务器没有安装,或者不需要启用,注释掉相关内容即可。
打开调试,一切豁然开朗,还顺手解决了原有框架的一个问题,舒坦 😏
]]>
自从更新到 Windows11 以后,就一直在使用各种工具修改开始菜单,不然实在很难习惯放在中间的开始菜单。最后选择了 StartAllBack ,倒不是它多优秀,主要是占用少,速度快,功能够用。
PS:到目前为止我都不习惯macOS底部的快捷栏,顶部倒是很习惯,我猜想应该是因为鼠标随便一晃就能到最角落,然后这样向目标寻路的时候比较精准方便😀
这次是我自己手贱把 Windows 升级了 2022H2 新版本,然后就出现了开始菜单一直闪烁的问题。上网大概一搜,并没有太多类似的情况可以查到。按推理来说,最有可能的就是管理着资源管理器的 StartAllBack 了。(而且我还想到之前资源管理器之前经常出现高占用,是不是也是它的问题?)
废话少说,直接更新呗。于是直接上最新的 3.5.6 版。
果真不再闪烁,使用了2天也没有出现资源管理器高占用卡顿的问题。👍
最后建议大家购买正版,淘宝京东都有,随便一搜一大把,25-29都可以保证买到正版,20以下的就不好说了。
当然,这里也提供一个体验通道:果核剥壳。
同时,我也在 二机联盟-知识星球 存了一份。
]]>
PHP开发不是我最擅长的服务端语言,但是因为接触WordPress很早,了解到一个叫做 WPJam - https://blog.wpjam.com/article/wordpress-memcached/ 的插件,后来他更新了一个支持Memcached的功能,从而使我了解到除了常用的 Redis、MongoDB 以外,还有 Memcache 和 Memcached 这样两个先辈。
PS:说得好像我其他语言开发服务端就很厉害,其实只是基于对javascript和python的熟悉程度,所以用 NodeJS 和 Python 两种开发更快。
说回来主角 Memcached ,其实在熟悉了以后,我就经常使用他作为一些小型项目的高速缓存系统。它的优势在于配置十分迅速,使用起来与 MongoDB 无异,开发效率极高,同时也能够应对小型项目的压力。
由于我同时要兼任 策划、美术、开发 多个职务,本地环境一直都是Windows,但对windows服务器环境不熟悉,导致了 Memcached 始终不能正常运行。最近帮朋友处理一个项目,考虑到后续如果有人接手,恐怕还是 PHP 最快最容易找到人,所以把解决 Memcached 如何在Windows WNMP环境下跑起来又提上了日程。
PS2:继续吐槽度娘的技术文章搜索功能,80%的结果都帮不上忙,还有20%连边都不沾。最后还是靠谷哥出面解决了问题。可长点心吧。
文章里所有的文件我都尽可能提供了下载地址,同时也在 二机联盟-知识星球 存了一份。
Memcache 是一个原生版本,完全是在 PHP 框架内开发的,支持 面向对象 和 面向过程 两套接口并存,而 Memcached 是建立在 libmemcached 的基础上的,只支持 面向对象 接口。这就意味着在安装 Memcache 扩展的时候不要求安装其他的东西,但是在安装 Memcached 的时候会要求你安装 libmemcached。
Memcached 支持 Binary Protocol,而 Memcache 不支持,这意味着 Memcached 会有更高的性能。
网上90%的文章都是打着 Memcached 的旗号在讲 Memcache ,真的是浪费大家时间。
其实我很早就安装并测试好了 memcached 服务,再回顾一下。
我只用到了1.4.4版本,因为1.4.5开始就不能作为服务来启动了。而我本来就是测试用途,没有必要搞那么麻烦。
下载地址:
64位系统 1.4.4版本:http://static.runoob.com/download/memcached-win64-1.4.4-14.zip
32位系统 1.4.4版本:http://static.runoob.com/download/memcached-win32-1.4.4-14.zip
解压出来,推荐放到系统盘以外,免得什么时候重装或者恢复了系统又要重新下载。
管理员身份打开cmd,cd 到 memcached.exe 所在目录。
执行命令:
1 | > memcached.exe -d install |
其他相关命令可以用 -h 参数来查看。
1 | > memcached.exe -h |
使用 telnet 来查看 memcached 是否正常运作。首先确保已经安装了 telnet 客户端,没有安装的到 打开或关闭 Windows 功能 里安装即可。输入 telnet 命令后,先回车一个,出现了 Error 再输入 stats 命令。
1 | >telnet 127.0.0.1 11211 |
这样就是跑起来了。
当然也可以到 windows 的服务面板里查看 memcached 服务是否运行,或者在任务管理器面板里查看服务标签。
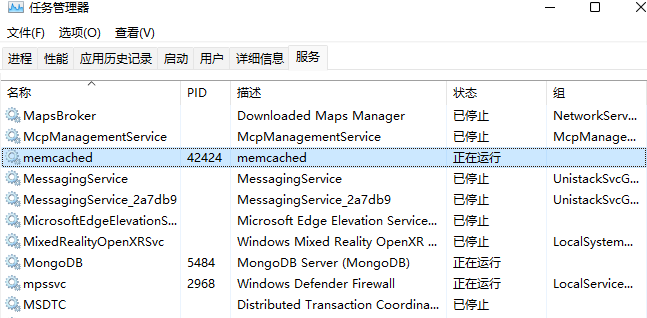
我使用的是 PhpStudy 的 WNMP 集成环境。PHP版本为7.4,x64位架构,非线程安全。
废话不多说,两种方式下载:
GitHub下载:https://github.com/nono303/PHP-memcache-dll
PECL官网:https://pecl.php.net/package/memcached/3.2.0/windows
这里特别要注意版本问题,要完全对上运行环境才行。
下载以后,将 php_memcached.dll 放到 DISK:\your\path\to\php\ext 目录下,将 libmemcached.dll 放到 C:\Windows 目录下。
这个就简单了,在所用的php版本的 php.ini 文档末尾加入 extension=php_memcached.dll 即可。
phpinfo() 查看状态:
当然,也可以写代码来检测:
1 |
|
清理缓存:
1 | telnet localhost 11211 |
Photoshop、Word、Excel 之类的,天天听Intel NUC起飞是真难受。所以最近大部分开发都转战了VS Code。(但是有一说一,JetBrains 的东西实在太强大了,好用至极,每款都是。缺点是资源占用也确实严重。)转战之路却并不顺畅,比如 git 就只能commit到本地,无法push到 github 仓库,出现以下提示。

这点很奇怪,因为托管在公司服务器上的git仓库,在 VS Code 里是可以正常 push 和 pull 的。
习惯性地先打开了百度,然后得到了一堆莫名其妙的结果。真的醉了,对度娘只能送上《服气》两个字。同样的搜索词在google里轻易得到了解决方案。
首先测试一下跟github的通讯是否正常。
1 | > ssh -T -p 443 git@ssh.github.com |
嗯……不只是通讯正常,连授权都ok。但是再试一次push,仍然得到了之前那个错误。通过搜索到的结果,得知实际上我们只要在 C:\Users\[your username]\.ssh\ 目录里新增一个 config 文件就可以了。文件的内容如下。
1 | Host github.com |
再尝试一下,恢复正常了。
]]>
修复博客问题的时候,发现加载 Live2D 的模型报了一堆错误。仔细看,是由于看板娘的动作文件出错了,而且居然是大小写的问题,想必windows服务器就不会出现这个问题,所以模型的作者并没有发现。
既然都在批量修复问题了,那把这个问题一并处理掉吧。
本来想着应该是个很快的过程,找到问题所在,如果可以修复,我也想继续使用这个模型。或者不可以,那我就换个模型继续用。
但是访问 hexo-helper-live2d - https://github.com/EYHN/hexo-helper-live2d 时,顶部黄条让我心头一颤,接着在 Readme 看到一条让人遗憾的说明。
1 | This repository has been archived by the owner before Nov 9, 2022. It is now read-only. |
emmm……看最近更新确实都是3年前了。于是循着他的推荐,我去访问了 Live2D Widget - https://github.com/stevenjoezhang/live2d-widget 这个项目。
该项目并不是hexo的特有插件,所以看起来自定义集成会比之前的插件略微麻烦。当然,如果只需要最基本的功能,则比之前还简单。只用将下面这一行代码加入 html 页面的 head 或 body 中,即可加载看板娘:
1 | <script src="https://fastly.jsdelivr.net/gh/stevenjoezhang/live2d-widget@latest/autoload.js"></script> |
我以上方式尝试了一下,得到了下图的结果。

然而,我希望博客上的看板娘插件能干干净净的,不说废话,不用换人换装,更不用各种乱七八糟的功能。很明显这并不是我想要的。
略微纠结了一会要不要换回以前的插件,然后打定主意还是要更换为新的,毕竟有维护更新还是更有保障一些。
对于线上托管版本,其实项目已经提供了一些可选配置。项目中的 autoload.js 文件也大致都列出来了可选配置。autoload.js 会自动加载三个文件:waifu.css,live2d.min.js 和 waifu-tips.js。waifu-tips.js 会创建 initWidget 函数,这就是加载看板娘的主函数。initWidget 函数接收一个 Object 类型的参数,作为看板娘的配置。
| 选项 | 类型 | 默认值 | 说明 |
|---|---|---|---|
waifuPath | string | https://fastly.jsdelivr.net/gh/stevenjoezhang/live2d-widget@latest/waifu-tips.json | 看板娘资源路径,可自行修改 |
apiPath | string | https://live2d.fghrsh.net/api/ | API 路径,可选参数 |
cdnPath | string | https://fastly.jsdelivr.net/gh/fghrsh/live2d_api/ | CDN 路径,可选参数 |
tools | string[] | 见 autoload.js | 加载的小工具按钮,可选参数 |
这些配置确实能够解决不要显示小工具的问题,但是自己说话的问题(原来的文本实在是太那个了,都不敢让我孩子看见),以及指定角色和服装,在这里并不能解决。
于是我还是走上了进阶道路——自定义配置。
首先当然是把项目克隆到本地:
1 | git clone https://github.com/stevenjoezhang/live2d-widget.git |
直接把整个目录复制到source文件夹下面就可以。依赖就不用安装了,毕竟我是要在自己的Hexo博客里运行。
试试引入
1 | <script src="https://your.site.com/path/to/live2d-widget/autoload.js"></script> |
部署运行没有问题,那么剩下就是真正的自定义阶段了。
要干活首先得安排好要干什么活儿,所以先分析一波它的demo,其中一个是基础例子,不管它,我们来看另外一个 login.html。
1 | live2d-widget |
上面的树形图我把不重要的文件都隐藏了,重要的都留下来了。这就是今天的主角们。
感觉废话也不用多说,直接来看我要干什么。
调用 insertAdjacentHTML 方法来插入一个固定在左下角的画布。
1 | document.body.insertAdjacentHTML("beforeend", `<div id="waifu" style="position:fixed;left:20px; bottom:0;z-index:2;"> |
分析Demo我们可以知道,它通过api的方式获得参数,然后传参来创建模型。
那么先来构造一个初始化配置的方法。
1 | function initConfig(config){ |
这里我参考原作者允许了 api 和 cdn 两种获取配置的方式,由传入参数来确定到底用哪种。接下来就调用这个方法初始化我们的配置参数。
1 | const config = initConfig({ |
因为配置保留了 api 和 cdn 两种方式,所以实现加载的时候,也同时考虑这两种方式。
但是通过分析cdn的文件,我们可以知道,要获取模型参数跟api方式是不一样的。api可以使用url传参的方式直接获取到对应模型,而api也会有自己的容错处理。但cdn就需要我们通过自己的方式来处理了。所以我们还构造了 modelSelection 这个方法。
1 | async function loadModel(modelId, modelTexturesId, config) { |
我希望屏幕尺寸太小时不要显示看板娘,但是又不希望pc上改变浏览器尺寸会导致直接不加载,所以用css样式来实现。修改 waifu.css 。
1 | @media (max-width: 768px) { |
另外,我也不希望鼠标移上去会浮动。
1 | #waifu { |
最后,记得把尺寸改成跟你的画布同样大小。
1 | #live2d { |
最后,在页面加载完成后执行加载代码就可以了。
其中的模型ID和材质ID可以通过这个页面去查找,https://github.com/Akilarlxh/live2d_api/blob/master/model_list.json。
1 | window.addEventListener("load", () => { |
锵锵,完成。

其实总体来说还是挺简单的,主要是读懂代码,看看原作者的方法都在做什么就行了。
思路 > 方法 > 实现。
收工。
]]>自己确实经常都没有习惯加 www 前缀,而且相信也有不少人跟我一样。所以肯定是有必要处理相关问题的,毕竟当年做极风游官网的SEO的时候,为了搜索引擎能够更好的识别,只记住唯一域名,也是进行了跳转。极风游官网是基于域名解析的301重定向,而因为今天的测试环境是阿里云虚拟主机,所以需要用到.htaccess。
这里需要特别注意,.htaccess 文件仅适用于 Apache 服务器,不适用于 Nginx 类服务器。
把下面内容写入到 .htaccess 文件,然后放到服务器根目录即可。
如果是重定向到带www的域名:
1 | RewriteEngine On |
如果是重定向到顶级域名:
1 | RewriteEngine On |
都说到这里了,不如就也说一下怎么处理Nginx的重定向。其实在Nginx的应用中,重定向是极其常见的,熟悉的朋友应该一点即通。直接在配置文件里加上下面内容即可。
如果是重定向到带www的域名:
1 | server { |
如果是重定向到顶级域名:
1 | server { |
上网查了下,百度分享不支持https由来已久,而且不只是百度分享,还有一些古早的百度托管的代码,都是属于死活不放到https链接里的。
解决办法倒也简单,把相关文件下载回来自己托管,修改Hexo模板的链接地址即可。
1 | window._bd_share_config={ |
需要注意的是,一定要将 static 文件夹放到根目录,因为它其中的文件依赖是写死的,要改的话得改一堆,特麻烦。
压缩包在网上可以直接搜索到。我也在 二机联盟-知识星球 存了一份。
]]>F12让我发现了很多报错,最神奇的是居然报了 av-min.js 找不到,以及 $(...).fancybox is not a function 这两个错误。
这就很意外了,因为最近除了增加阅读更多的功能,Hexo博客本身我是几乎没有做改动的。但是我也不确定是什么时候出现的问题,所以第一想法是希望能找到有关的修改。
通过查询git日志,也没有什么有价值的线索。只能开始转向别的线路,看试错+分析能不能奏效。
期间测试了如果用 RequireJS 来处理加载的依赖,会不会容易找到问题所在。但实际情况是,处理到一半,发现改动的地方实在太多,工作量性价比太低了,最后放弃引入requirejs。但这一尝试却让我意外地确定了引入CDN托管的 fancybox v3.5.7 是真的可以正常加载。
那么接下来就是换掉原来本地引用的fancybox库,并修改相关的运行代码,测试一下是否正常工作。
CDN地址,来自BootCDN:
1 | <link href="https://cdn.bootcdn.net/ajax/libs/fancybox/3.5.7/jquery.fancybox.min.css" rel="stylesheet"> |
然后我自己的主题没有在渲染的时候添加标签,是使用js后处理的图片弹出框。于是去掉了早期版本所使用的js调用,而是给标签加上 data-fancybox 属性。
1 | $(this).find('.fancybox').each(function(){ |
测试一切正常,Next。
第一次真正使用 RequireJS 是在王老师团队里做区块链应用前端时,因为当时太懒不想学vue(说实在的,也是因为学了AngularJS以后,面目全非的2.0出来让我对这些迭代太快的新物种有所畏惧),就退而求其次,在原生js技术上引入一些小东西来构建自己更能把控的框架。而其中用来解决引用依赖的问题,就是 RequireJS 了。
RequireJS 依赖于一个重要的概念,AMD。对于浏览器,同步加载是一个大问题,因为模块都放在服务器端,等待时间取决于网速的快慢,可能要等很长时间,浏览器处于”假死”状态。因此,浏览器端的模块,不能采用”同步加载”(synchronous),只能采用”异步加载”(asynchronous)。这就是AMD(Asynchronous Module Definition)规范诞生的背景。
require.js在加载的时候会检查data-main属性,当RequireJS自身加载执行后,就会再次异步加载data-main属性指向的main.js。这个main.js是当前网页所有逻辑的入口,理想情况下,整个网页只需要这一个script标记,利用RequireJS加载依赖的其它文件。
1 | <script data-main="scripts/main" src="js/require.js"></script> |
我比较惯于使用 require.config 进行统一配置,这样方便管理。
1 | // main.js |
有一些依赖于jQuery的插件本身是不符合AMD规范的,而shim配置就可以用来加载这些非规范的模块。例如:
1 | require.config({ |
通过插件的支持,requirejs还可以做到一些其他的事情,例如加载文本类文件:
1 | require(["some/module", "text!some/index.html", "text!some/style.css"], |
当然,最后我并没有用到 RequireJS。我的主题是依赖于 Jacman 大改的,而它又是依赖于早期的 Pacman 主题,除了模板十分零碎以外,脚本也按功能拆成很独立的文件,使得按requirejs加载的方式来处理会很麻烦。
刚看到报了 av-min.js 找不到的时候,我完全是懵的。因为实在不记得为什么会引用了 av-min.js 这个文件。当然,简单搜索项目,我就知道原来这是 Valine 所用到的 LeanCloud 基础库。
Valine 是一款基于 LeanCloud 的快速、简洁且高效的无后端评论系统。搭建方便,无需梯子,而且小用量免费,实在是Hexo博客的不二之选。
如果没记错,10月份我还收到一条评论的邮件,但是此后就没有了。搜索了一下,是因为LeanCloud资源托管的域名和路径规则都变了,所以按理说引用这个新地址就可以了:
https://unpkg.com/leancloud-storage@4.12.2/dist/av-live-query-min.js
但是以防万一,我还是将文件下载下来,和Valine的文件一起放到了本地。网上可以直接搜索到,或者通过上面这个地址下载。我也在 二机联盟-知识星球 存了一份。
当然,清理了一下,发现还有很多代码和引用都没用了,该删的都删了,他们都有可能拖慢访问速度。
例如,disqus(墙外无法访问)、duoshuo(已经倒了)、Baidu Image Plus(已经下线)、Baidu Share(后来处理了一下,能用了,下一篇博文说)、Live2D widget(修复了一下,不然很多报错,也没有再使用hexo的配套插件,下下篇博文讲)。
最后看着干净的控制台输出和网络请求,终于安心了🧐
]]>感觉还挺好用,整合起来也很方便,就来和大家分享一下。现在就可以向下滚动,看文章是不是已经被隐藏了一半? 😄
简单来说,这个工具的主要功能是通过隐藏文章的部分内容,引导用户关注微信公众号,在回复相关关键词之后,可以获取解锁链接,用来把当前用户从网站引流到公众号。
先去这个地址注册账号:http://admin.openwrite.cn/。
然后到这里登录:https://readmore.openwrite.cn/login。
我猜之所以会分成两个地址,大概率是之前没有考虑到会开发更多功能 😏
接着到 配置页面 ,选择 添加。
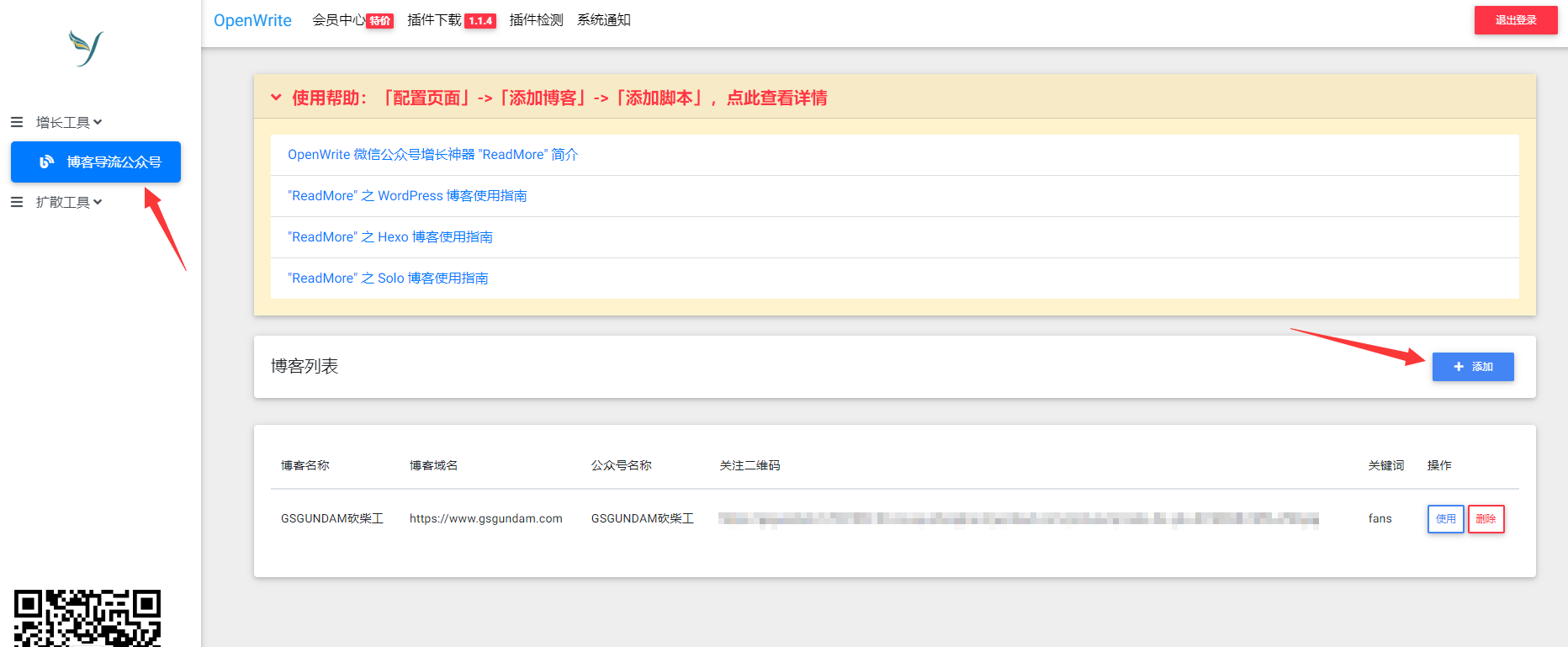
填写完内容以后,就会出现使用指南,根据指南分别到 微信公众号 和 Hexo博客 进行设置即可。
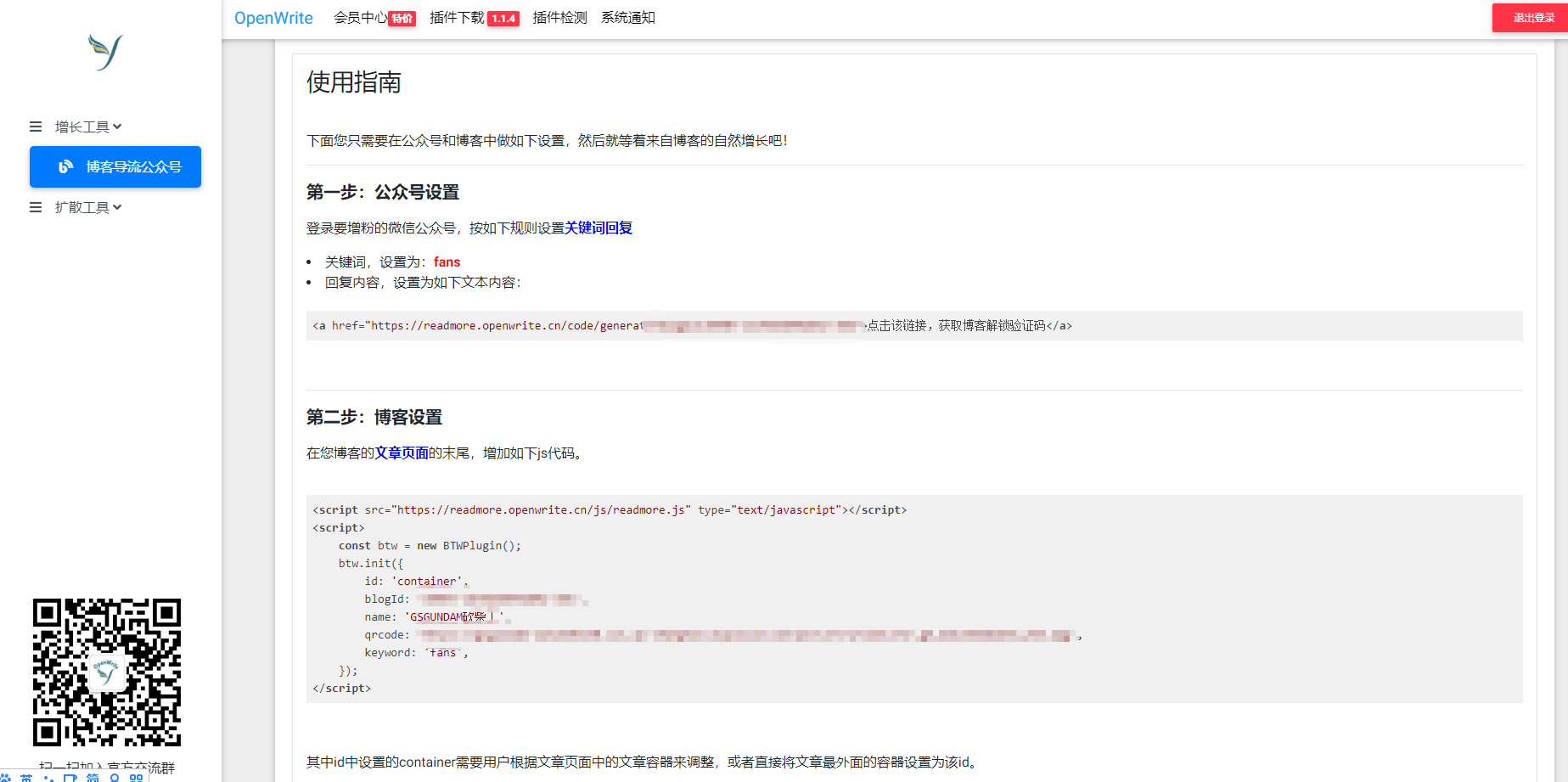
注意,在博客设置的代码中,id部分后面一定要根据自己的主题进行修改,下一个部分我也会提及。
相信会看这篇文章的人,也大都在自己玩公众号了,怎么设置公众号的自动回复恐怕不用我多说。所以接下来看Hexo的配置。
哦,我忘了,人家没有插件(皮一下😛)。
其实他家已经做得很方便了,只需要引入一个js,然后选用或者设置一个要隐藏容器的id就可以。
看官们留意一下,根据主题不同,要修改的模板类型也不同。我这里是ejs模板引擎,如果你使用的是 NEXT 一类的主题,那就应该是swig模板引擎,需要在 themes/next/layout 目录里找到 _layout.swig
1 | <main id="main" class="main"> |
这段代码中,id="content" 就是我们的目标。然后在footer.swig一类的地方加入OpenWrite提供的js代码即可。
再例如我自己的Hexo主题里,就是ejs引擎,找到article.ejs,给 <div class="article-content"></div> 加上 id="article-body"。然后在末尾加上js代码。
不过我这里特殊处理了一下,因为我的大部分博文肯定是不会去隐藏内容的。所以我需要一个判断。
1 | <% if (item.readmore) { %> |
也就是我在文章markdown文件的题头里加入 readmore: true 以后,才会隐藏内容。

我们先来回顾一下目录结构:
1 | │ AxieAccessControl.sol |
上次把erc721目录基本都讲到了,这也是最核心的部分。上一部分都了解了以后,基本的erc721结构已经清晰了。本来这次是打算先从权限部分来分析,但是出于我心理学专业的本能,我想如果是自己第一次看这个系列,现在更希望看到什么。我猜自己会希望更快的能发布我的NFT,所以这次我们直接先分析最核心文件AxieCore.sol 文件链接:AxieCore.sol。
关于头部引入的的 AxieERC721.sol ,我们在上一篇已经讲过了,其作为核心依赖的合约,管理了基础数据(即直译过来的基础可枚举)和扩展属性(即直译过来的元数据)。我们现在更关心的是,Core这个合约它在这个基础上实现了什么功能。
我们来看第一部分:
1 | // solium-disable-next-line no-empty-blocks |
有时候真是要感谢代码和命名规范,我们可以很清楚的看到,这个代码在一开始就声明了一个名为 Axie 的结构,它包含了一个256长度Int的基因密钥和一个256长度的出生标记。紧接着就声明了一个axies数组,想必是用来存放生成的axie。我们现在可以猜测,这个合约很可能是在制定一只Axie的生命周期和规则,然后把他们存起来。
下一部分就真正切入主题:
1 | event AxieSpawned(uint256 indexed _axieId, address indexed _owner, uint256 _genes); |
我省略了不少地方,因为相较而言,我认为这里能够理解,接下来的东西也很好理解。这里更多的是去思考它为什么要做这种设计。这里我们重点放在事件和方法的关联上。可以看到第一个事件就是产卵 event AxieSpawned (可以理解成生成,但是这里理解成产卵更合适),我们往后看,它是通过 _spawnAxie 这个方法触发的。这个方法需要一个基因密钥和一个所有者地址,从而构造生成(铸造)一只axie,并把其id通过 AxieSpawned 事件广播出来。
当然, _spawnAxie 是个private私有方法,而有个专门供external外部调用的 spawnAxie 方法,它可以由拥有产卵权限的用户地址(同时还在被允许的产卵时间里)调用,从而返回所生成axie的信息,并广播事件。
这个逻辑理顺了,其他几个有关出生、死亡、进化等的事件和方法也就迎刃而解了。
还值得一提的是这段代码:
1 | function getAxie( |
这个方法几乎在所有的nft中都会出现,算是基础操作。咱总得有个获取已经生成的nft的方法,对吧?
这个文件其实没什么好讲的,甚至如果比较轻型的团队或比较简单的合约,都会勿略掉权限控制部分。这里大概就是定义了各种各样的修饰器,例如 onlyCEO、onlyCOO、onlyCLevel 等等,用来控制某些关键操作只能由特定的账户地址来操作。
例如其中比较经典的:
1 | function withdrawBalance() external onlyCFO { |
这里就限制了只有CFO账户地址可以提取资产。
同理其实 dependency/AxieDependency.sol 这个合约也在做类似的事情。如果是类似的事情为什么会分成两个合约还放在归在不同的文件夹中呢?其实仔细分析就会知道,AxieAccessControl 是针对整个Axie Infinity系统而言的,而 AxieDependency 仅仅是针对某一只Axie而言的。
其实讲到这里,Axie Infinity的公开合约中关于核心NFT资产部分也就没什么好分析的了。Core文件夹中的其他合约,都是一些修饰性的内容。而关于如何生成基因密钥,包括怀孕、产卵等比较关建的详细合约,都不在其中。
如果想要了解有关生成一个NFT的过程,可以参考 CryptoKitties 的相关代码,网上有很多公开的分析。当然,有需要,我也可以粗略分析一下。
如果想要了解有关NFT市场的代码,同理搜索 CryptoKitties 的相关信息,附带有讲到相关内容。当然,还是上面那句话,有需要我也可以粗略分析一下。
最后,本人学疏才浅,各位看官如果发现有任何问题或者遗漏,还请帮忙指出来,不胜感激。
]]>为什么说凑巧呢?因为这段时间很纠结于游戏的内容生产问题,毕竟只有2个人做一个其实体量不算小的游戏,内容填充是个很大的问题。为了能够减小工作量的同时,保证游戏内容充实,设计上已经做了几次改版了。最近的想法就是用自然语言处理来解决事件和对话的问题,已经看了有一段时间并做了些实践了。
先说体验的结论吧,要实际应用起来应该说还有一定距离。但是带给人的震撼和想象力,已经足够了。

GPT全称是“Generative Pre-Training”,直译过来就是“生成式预训练”。
而 Open AI GPT 是 OpenAI 团队在论文 《Improving Language Understanding by Generative Pre-Training》 中提出的预训练语言模型。
现在常用的GPT模型是GPT-3。GPT-3的神经网络包含1750亿个参数,为有史以来参数最多的神经网络模型。OpenAI于发表GPT-3的论文后,在次月为少量公司与开发人团放出应用程序界面的测试版。微软在2020年9月22日宣布取得了GPT-3的独家授权。
基本上可以说,GPT-3目前是这个领域的一家独大。OpenAI也是这个领域的霸主地位。
ChatGPT 是基于GPT-3.5模型的魔改。GPT-3.5和3.0的区别有几点,首先是和微软合作,在微软的Azure AI云服务器上完成了训练;另一个重要的区别是其训练数据集里除了文字,还加入了代码,因此 ChatGPT 现在已经可以写程序,甚至给现成的代码找bug了。
为什么试用过 ChatGPT 的同学都感觉提升很明显?一个重要的原因是 ChatGPT 引入了一个新的训练方法RLHF,见论文 《Training language models to follow instructions with human feedback》,简单地说,就是用人类反馈的方式加强训练。
他们其实在最初的论文中就提及了一种新的训练方式,即半监督的方法:结合无监督的预训练和有监督的微调。就是这个半监督,成就了今天 ChatGPT 的震撼。
作为一个语言模型,ChatGPT 具备最基本的文本生成能力,在创作和续写小说、诗歌等文学创作场景上的表现不凡。
此外,它还能以非文本形式与人对话,甚至能够各种 emojis 的含义且能将其按照文本叙事的逻辑进行排列。
当然,更震撼的还在于 ChatGPT 能够帮助调试代码,并且还能对提问的合理性提出质疑,要求用户调整提问。以至于 Replit 的 CEO 也发帖称赞它的代码能力:不仅能够解释 bug,还能修复 bug 并解释如何修复。
但是恐怕最让人感到逆天的,是它强大的问答能力无不透露出其充当甚至代替搜索引擎的潜力。参见下图。
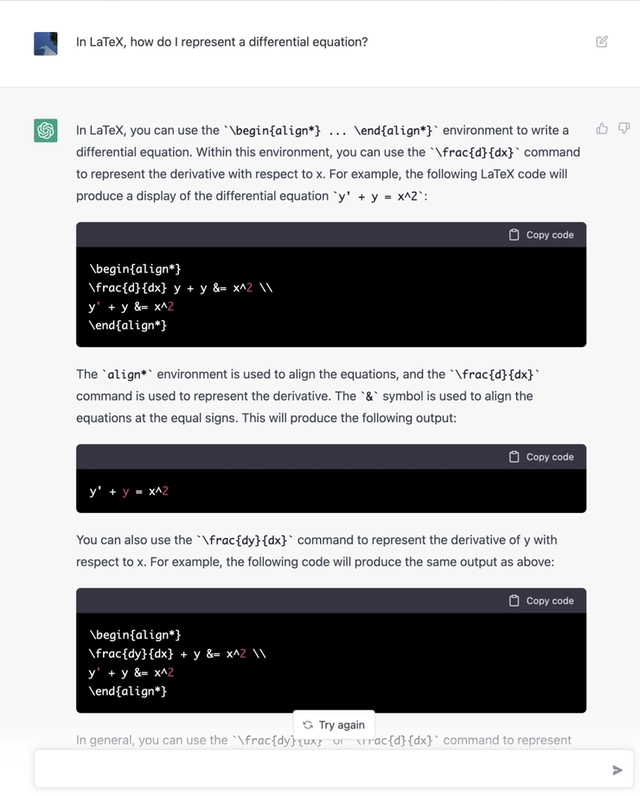
自己实际试用以后,确实感受到了强大,不仅仅在于它听懂了你字面上的意思,甚至能够理解语境的含义。也难怪有人让它来替自己跟Adobe的销售砍价。
当然,被举出来的例子都是完美的表现。其实它也有很多词不达意的时候,甚至你问的A领域的问题,它回答的是Z领域的建议。尽管瑕不掩瑜。
但,以上这些是否就是 ChatGPT 的终极目标?很难说,因为结合人们的想象力,它可以为视频AI提供脚本、可以为绘画AI指定描述词、可以为音乐AI提供乐谱风格……
这是我给自己提出的很有意思的问题,也因此我才能在解决内容生产的道路上继续前行。
没错,GPT-3.5已经证明了它的强大,但是这并不影响已经足够应对一些非正式场景的GPT-3。而GPT-3已经有了开源平替,我已经初步验证完可行性的 GPT-Neo。
如果说当年的 Style2Paint 和 Stable-Diffusion 让我眼前一亮, 那 GPT-Neo 算得上我现在手里的当红小生。
我不太清楚目前国内一些新兴的自然语言处理AI平台是基于什么技术,但是 GPT-Neo 经过自己的训练,完全可以实现同等效果。
它目前包含了三组模型:EleutherAI/gpt-neo-2.7B(容量10G+,包含27亿参数)、EleutherAI/gpt-neo-1.3B(容量5G+,包含13亿参数)、EleutherAI/gpt-neo-125M(容量500Mb+,包含1.25亿参数)。最小的模型结果还是有点惨不忍睹,最大的模型在英文方面已经游刃有余。
大概,AI的时代越来越近了。如果它们开始代替我们生产所有内容,那么我们还能多大程度上制定规则?
谁知道呢,总之我们现在需要它们来提升效率就对了 😀
]]>Vue2.6新增了observable函数,用于生成一个响应式对象。这个响应式对象即Observer对象。Observer对象主要用于触发DOM的更新。
也就是说,观察者模式的主要应用场景,是当一个变量值被修改时,可以自动通知所有关注这个变量的其他对象,自动重新更新获取这个变量的新值。
emmm,确实非常符合vue的特征。
但是这也带来一些弊端,很多时候我们习惯于拿到一个数据可以直接操作,或者至少像一些更严格点的语言,定义getter和setter。而Observer这种不能直接操作对象总是有点让人懵。
网上提供了一些解决思路。或许他们在某些情况下有用吧,但是我这里实测无效。
1 | let parsedobj = JSON.parse(JSON.stringify(obj)) |
不得不说,js里也经常有些骚操作。但是我还是推荐更规范的做法,比如用 Object.assign。
先看看ES6官方文档是怎么介绍的:
Object.assign() 方法用于将所有可枚举属性的值从一个或多个源对象复制到目标对象。它将返回目标对象。
简单来说,就是Object.assign()是对象的静态方法,可以用来复制对象的可枚举属性到目标对象,利用这个特性可以实现对象属性的合并。
使用起来也很简单:
1 | Object.assign(target, ...sources) |
基础用法:
1 | let target = {name:'lilei', age:40}; |
多个源对象与重名的情况:
1 | let target = {name:'lilei', age:40}; |
针对oberser对象的情况,我们通常需要直接转换为普通对象或者数组。
1 | // 转换为对象 |
So easy,收工。
]]>Intel的nuc8i7hvk 冥王峡谷是一台很神奇的机型,使用的是我唯一见过的Intel和AMD合作搞的CPU。而且性能还算很不错的,当时入的二手,也不贵,很契合我开发+策划+美术的定位,性能很平衡。(唯独就是没法使用nvdia的cuda,所以无论跑 style2paint 还是 stable diffusion 都很吃力)

搜了一下,B站上有个比较详细的拆机视频,这里就不放了,去搜索 冥王峡谷 换硅脂 ,第一位肯定就是了。注意先完整看一遍,因为他有些期间无用的操作,自己实战的时候完全可以避免。
我这里就直接图文说明了,多图预警!
1、第一步很简单,拆骷髅头一边的外壳面板,6颗螺丝,用H2.5内六角的起子即可。这里顺便把从金属板下面伸出来的白色的较宽的接头拆开。

2、这里有一颗螺丝,拆下之前不要蛮力去掰金属板。

3、将金属板垂直提起即可,如果侧边有点卡住的感觉,不要用力,稍稍调整位置就可以抽出来。

4、取下这根中网框架上伸出来的线。

5、取下中网框架。这里要小心一点,有的地方和接口处是有卡扣的,往外轻轻掰一下就能轻松解开。

6、两个端头各有一根从主板下方伸出来的风扇电源线,取掉。同时这步也把内存条取下来,避免操作中不小心损坏。

7、无线网卡有一根线从主板下方伸出来连接,正常情况下无线网卡是重叠安装在主硬盘下方的,需要先拧下螺丝取掉上层的硬盘,然后使用尖嘴钳之类的工具轻轻拧动留下来夹住网卡的螺栓,接着手动拧下,就可以取下网卡了。

8、这里也有一个螺栓,用刚才的方法取下来。

9、这个支架在取的时候一定保证四个螺丝轮流松动,以免支架变形。

10、图中这个地方还有一个螺丝,别直接开始抠主板下来。

11、现在是整个过程最需要技巧的地方,四个指头轻轻抬起图中主板朝上的一边,两个大拇指分别向下轻靠上方的两个橙色圆孔处。(图中是我已经取下来了,实际上没有取下之前,橙色圆孔处是伸出来的黑色螺栓)

12、主板拿下来的瞬间真是惨不忍睹。硅脂已经完全干了,跟蛋壳似的能碎掉。风扇的位置全是灰尘,灰尘都结成团了,拿出来都不散的那种……

13、拆下风扇和散热板,清理完所有的部件,准备涂硅脂。

14、大致涂好硅脂,按刚才拆开的步骤反向顺序安回去。注意线材不要被框架和主板压住。

这种小主机真的结构非常密集,而且很特殊,拆之前一定先查资料。
重新安装以后,机场的感觉没有消失,但是明显温度和噪音都变小了。大概是因为我同时开了一大堆东西吧,毕竟各个职位的事情都得做。也辛苦这个小玩意了😛
]]>python真的是个有趣的东西,在以前真的很难想象,我在学习和工作的同时,后台还跑着两个刚入门的我写的程序,不停的帮我自动处理各种数据。
最近自己的两个小项目觉得都特别有意义,决定把hexo同步文章到公众号这个分享出来。相信对很多人而言,比我更有用处(毕竟我只会玩点技术,运营就是渣渣)。
这篇文章重点参考了 Python爬取网上文章并发表到微信公众号 ,我针对接口调整和自己实际情况,进行了一些调整。感谢作者的分享。

由于之前的实践,我先做了一种假设:
1、在本地运行hexo,然后通过 requests 和 BeautifulSoup 爬取和解析列表存到本地sqlite数据库,然后内容和样式爬下来;
2、将相关图片从对象存储下载下来,调用公众号接口上传到微信公众号素材;
3、组装好所有内容,调用公众号接口上传到草稿箱;
4、确认内容,调用公众号接口发布。
这里面有个问题,是后面才发现的,所以实际上的流程并不是这样,下面我会说。
设想有了,就构造各种方法,每个方法都测试一下。
验证过程就省略了,说下最后的流程和如此选择的原因。
实际上我从本地运行的hexo站点爬完所有内容进行测试的时候,本希望直接上传爬到的样式,公众号就能够完美呈现。然而我想多了,很多样式会被吃掉,而且有的样式在公众号呈现的结果和网页并不一样。
因此,我最后选择了直接用本地的markdown文件解析为最基本的html文档结构,然后参照 mdnice 的样式以及微信公众号自带编辑器的样式,对html重新定义样式。
那么废话少说,开工。
首先是爬取列表,定义一个获取列表内容的方法:
1 | # coding:utf-8 |
接下来按列表来爬取详情,特别说明一下,这里的 formatApiHighlight 方法是调用了一个接口来格式化代码高亮,实际上本地是可以用 pygments 库来处理的,处理完后把css样式代码赋值给html代码即可。
1 | # max_posts是每次用户操作允许处理的文章数量,没有写在config里面,由用户自己输入 |
1 | def dealPostDetail(title, summury, content_arr, origin_url): |
上面的方法中涉及到了2个额外的方法。其中之一,是上传头图,这张图必须用单独的公众号接口,因为我们需要它的媒体ID。
1 | def uploadWxCover(src_url, title): |
另一个方法就是上传正文图片,然后拿到url。
1 | def uploadWxImg(src_url): |
因为自己使用的关系,代码比较随意,上传草稿的接口在上面的代码里其实已经调用了,就是 res = uploadWxPost(title, summury, content_str, cover_id, origin_url) 这段。方法内容如下:
1 | def uploadWxPost(title, summury, content, cover_id, content_source_url): |
特别提醒:如果你需要勾选 原创 或者 赞赏,那么先不要发布!一定先到后台手动编辑!
1 | def publishPostList(max_posts): |
至此,发布完成。接下来可以在公众号后台进行后续操作。
前面一直没有提,相对的,我也觉得这一步其实没有什么说的必要,因为任何微信接口肯定都需要token。
但是一路写下来,好像每个步骤都在提微信token,那就还是给它露个脸吧。
1 | def getWxToken(): |
本人也算是个python小白,所以实现过程中自然也有很多问题,大致梳理了一下。
这个就是前面提到把微信Token存下来的好处,我一直忽略了微信接口有次数的问题。由于尝试的次数太多,微信直接丢给我 errcode: 45009,我才查到这个问题。接口频次限制如下:
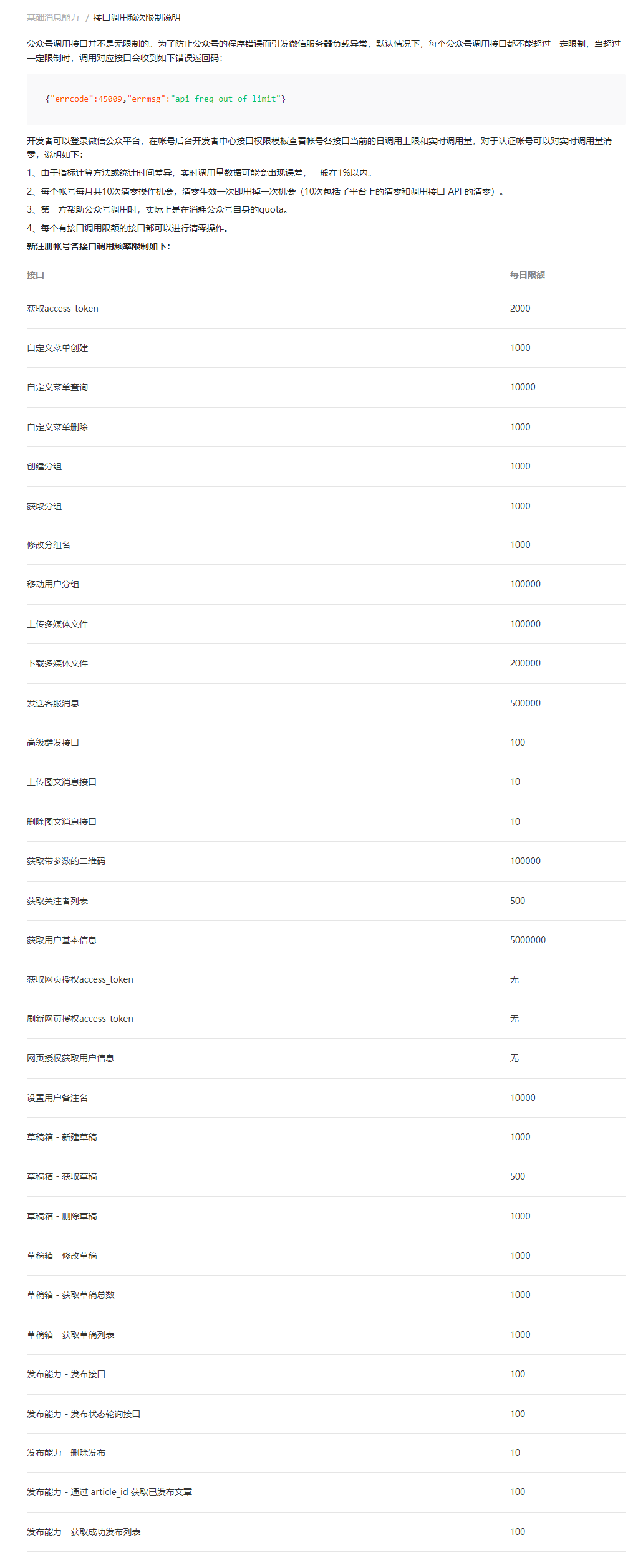
当然,也可参见 基础消息能力 /接口调用频次限制说明。
这个问题是比较意外的,耽搁了很久。毕竟我以为直接把带样式的html文本发过去就完了,结果居然样式全乱了。而且现在也不是最理想的状态,先将就了。
接口次数限制也是由于这个问题才发现的 😂
大神们有更好的处理办法也请分享,谢谢!
翻找了很久,发现微信开放社区有人跟我一样的疑问,为什么没有原创与赞赏接口。然后我确定了,的确没有,需要自己手动操作。
emmm🤔,懒得吐槽了,寄人篱下,多低头
这个目前对我而言其实算不上问题,因为我是完全同步博客,不需要资源管理。
但是如果要管理,其实可以参考我十分熟悉的wordpress,以及fastadmin,用一张表单独存储附件信息,然后跟文章关联起来。思路十分简单。
1 | // javascript |
又例如:
1 | // C# |
如此通用的写法,让我觉得python应该也差不多。但是一写,vs code就提示语法错误了。
赶紧上网搜了搜,居然这么神奇。完全就是if…else的变体,很好理解,就是别和其他语言搞混了。
1 | a = 1 |
hexo generate 命令发布时又报错了。这是个老问题,好像从hexo升级到3.x以后就一直存在。错误内容如下:
1 | INFO Start processing |
疫情在家,不如好好研究下怎么回事,也许不复杂呢?
然后简单的搜索了下,好家伙,真的一下就找到问题了。参见 https://github.com/hexojs/hexo/issues/1771#issuecomment-187583293
按这篇帖子的意思,hexo从2.x使用 Swig 渲染markdown到3.x版本使用 Nunjucks 渲染,有的语法已经不支持了。
比如我早期由于使用 artTemplate 开发前端,很喜欢用 \{\% abc \%\} 这样的语法,于是写博客的时候也这么用,但是到了3.x就报错了。
虽然这并不能解释为什么我用 v12.x 的node环境仍然可以正常发布,用 v14.x 的就不行,但是我觉得原因应该类似吧。
目前把所有的旧语法都改为新的,就可以正常发布了。
]]>load-script.php 和 load-style.php 的缘故。上网查询了下,很简单,解决方法就是在网站根目录wp-config.php文件中,禁止合并脚本。代码如下:
1 | define('CONCATENATE_SCRIPTS', false); |
最后选择了 遇见图床 ,感觉挺正规的,自称2018年就开始运营,而且强制开启鉴黄接口,保证了干净整洁,不容易被封。
选择它也是因为api比较完善。我这次只会用到图片上传,参看 遇见图床api文档
之所以会写这一篇,是因为遇见图床的api必须使用表单的文件类型上传图片,于是又学习了一下。
其中关键代码如下:
1 | imgOpen = open(localImg, 'rb') |
这里面重点就是file需要读取二进制文件,而不能直接填入文件名。同时,图床文档里明确了图片的字段为image,因此不能随便写个file之类的上去。
然后根据文档中的响应解释,构造对响应的解析。
1 | try: |
最后贴上整个方法的全部代码:
1 | def dealImage(src_url): |
以上内容主要参考了 魔芋红茶 / markdown-img 。
]]>我习惯于一边做一边学知识,这次的实际情况是想要使用代码下载一张图片,看到了三种方式,其中一种就是with…as,于是打算好好理解一下。
代码如下:
1 | tmp = requests.get(src_url, timeout=2) |
按理说,如果现在的我拿到这个需求,我会这样写:
1 | tmp = requests.get(src_url, timeout=2) |
区别似乎很明显了,看上去with像是python对于try的语法糖,但是还需要查资料理解一下它具体的工作方式。
以下内容主要参考了 Python之with as语句 (屌丝版) 、 python中with和异常处理实例分析 、 官网 8. 复合语句¶ 的第5部分。
首先with所操作的对象,必须有两个重要的方法,__enter__、__exit__。
Python对with的处理很聪明。
紧跟with后面的语句被求值后,返回对象的enter()方法被调用,这个方法的返回值将被赋值给as后面的变量。当with后面的代码块全部被执行完之后,将调用前面返回对象的exit()方法。
with 要生效,需要作用于一个上下文管理器——
打住,到底什么是上下文管理器呢?
长话短说,就是实现了__enter__和__exit__方法的对象。
在进入一个运行时上下文前,会先加载这两个方法以备使用。进入这个运行时上下文时,调用__enter__方法;退出该上下文前,则会调用__exit__方法。
这里的“运行时上下文”,可以简单地理解为一个提供了某些特殊配置的代码作用域。
这里有一点特殊的是,Python中文件对象本身就是一个上下文管理器,因此我们可以使用open函数作为求值的表达式。
随后调用__enter__方法,返回的对象绑定到我们指定的标识符file上。文件对象的__enter__返回文件对象自身,因此这句代码就是将打开的 file_name.jpg 文件对象绑定到了标识符file上。
紧跟着执行 with 语句块中的内容。
最后调用__exit__,退出 with 语句块。
似乎with语句直接跳过了异常处理,对于不关心异常的场景下,无疑大幅减少了代码量,同时还保证了程序可以正常运行不被中断。
]]>蝙蝠侠站在他的蝙蝠车旁边,用着他的蝙蝠电脑。
他有时是布鲁斯韦恩,有时是蝙蝠侠。但他永远是个孤儿。
蝙蝠侠:
现在这是一个安全的城市。我把企鹅人打进了监狱。
阿尔弗雷德,蝙蝠侠的忠实战士,端着一盘哥特火腿。
阿尔弗雷德:
吃晚饭了,韦恩床垫。
爆炸发生了。小丑和双面人进入洞穴。
小丑是个小丑,但很疯狂。双面人是一个人,但不是律师。
蝙蝠侠:
不!他们是双面人和单面人。
他们恨我是一只蝙蝠。
蝙蝠侠将阿尔弗雷德扔向双面人。双面人像抛硬币一样抛投阿尔弗雷德。 阿尔弗雷德头朝上脚落地,于是双面人只好回家了。
蝙蝠侠:
现在只有你和我了,小丑。
蝙蝠对小丑。放下一切大干一场吧。
小丑:
我是个怪人。这个社会很糟糕。
你喝的是水,我喝的则是混乱。
蝙蝠侠:
不,我像蝙蝠一样喝蝙蝠!
蝙蝠侠四处寻找他的父母,但他们仍然死了。
这让他很生气。他发射了一枚蝙蝠飞弹。小丑用他病态的幽默感弹开了它。这就是小丑的力量。
小丑:
我从来没有遵守规则。那就是我的规则。你跟吗?我不。
蝙蝠侠:
阿尔弗雷德,去生下罗宾。
于是阿尔弗雷德开始生罗宾,因为这是他的工作。
小丑手里拿着一份礼物。 他把它交给了蝙蝠侠。
小丑:
蝙蝠日快乐,生日人。
蝙蝠侠打开礼物,因为他是个好人。礼物里有一张新父母兑换券,但已经过期了。
这是一个小丑笑话。

完全摸不着头脑,而且笑抽风了是不是。
据说这是喜剧演员兼作家 Keaton Patti 让一个人工智能机器人观看超过1000小时的蝙蝠侠电影,然后让它自己写一部蝙蝠侠电影剧本。
不得不说,故事还是挺精彩的,尤其抓住了双面人掷硬币和小丑开冷笑话的特征。这也是整个剧本的亮点。
可能大家现在还觉得ai蠢蠢的,但是放到2018年,那会儿我们几个人潜心研究区块链和人工智能的时候,才什么样子。短短4年,不论是自然语言、着色、绘画、故事逻辑,全都有了飞跃般的进步。未来是什么样真的难以预测。
这个时代的卷,很大程度上只是效率进步的副产物。当机器进一步替代了一些原来还需要靠人脑处理的事情,人类将继续探索一些现在还没深入的领域。
最后附上原文。

第一次玩express+ejs的组合,其他都还顺利,唯独部署以后,用域名访问无法加载css js等文件。
很快确定了是反向代理的问题,因为直接ip+端口访问,是一切正常的。
谷歌了一下,很快得到了答案,这个组合下,需要对静态资源单独配置。直接上代码:
1 | server |
收工。
]]>那这次就干脆简单实现个带皮肤的电子钟吧。
先确保依赖模块装了,这次是需要 tkinter。
1 | pip install tkinter |
首先引入模块 tkinter 和 time。
1 | import tkinter as tk |
然后定义好界面样式,包括主题。
1 | def light_theme(): |
实现核心的显示时钟功能。
1 | def time(): |
最后,加上切换主题的方法。
1 | menubar = tk.Menu(root) |
运行一下看看。
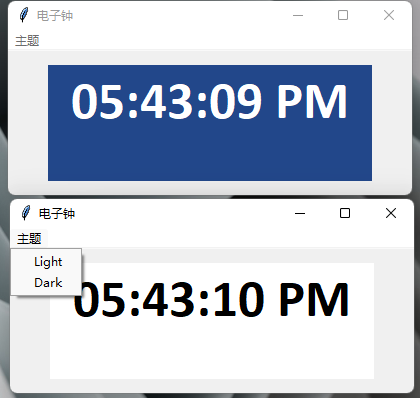
附上所有源码。
1 | import tkinter as tk |
先安装好依赖模块。
1 | pip install beautifulsoup4 |
结合前几个实践,这次的也是简单到不行,直接上代码。
1 | import requests as rq |
输入 www.baidu.com ,得到下面的文件:

自己是 LastPass app的忠实用户,生成随机密码的功能也经常用到,今天来实现一下。
首先导入 random 和 math 这两个自带库,并定义好组成密码的字符串内容。同时,也展示一个交互对话,让用户输入期望的密码长度。
1 | import random |
然后,根据输入的长度,先分别生成字母、数字、特殊字符所需要的长度。
1 | alpha_len = pass_len//2 |
接下来定义关键方法,在这里处理所有的字符串:
1 | def generate_pass(length, array, is_alpha=False): |
最后,调用处理密码字符串的方法,合并所有处理好的字符串,并随机排列一次,打印出来。
1 | # 英文字母 |
附上完整代码:
1 | import random |
如果没有基础,可以看前面两篇了解一下,这次就直接上代码吧。
1 | from PIL import Image, ImageFont, ImageDraw |
原图片、完成图、细节图如下。

tkinter 库做一个简单的计算器。tkinter 主要是解决界面问题。
首先导入库,定义计算器的界面窗体。
1 | import tkinter as tk |
接下来定义界面控件,并关联事件。
1 | # 定义一个可变字符变量 |
再然后处理按键事件
1 | def inputnumber(param): |
最后运行窗体主循环。
1 | root.mainloop() |
运行一下,效果如图。

附上全部代码:
1 | import tkinter as tk |
SimpleHTTPServer 。SimpleHTTPServer是Python 2自带的一个模块,是Python的Web服务器。在Python 3已经合并到http.server模块中。如果不指定端口号默认的是8000端口。在局域网中使用web去访问 http:/IP:8000 即可。其中Python 2语法为:python -m SimpleHTTPServer
Python 3语法为:python -m http.server
当然,这个只是顺带提一句。因为今天打算实践的是C/S双向通信。
代码特别好懂,就不赘述了。
1 | import socket |
首先,命令行启动服务端。

然后打开网页,网页和服务端控制台都正常输出。
首先有个问题,就是模拟灰度,这里有个公式:
1 | Gray = 0.2126 × R + 0.7152 × G + 0.0722 × B |
这样就好办了。当然,RGB模式下,256x256x256的颜色范围虽然被转换成了256的灰度范围,字符还是不好一一对应。我们可以使用一个字符对应多个灰度的方式来解决。
记得要先安装PIL库,其中:
如果是Python 2,运行 pip install PIL。
如果是Python 3,运行 pip install pillow。
接下来直接上代码吧:
1 | from PIL import Image |
如果想要输出到文件,可以在定义的部分,加上想要保存的文件名 OUTPUT = 'output.txt',然后在最后写进去:
1 | with open(OUTPUT, 'w') as f: |
最后,我们得到了这个:
在 SSLDUN 上弄了个 positiveSSL 的泛域名证书,真的便宜到哭,一年才500元。
都配好了以后,就到了在百度云加速上提交SSL证书的环节。云加速服务还是挺好的,免费5G/天的流量,带IPv6,带基础防护。但是,不出意外的出了幺蛾子。
提交证书的时候有提示 “请上传正确的证书链(服务器+中间证书)” 问题错误。证书当然是没有问题的,不使用云加速已经可以正常访问,猜想应该是格式不符合导致的。
百度到了一个挺有用的工具:MySSL 证书链修复工具
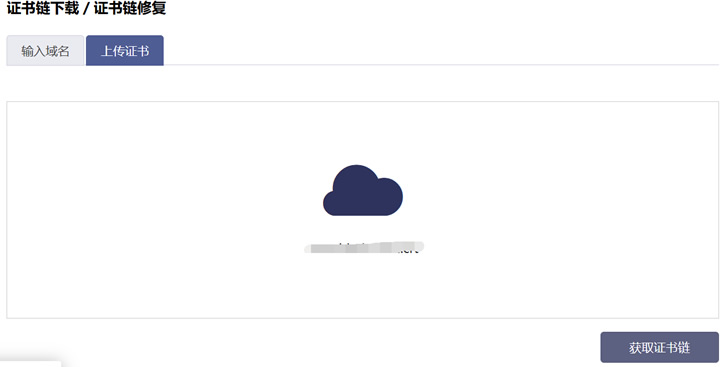
在以上界面上传证书文件,或者直接拷贝证书文本内容。证书一般是crt或者pem格式。最后把获得的字符串复制到百度云加速证书上传的证书部分,填入剩下的内容,就可以成功提交了。
]]>这次我们来玩 time 模块。
1 | import time |
输出
1 | 302.5 |
我是在 这个网站 运行python代码的。因为如果本地运行,执行太快,间隔时间直接就成了0了。
这里,我们使用到了 time.time() ,把时间戳存到 start 里了。
然后在计算了 55*5.5 以后,又记录了一次时间戳,存到变量 end 中。
最后,打印 end 和 start 的差值。
1 | from timeit import default_timer as timer |
输出
1 | 302.5 |
看上去他们干的事情是一样的。
]]>python是当初报了个9块9的班入了个门。不得不感叹它确实是一门相当好掌握的语言,而且工具很多。难怪陈总一直用它做小工具。说到自动化、机器学习、神经网络,真的是一个都绕不开python。这次参考了hongkiat上的一篇文章,实现了Gmail自动登录。
这个实践中,与原作者不同,我使用了以下工具:
安装后,重新启动计算机以使安装生效。
在cmd中输入pip install selenium,将Selenium Web自动化工具包添加到Python中。Selenium让我们可以通过代码来滚动页面、复制文本、填写表单和点击按钮。
下载对应的 Chrome 驱动,然后解压到Python根目录。
首先,导入Selenium Python库中所需的模块。
打开你喜欢的任意python编辑器,我偏向于vscode,因为它免费。当然,我绝不否认 jetbrain 的 PyCharm 是我用过的最强Python IDE。
创建文件 gmail.py ,加入以下代码:
1 | from selenium import webdriver |
然后,写入你的用户名和密码:
1 | username = 'yourUsername' |
接下来就通过驱动程序打开Chrome,并跳转到Gmail的登录页面。
1 | browser = webdriver.Chrome() |
通过前面的代码,我们跳转到了登录页面。接下来要找到页面中的节点来输入用户名和密码。
F12打开Chrome的开发者工具,使用选择工具找到节点元素。
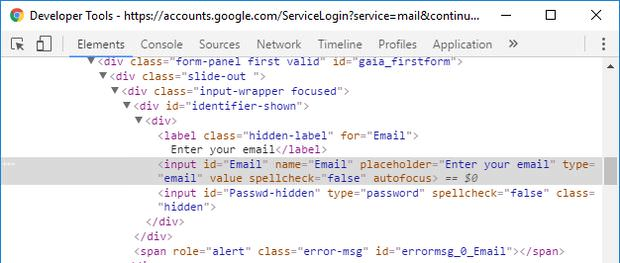
我们在代码中使用html的id属性找到Email并填入用户名。然后,我们则需要再点击Next按钮,以便切换到输入密码的界面。
1 | # 填充用户名,并点击下一步按钮 |
原本接下来就应该输入密码,点击登录。但是代码执行速度远远快于页面切换的速度,因此我们需要让程序等一会,直到它找到密码输入框。
1 | # 在找到密码输入框之前,等待最多10秒 |
现在已经简单的完成了自动登录Gmail的机器人。
注意,由于安全原因,最后极可能登录失败。
然而,这个实践的重点根本不在于能不能登录gmail。它告诉我们如何通过代码打开网页,跳转到需要的页面,查找到所需要的元素,进行相应的操作,最后得到我们想要的结果。这个自动化过程可以应用的场景实在太多,给人带来无穷无尽的可能性和想象空间。
但是,要记得合法合理合情使用,不要作死!
最后附上 gmail.py 完整代码:
1 | from selenium import webdriver |
网上一般提供的方法都是设置缓存,这里不再多说,一句git config http.postBuffer 524288000就完事。
我们这里讨论的是自建git服务器的情况。
直接说答案,两种方案:
打开 nginx.conf,编辑 client_max_body_size 50m; 这一行,把大小改成你需要的单文件大小,比如 1024m 。
打开 httpd.conf,编辑 LimitRequestBody 52428800 这一行,同上。
没错,直接不要使用https,而是用ssh地址,这样就不会受到网页服务器的配置限制了。
]]>如果没有十足把握,建议参考 CentOS7下升级GLIBC2.31 这篇文章进行操作。完全保姆级的,全避坑。
以下是我自己的操作,过程中出现了报错,出现了重启无法进入系统。进行了一系列修复,才成功升级。
NodeJs测试服务端总是重启,日志又没有任何异常,就很绝望。在不断细化日志也没有找到问题以后,只能怀疑内存和堆栈了。于是查了一圈,发现heapdump似乎还不错,准备使用。
反正不顺利是常态,在本地测试ok后,就部署到测试服准备等结果。结果是直接报错了。
1 | ImportError: /lib64/libstdc++.so.6: version `CXXABI_1.3.9' not found |
网上还是很容易查到相关信息,但实际上解决起来并不简单,问题都是一环扣一环的。
首先发现需要更新glibc,那么就在官网地址:http://ftp.gnu.org/gnu/glibc/ 下载了一个版本。然后尝试编译安装。
1 | tar -xf glibc-2.32.tar.gz |
然而make是过不了的,提示说:
1 | *** These critical programs are missing or too old: make compiler |
又继续上网查资料,说make和gcc版本又太低。这……
好吧,那么又开始更新make和gcc,可以参考这两个链接来处理:
上面gcc编译非常耗费时间,能不等就不要等,差一点的服务器直接是按小时计算的。
更新结束以后,回来继续编译glibc。
1 | make & make install |
最后检测一下
1 | ls -l /lib64/libc.so.6 |
如果找不到,或者发现链接有问题,就手动链接一下
1 | cd /usr/local/lib64 |
目前能想到的有两种实现方式,一种比较灵活:直接修改tokenURI,即暴露一个方法给授权地址,在需要的时候可以修改tokenURI;一种比较简洁:设置一个变量作为开关,被授权的地址调用方法来切换不同的tokenURI。
那么有没有既灵活又简洁的方法呢?把两种方式加起来就好了(对不起,抖了个机灵)……即开启盲盒的时候,既改变开关变量(这个是为了在其他相关逻辑中方便的获取到开启状态),同时也要设置tokenURI。
上代码:
1 | // contracts/test.sol |
就酱紫。
]]>会有感而发,不仅仅因为我对这台车感兴趣,而是因为我也是众筹成员之一,并且从来也没动过退费的心思,甚至买鸡蛋都上张大妈的我,已经为它准备好了车库。因为这台车的设计初衷就是我想要的东西——一台价格足够屌丝、外观足够炸街、内涵水桶平衡的电跑车。
这次的共创会可以参考这篇观感——参与现场的用户手记
话说每次打算开共创会都会遇上疫情的Cyberster,这次终于赶上和现场的参与者见面了。当然,出于保密的原因,我们并没有见到这次的真身。然而从有幸一睹芳容的现场参与朋友的字里行间,无论文章还是群聊,都透露出整体满意的情绪。这也让我十分安心。除了文章里提到保留的极具特点的“箭头尾灯“,群里还提到了,无论价格,将全系配备”剪刀门“,以及已经有4门设计的计划。这确实让我更加期待。毕竟一家三口出行炸街,是我这样中年男人更想要做的事情。哈哈😄
其实在共创会期间有2件有趣的事情,还让我有所感触。
一个是在共创会前后,有一些平时不太出现的朋友忽然说话、不知道具体情况的其他网友随便张口,但是张嘴就是”现场好简陋“、”都是官方吧“,这类东西,怎么说呢,确实我们言论自由很幸福,但是张嘴就来真的好吗?我不太喜欢评判,但是如果评判了,那我一定不止想了10秒钟。
第二个是有朋友觉得这个共创会感觉像做戏,似乎什么有用的消息都没有,也没有对参与众筹的朋友有更多信息的公开,感觉大家跟名爵的其他用户甚至广大网友的待遇没有任何区别。其实吧,这个事情某种层面上跟营销有关。记得有个群友说得好,MG这些传统车企,做到合格就是满分了,就是说不要期望太高。更何况在我看来,名爵这次的操作如果把主要目标用户考虑成次准用户,那么绝对不止合格。
哎,年纪大了,用脑太多,脑子也糊涂。乱七八糟说了这些,可能明天自己都看不懂。
希望这台大家爱称cy的车,能在2022年末如期步入大家的眼帘,2023年内成为我家的新座驾。期待(☆▽☆)
]]>啊,我感到醍醐灌顶,如梦初醒 Σ(っ °Д °;)っ
对于我们这种惜时如金的小团队,这不是基本操作吗?二话不说,就开始找nodejs的测试框架。
过程省略,总之选了 Mocha + Chai ,不是别的,因为这个组合如果说自己的使用率在nodejs排第二,那没人敢排第一。而且可以找到的案例和支持特别丰富。那就赶紧入手开始吧。
1 | npm install --save-dev mocha chai chai-http |
1 | ... |
默认是2秒超时,但是链上返回有时特别慢,所以改成10秒了。
1 | ... |
必须要将主文件作为模块导出,提供给Mocha使用。
创建 test/web3.js
1 | process.env.NODE_ENV='development'; //使用测试环境 |
执行 npm run test
输出结果
1 | Server is running at: http://127.0.0.1:8080 |
收工
]]>安顿孩子睡了以后,想着看看怎么回事,结果就很尴尬。 The gsgundam namespace has exceeded its pipeline minutes quota. Buy additional pipeline minutes, or no new jobs or pipelines in its projects will run. 就是说时间到头了。那要什么时候才能再用呢?查了下,说一个月400分钟。难道是这个月调试hexo的新问题提交太多次了?
咨询了一下 陈总 ,说github的时间肯定够。果然,GitHub的Actions每月有2000分钟,存储上限是500MB。那么又试着转GitHub吧。
参考了GitHub Docs里 从 GitLab CI/CD 迁移到 GitHub Actions 的官方教程和另一篇来自于网友的 如何正确的使用 GitHub Actions 实现 Hexo 博客的 CICD 。
直入正题吧,项目里建立.gihub/workflows/upload2ftp.yml,写入一下内容:
1 | name: upload2ftp |
大概需要注意的就是,依然为了不要暴露密码,所以把ftp相关信息写到了项目的action secrets中。
测试一下,好像没什么问题。
如果这边时间也不够了,下个月又切另一边,哈哈。
]]>先安装低版本,包括Unity hub,hub尽可能安装能使用的最高版本。
安装完成后,确保可以使用,并备份C:\ProgramData\Unity\Unity_lic.ulf。
安装高版本,不要重复安装hub了,其他跟低版本基本一样,但是不要去动C:\ProgramData\Unity\Unity_lic.ulf,覆盖exe文件和删除Unity安装目录的Unity\Editor\Data\Resources\Licensing目录即可。
完全不用再去处理Unity_lic.ulf
然后在hub里添加高版本的Unity程序。
如此反复,可以安装若干版本的unity editor。
]]>PHP Warning: Invalid argument supplied for foreach() in \wp-admin\includes\script-loader.php on line 2678
不知道怎么出现的,但这是在wp自己的代码里,怀疑跟升级有关。
打开被警告的文件找到对应行:
1 | foreach ( $wp_styles->queue as $handle ) { |
看样子是$wp_styles没有被认为是一个有效的数组,我试着强制转换了一下
1 | foreach ( (array)$wp_styles->queue as $handle ) { |
测试通过,收工。
]]>MIUIMix的Rom,省电顺滑的优化做得不错,刨下来试了试,真的蛮好用。
首先呢,这个Rom完全只是优化MIUI,安卓版本也停留在8.1.0,所以想要尝鲜新系统的家人们就不要试了!!!如果真的有朋友需要,我可以把最新的lineage 19 for MiPad4搬运回来,安卓版本也更新到了11的。
老样子,进入正题。
–MiuiMiX_2.0_clover_9.12.3_v11-8.1_20191203.zip -必需
–TWRP-20191001-3.3.1.0-clover.img -必需
–miflash_unlock-en-5.5.224.24.zip -必需
–TOOLS_BY_CZ_V7.20 -推荐(密码:6666)
还是老样子,如果下载遇到问题,欢迎加入我的知识星球,已经备好了各种资源,直接下载即可。另外说下,白嫖客太多了,现在改了加入方式,需要先在 这里 操作。
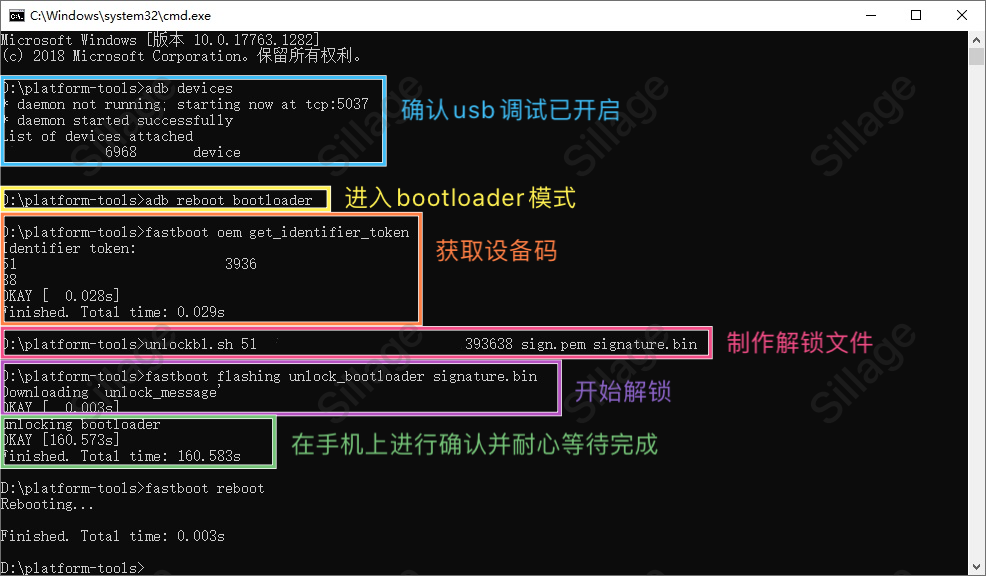
设置里进去>我的设备>全部参数,但大部分都是点击MIUI版本号若干次,开启开发者模式。然后进入开发者模式找到USB调试,打开开关即可。
在开发者模式里找到设备解锁状态,插入SIM卡并绑定账号。米Pad4支持最新版本的miflash_unlock,所以为所谓用哪个版本,只要能连上服务器都行。
按照软件指引操作完成。
另外,如果需要备份资料,现在就操作,并拷贝到其他地方,方便操作!
用MIUIMix必须刷入第三方Recovery。首先进入bootloader,比如长按音量键下+锁屏键,直到手机完全重启。
当然是要用数据线连接手机和PC,刷入recovery可以直接命令行,例如:
1 | adb fastboot flash recovery twrp.img |
或者使用图形化工具TOOLS_BY_CZ,将TWRP-20191001-3.3.1.0-clover.img放到工具目录下的”File”文件夹里,然后直接选择线刷专区,文件选中TWRP-20191001-3.3.1.0-clover.img,分区选中Recovery,点击刷入,等待完成即可。
这个是我躺了的坑,安卓8.0以后,Data会自动加密,似乎直接重刷会造成新系统无法使用Data(个人理解是这样,因为刷回MIUI就重新可用了,请大神指正)。
所以,在重启进入TWRP以后,输入密码可以忽略不管。重要的是下面这几步:
1、进入Wipe,选择Format Data2、不要重启!!!再进入Wipe,选择高级清除选项,三清3、保持USB插入,进入Mount,禁用MTP,再启用MTP(我这边刷完TWRP,虽然显示启用了MTP,但是实际上PC上并没有)如果上述清理过程中,出现了提示无法清理Data目录,重新进入Recovery再试。那么,不用犹豫,刷入原版MIUI从头再来一次,否则都是浪费时间。
用PC拷入MiuiMiX_2.0_clover_9.12.3_v11-8.1_20191203.zip到手机存储,选择Install,然后选择这个文件,右滑刷入即可。
刷入的提示里可能有少量看起来不正常的信息,不用管。
刷入完成重启手机,第一次进入系统会比较慢,可能还要重启一次,耐心等待。

至此,焕发青春的MiPad4 Plus再临。

这里声明一下我的观点,区块链的前景还是可以说很大的,但是不是在炒币炒NFT炒概念上。必须承认这个目前能赚钱,但是除非能确保赚钱的是自己。我们国家的趋势是支持区块链应用,但是绝对反对用来做金融投机的。
我的另一个观点是,了解区块链,应用区块链,对个人绝对是有好处的。但是不要太乐观,从18年到现在,这个行业的实际应用到目前为止几乎没有发生实质性的实用性进展。不过就是从炒币变成了炒NFTs。这一堆数据在会操作的人手里是工具,但是在韭菜那里就是悬在头上的镰刀而已。
好了,胡扯了这么多,说回正题,来看Axie Infinity的合约吧。从白皮书的《智能合约与GitHub仓库》 Smart contracts and GitHub Repo 上可以看到,有一些完全公开的合约,也有一些并没有公开源代码但提供了查询地址的合约。我们先看公开的部分,初步进行了解,也帮助我自己确定自己都理解了。
Axie Infinity的核心资产是Axie,我们从 GitHub仓库公开合约 里可以找到,Core contract部分就是我们要找的东西。
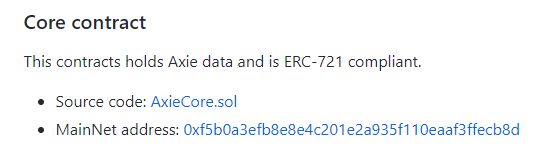
目录结构是这样的:
1 | │ AxieAccessControl.sol |
AxieCore.sol就是我们目前最需要的东西。现在我们顺着依赖往回理,看它是如何从最基础的协议一步步做过来的。这个文件头部写明:
1 |
|
所以我们再找到AxieERC721.sol
1 | pragma solidity ^0.4.19; |
然后我们又可以发现,这个作为核心依赖的合约,主要由两部分构成,AxieERC721BaseEnumerable.sol和AxieERC721Metadata.sol,从名称上我们可以推测,这两部分分别管理了基础数据(即直译过来的基础可枚举)和扩展属性(即直译过来的元数据)。通常在实现一个ERC721资产的时候,链上只会存储最基础的数据,例如作为先锋的CryptoKitties,链上只存储了基因数据和生育相关数据(因为要用于链上计算)。而更多的信息,例如名字、描述、图片信息、其他属性等等,则通过Metadata的方式存储在其他地方,例如IPFS或者自己指定的传统互联网地址等。
先来看AxieERC721BaseEnumerable.sol文件。
1 | pragma solidity ^0.4.19; |
好吧,我终于还是打算先说一句,虽然我相信来看文章的新人肯定很少,但以防万一嘛。pragma solidity ^0.4.19这一句是指定了solidity的版本,这个与js很相近的语言,一直在迭代更新,现在已经到了0.8.x的版本,虽然谈不上大相径庭,但是已经产生了很多不兼容的情况,甚至无法通过编译。所以熟悉和指定语言版本在这里很重要。
如果没记错,Axie说过在他们开发完成合约之前,EIP721还在草案阶段,所以在引入的这些IERC721xxx可以看到,跟Zeppelin这一类的合约库相比,有一些不同。但是这也不重要,因为他们功能其实基本一致。然后我们来看,他引用的这些类(erc165和erc721文件夹里的这些合约就不详细说了,现在已经成了ERC721标准,可以直接在Zeppelin引入):
SafeMath - 没有专门去弄清楚这个用于避免程序结果产生溢出的类到底是不是出自Zeppelin,但是他们的这个类库很出名也很有用的。这么有名的库为什么不重点说说呢?因为在最新的Solidity 0.8.x中,这个类库已经不需要了。
ERC165 - 一种发布并能检测到一个智能合约实现了什么接口的标准。我自己组织了很久语言,都没找到合适的描述方式,最后觉得这句听上去特别废话的话最能解释他的作用。可以看看这位的解析erc721-165学习,这句话就出自他。事实上我认为,能弄懂这个看起来很简单的标准,也就代表区块链基础知识已经完全过关了。
IERC721Base - 直接翻译过来,就是符合ERC721的合约基本需求的接口。包括了用户余额、Token持有者、转让、授权等等。
IERC721Enumerable - 这一个也有点不好归纳,通过内容和EIP721的描述,大概可以理解为作为查看整个合约的资产状况的接口。但似乎这里包含了更多内容,例如资产总量、根据索引查资产、根据索引查持有者、Token有效性验证、持有者有效性验证、以及一些修饰器。
IERC721TokenReceiver - 这个对应了ERC721的safeTransfer,用于在接收到safeTransferFrom完成的消息后,触发onERC721Received方法。
基本的合约和接口分析完了,接下来又是2个Axie自己的特有依赖AxieDependency和AxiePausable。为了防止无限套娃,这里就此打住,目前只需要知道,前者主要在规范整个合约的权限,后者可暂停代币的一切行为。这些以后再详说。只是这里再补一句,大家认为的完全去中心化,只是一厢情愿,所有区块链的应用,只可能在信任的基础上,一定程度上去中心化。
接下来看合约部分:
1 | contract AxieERC721BaseEnumerable is ERC165, IERC721Base, IERC721Enumerable, AxieDependency, AxiePausable { |
整个合约因为其实都是ERC721标准的实现,没有太多可讲的。重点说一下using ... for ...,通常是指将前者的函数用于后者。在这里,则是说把SafeMath的方法绑定到uint256类型上。需要注意的是,using之前,必须要先import!
好了,来看另一个合约,AxieERC721Metadata,它引入了两个类库
1 | ... |
很熟悉的身影是不是,没错,就是上面的AxieERC721BaseEnumerable。AxieERC721Metadata合约通过继承前者,来实现了一些定义。这个文件内容不多,但是有很多特别有意思,也是对新人特别有用的地方。
先来看第一个:
1 | ... |
来看网上的这句说明: Note: the ERC-165 identifier for this interface is 0x5b5e139f. 是不是有点意思?还记得前面我提到的那篇文章和那句话吗?结合起来,看懂了,就明白ERC165在做什么了。
来看下一个点,
1 | ... |
这里的作用很简单,其实就是定义了Token的名字叫Axie, 代币符号为AXIE。但这不重要,因为重点是出现了一个很难在其他语言里看到的词,pure。我一开始接触到这个修饰器的时候,第一个想到了惜字如金的电报时代。因为每一个操作都是白花花的银子,所以能不操作的东西,就不要操作。于是在solidity中出现了这两个东西view和pure。其中view表示,对storage变量可读不可写,而pure则对storage既不可读也不可写。因为不写就代表不需要矿工验证,不需要gas,也就是不需要花钱。那说到storage,是不是还有个对应的东西?没错,0.4.x版本里模糊了这个概念,很多时候开发者不需要关心是什么(只是很多时候,因为后面我们就能看到声明)。但是0.8.x版本已经把这个权力交回到开发者手里,到底是storage还是memory,需要开发者自己来规划。有什么区别呢?是不是记得区块链最贵的操作是存储💴?但是结果需要大家自己去实践,不要省这点时间。
下一部分可以有两个地方注意:
1 | ... |
第一个,我们一直没说的external,以及之前出现了的internal,实际上还有public和private。来个清晰的说明:
private - 只能在当前合约内访问,在继承合约中都不可访问。
internal - 函数只能通过内部访问(当前合约或者继承的合约),可在当前合约或继承合约中调用。
external - external标识的函数是合约接口的一部分。函数只能通过外部的方式调用。外部函数在接收大的数组时更有效。
public - public标识的函数是合约接口的一部分。可以通过内部,或者消息来进行调用。
除了以上解释以外,作为合约开发,还有一个必须扎根心底的概念,就是gas消耗。那么,如果你的函数仅仅需要外部调用,那么你应该用external,如果你的函数需要内部和外部同时调用,那么使用public。这个涉及到内存分配管理,我觉得也没必要深入了解,仅仅上面几句话足以判断4个可见性花费的递进关系了。
第二个,是onlyCEO,这个看起来很特别的修饰器,实际上是在AxieDependency所引入的另一个文件AxieAccessControl中定义的,它判断了消息发送者地址是否跟我们定义的ceo地址一致。有时候我们用的很少的判断,会直接在需要的地方require(msg.sender == ceoAddress),但是这种随时可能用到的判断,直接定义为修饰器会更方便。
到了最后一个方法了
1 | ... |
这部分是这个合约的核心部分。它定义了扩展数据的网络地址,以便可以在访问ERC721资产的同时,得到一些诸如图片之类的额外数据。头部的mustBeValidToken(_tokenId)比较明显,是在基础类里定义的修饰器。
这里主要打算说的是另一个问题,一开始我想当然的觉得,把_tokenURIPrefix、tokenURISuffix、_tokenId组合起来的方式肯定是tokenURIPrefix + _tokenId + tokenURISuffix。当然,现在看起来这很蠢。因为作为一个处处花钱的语言,是不会轻易自动去做任何转换的。所以正确的方式,是把所有内容全部转换为字节(其实多看点代码还会发现,string并不是经常被使用的类型,相信原因都懂的),然后拼接起来。
劈里啪啦写了一堆,再一看时间,都凌晨5点了。下次继续吧。
]]>这次跟着解决搜索的问题,索性一并仔细找寻了一下。
整个过程一点都不轻松,因为完全没有头绪。开发最怕的事情是3件,1、找不到问题;2、找不到原因;3、找不到方法。我被成功卡在第二步。
不知道原因,只能不断的排除。能上传,说明基础配置是没有问题的。那么就调整lftp的参数,进行各种尝试。
废话不多说,直接上结果:
1 | # This file is a template, and might need editing before it works on your project. |
重点在于把lftp命令提前到script中执行,并且添加–trasfer-all参数,尝试确保全部传输完毕。事实证明成功了。
原文在这里 使用GitLab CI持续集成并自动FTP同步 。
]]>问题如下:
1 | $ hexo -s |
虽说不影响运行,但是很莫名其妙,因为除了环境以外,什么都没动过哎。哪来的循环依赖。
直接上google吧,很顺利的找到了解决方案。我个人倾向于这种: https://www.haoyizebo.com/posts/710984d0/ 。
可以直接看这里 https://github.com/nodejs/node/pull/29935 。但是其实不太重要,只要知道是Hexo以及所依赖的插件造成的问题。通过 npx cross-env NODE_OPTIONS="--trace-warnings" hexo s 命令来启动本地服务,可以查看到调试信息,找到是哪里警告和报错。
然后我们追踪可以发现,其实就是stylus跟nodejs14新合并的pr产生的问题。但是通过google到的文章可以知道,这个问题已经在0.54.8版本修复了,也就是说,应该是有插件依赖了旧版本的stylus。每个人的情况不一样,上面的文章说是出在nib,但我出在cjs。这都不重要,问题找到了,现在就来搞解决方案吧。
总的来说有有两大方案吧:
这个最直接、干脆、暴力,既然是新的nodejs出的问题,那降级不就好了?
Windows:直接到 https://nodejs.org/download/release/v12.22.7/ 下载安装包,并安装到原有位置即可。
Linux/Mac:安装版本管理器n就可以切换版本了
1 | $ npm install -g n |
检查一下node版本,然后最好重启一下console,不然有缓存,npm还是使用的新版本。问题解决!
resolutions是什么?简单来说,它是 yarn 提供的统一所有依赖和依赖的依赖和依赖的依赖的依赖……(无限循环下去)的字段。什么?你问我yarn是什么?如果真的懒得去查一下的话,那你就把它理解成npm的替代品。
为什么使用resolutions?因为简单方便,如果要用npm来解决依赖问题,需要新安装插件,更麻烦的配置,更多的理解。而resolutions简单直白,就是大声说出来:“这个插件我只用这个版本!”
那么,在 package.json 里增加 resolutions 来覆盖版本定义:
1 | ... |
如果没有安装yarn,使用 npm install -g yarn 安装一下,然后执行 yarn install,一切都安静了。
这之后一定要记得,都要用 yarn 来管理包,不然resolutions就没有用了。
另外,搜索真的是互联网人的重要能力,大家都保持吧!
]]>从bitcoin到ethereum到eos,3条最主流应用的链看完了,还是有很多收获。当然,还是要扯回今天的主题,实际在搭建基于geth的poa链时,miner.start()返回了null。
检查了好几遍也没有发现有什么问题。突然灵机一动,检查了一下当前的区块,就出现了下面一幕。
1 | > miner.start() |
……居然是正常的,怪不得google上的那些回答都有点答非所问……
直接跳过了,先把主要的东西理清楚,再来解决这些奇奇怪怪的小东西 🤬
]]>好家伙,有段时间没见,后台都改得我都不认识了。
想看看现在Unity Ads还有多少钱,折腾了整整半天,终于找到了。
路径是 https://unity.com/ -> 登录账号 -> 选择“Dashboard(控制面板)” -> Monetize -> Finance 即可。其中,可能前面进入了某一个特定的项目,在Monetize这里需要先返回到上一层,再点击 Finance。
这是孩儿她妈唯一一次送我手机,特别稀罕,即便已经过去7年了,还是一直舍不得完全淘汰。第一次刷Lineage就是用的米4。
这回在搞完口袋阅以后,就琢磨着要不让米4这老爷机也新生一次?
我先来描述一下之前的惨状,刷了一个魔改的基于安卓7的Lineage,安装软件不太多,大约5个,有微信,无sim卡。使用有卡顿感,大部分时间息屏,但是待机时间不超过1天。
由于陈总之前的引导,我相信只要能找到适配米4的原版Lineage,一定有希望让米4的表现有所改观。
所以,你能想到吗?一台7年前的老爷机,还能被一直支持到次新系统,拥有专门的机型页面。我知道,这次有戏了。
–lineage-17.1-20200403-UNOFFICIAL-cancro.zip -必需
–twrp-3.2.1-0-cancro-20180305.img -必需(密码:auxp)
–miflash_unlock-4.5.813.51.zip -必需
–TOOLS_BY_CZ_V7.20 -推荐(密码:6666)
–Magisk-v21-4.zip -推荐(密码:g1a0)
–opengapp -推荐(选择ARM->Android 10->pico已经够用)
其中magisk是被lineage官方采用了的新的root方案,建议直接刷入。(这也是我觉得lineage优秀的方面,可以接纳其他工具比自己的做的好)
这一步当然是安卓搞机必需做的事情,每台机子打开开发者模式的方式不尽相同,但大部分都是点击mod的版本号若干次。然后进入找到USB调试,打开开关即可。
要想刷机,小米当然得解锁才行。我的米4早在刷安卓7的时候就解锁了,但是为了确保万无一失,我还是下载了小米解锁工具来确认。幸好有这么一步,又帮大家躺平一坑。目前所有的国内官网上的解锁工具,都已经无法解锁甚至无法确认米4是否解锁,需要下载一个miflash_unlock-4.5.813.51的老版本才能正常运作。
这步很简单,按照软件指引操作即可。
印象里米4的TWRP特别容易掉,果然,用音量上+锁屏键进Recovery,直接就是小米的,这当然不行。
首先进入bootloader,比如长按音量键下+锁屏键,直到手机完全重启。
所谓线刷,当然是要用数据线连接手机和PC。
刷入recovery可以直接命令行,例如:
1 | adb fastboot flash recovery twrp.img |
但是还有图形化更好用的工具,例如TOOLS_BY_CZ,将twrp-3.2.1-0-cancro-20180305.img放到工具目录下的”File”文件夹里,然后直接选择线刷专区,文件选中twrp-3.2.1-0-cancro-20180305.img,分区选中Recovery,点击刷入,等待完成即可。
首先进入Recovery,可以长按音量上+锁屏键,也可以用TOOLS_BY_CZ工具来操作。为了确保刷入以后能正常启动,请备份必要资料并三清。
清理完成以后,用PC拷入lineage-17.1-20200403-UNOFFICIAL-cancro.zip到手机存储,选择Install,然后选择这个文件,右滑刷入即可。
刷入完成重启手机,第一次进入系统会比较慢,耐心等待。
实际操作中,我发现可能作者并没有很好的内置magisk,以至于我第一次进系统,打开Magisk manager发现magisk并没有安装,所以我们用PC拷入Magisk-v21-4.zip到手机存储,再次进入到Recovery,安装zip包。如果对google服务有要求,一并刷入gapp就可以了。
lineage是基于安卓原版进行优化和适配的,因此本身是要基于谷歌服务的。基于一些特殊原因,任何连接都会被判定为网络不通畅(除非你有工具)。这个不止是视觉上的问题,重要的是一旦网络断开,手机并不会自动连接该网络,很影响体验,耗电也有所干扰。
在开启USB调试,并且连接PC的情况下,进行以下操作即可:
1、输入命令
1 | adb shell settings put global captive_portal_https_url https://www.google.cn/generate_204 |
2、开启飞行模式,然后关闭飞行模式,收工!
至此,小米4彻底复活。

在酷安上筛选了各种工具以后,开启冰箱,耗电得到极好的控制。尤其在Kitsunebi始终运行的情况下,纯待机2天半毫无压力。来,米4再战3年。
所以说安卓机的好处和坏处都在这里:既有机会让它变得更加个性化更好用,也可能挥霍掉宝贵的时间还有可能变砖赔钱。
能写这一篇,自然是因为最后成功了,而且还要安利一个QQ群:25130136,入群费10元,但是买不了吃亏买不了上当。如果你在玩老爷机、墨水屏、偏门机型,那在这里大概率能得到你想要的答案,可能会迟到,但是一定不会缺席。
群主一直没有回复我是否可以授权,于是我花了几个星期自己学习了一下展讯Rom的制作,开了个星球来放自己的所有资源,考虑到以后可能会下载或者自己手动做一些东西,给了个收费门槛。有需要可以考虑下。做了个优惠券:https://t.zsxq.com/b6iIaUr。
废话说完,我们来到正题,刷机。
查看自己口袋阅1代的版本,可以在关于手机里先看看,理论上sc801a和sc801a-1都可以使用,但是不确定sc801c可以使用。如果是sc801a-1,那刷网上流传的v88.root版,很容易丢蜂窝信号(不要问我是怎么知道的)。所以请加入我前面说的到的QQ群,获取SC801a-1.V91.202005281427_Modify_by_Sillage.pac。
所有需要准备的文件如下:
–SPRD_NPI_USBDriver_1.4(驱动)-必需
–SPD_Driver_R4.20.0201(驱动)-如果上面的驱动无效,试试这个
–UnLockBL(解锁工具)-必需
–ResearchDownload_R25.20.3901(刷机工具)-必需
–SC801a-1.V91.202005281427_Modify_by_Sillage.pac(刷机包) -必需
–SC801a.V88_Modify_Root.pac(刷机包) -推荐
–TOOLS_BY_CZ_V7.20(adb/fb工具箱) -推荐
–KDY_Magisk21.4_Patch_by_Sillage.pac(magisk刷机包) -备用
以上所有内容,全部可以在推荐的QQ群里找到。网上也有部分流传,但是作为对群主劳动成果的尊重,我就不多说了,反正我是入群下载的。
不论刷入哪个版本的固件,开发者选项必须打开,从而打开USB调试模式的开关。如果是v81以上,可以使用*#*#5858#*#*;如果是v58以上,可以使用*#*#415263#*#*。特别的,似乎v77版本是没有办法打开调试模式的,如果不巧刚好是这个版本,选择在线更新即可。
打开开发者选项以后,进入找到USB调试,打开开关即可。
这步简单,直接运行SPRD_NPI_USBDriver_1.4安装文件即可。
刷v91版本必须解锁BootLoader。
这里有个要注意的事情,必须使用UnLockBL.7z内的文件进行全部操作。我之前就犯了这个问题,搞了2天都没弄对,千万不要使用其他platform_tools来执行命令。
连接好PC和手机以后,开始后面的操作步骤。
首先进入bootloader,通常有以下几种方式:
1、长按音量键下+锁屏键,直到手机完全重启;
2、使用adb命令,运行
1 | adb reboot bootloader |
3、打开之前下载的TOOLS_BY_CZ_V7.20工具,选择线刷专区,点击Fastboot(BL)。
记得从这里开始,必须使用UnLockBL.7z内的文件进行操作,否则一定会有问题,我尝试了各种版本的platform tools,都是没法正确走完流程的。另外,记得安装Git客户端,不过相信大部分愿意折腾的都是程序猿,所以不太可能没有安装。
执行以下命令得到序列号
1 | fastboot oem get_identifier_token |
1 | unlockbl.sh device_sn sign.pem signature.bin |
其中”device_sn”为第一步获得的,记得有多长就复制多长,就算换行了也要一并复制。
1 | fastboot flashing unlock_bootloader signature.bin |
这里要注意的是,口袋阅在bootloader下,屏幕是没有提示的,等到差不多的时候(约5秒,或听PC连接音提示),按下音量下键确认操作。这个坑也卡了我好久,最后在群友的配合下找到了问题所在,已经在群公告里加入了提示。
群公告里还有一步重新刷入userdata,但是对我来说完全不需要,所以跳过了,直接执行以下命令重启手机。
1 | fastboot reboot |
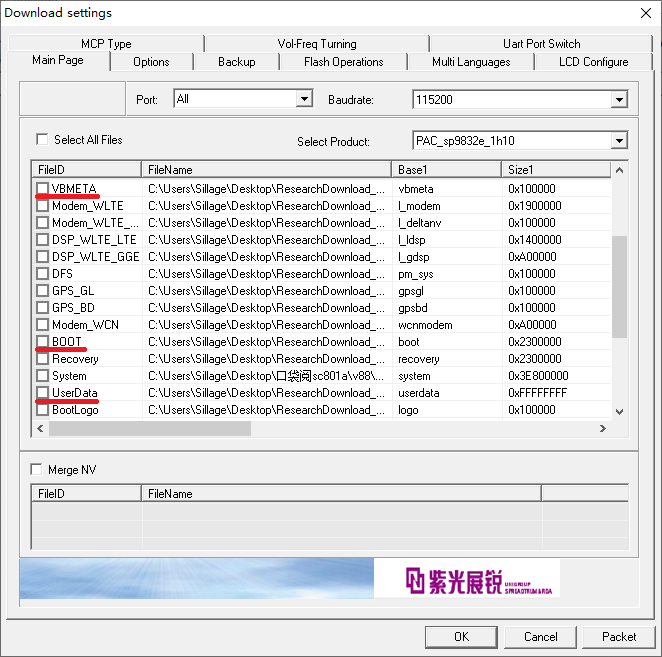
特别说明,这里只讲刷入v91版本的过程。如果是801a-1机型要刷入v88版本,记得取消勾选NV_LTE和Vendor即可正常使用。
如果不是很熟悉安卓软硬件的朋友,以下步骤最好照做:
打开刷机工具ResearchDownload,点击齿轮图标选择下载的系统固件SC801a-1.V91.202005281427_Modify_by_Sillage,直到载入完成。
点击箭头图标,参考之前的步骤,让口袋阅进入bootloader。然后插入数据线。
经过小伙伴们的反映,上面这一步不太确定我是否记正确了。参考评论区的大神回答,请各位看官优先尝试 关机后按音量下键,再插数据线。
刷机工具出现进度条后,耐心等待完成即可。
正常走完以上步骤,是不太可能再有坑的。至此,口袋阅就成了一个标准的备用机,后面再加上冰箱等app,待机时间进一步控制,很趁手。

难道说我该换掉2010款的mbp了吗?
当然不,因为没钱……
我相信,一定有办法越过苹果的屏蔽装上最新的macOS的。于是谷歌了一下,主要有两个工具,一个是推荐给Mac工作站的BigMa,另一个就是今天的主角——big-sur-micropatcher。
首先准备一个至少16G的容量的U盘。
下载最新的Big Sur安装程序。
下载最新版本的big-sur-micropatcher 0.5.1,最早可以支持到2008的Mac Pro。
双击下载好的InstallAssistant.pkg。这样会把安装程序放到Application中。
1、最好先使用mac的磁盘工具手动格式化一下。默认的Mac OS扩展(日志式),GUID分区图即可。格式化时一定确认自己清楚U盘的名字,一会要用到。
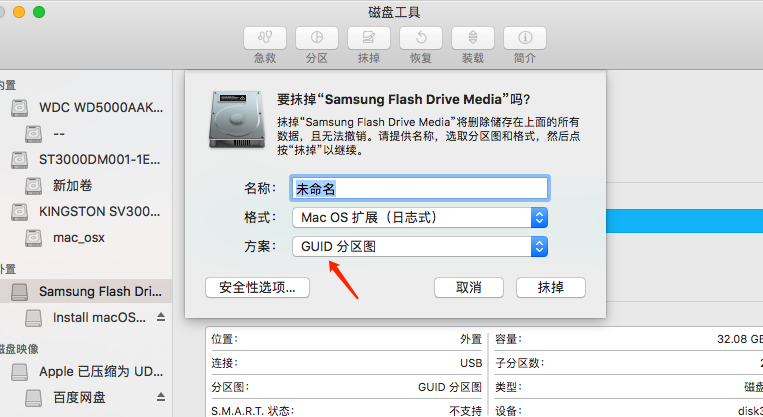
2、打开终端,输入以下命令,并输入y,回车确认。记得替换[udisk]为U盘名字,不确定的时候,多用Tab键补全对比下。
1 | sudo /Applications/Install\ macOS\ Big\ Sur.app/Contents/Resources/createinstallmedia --volume /Volumes/[udisk] |
这步时间有点长,一定要等待完成。
1、解压下载的补丁程序zip,得到big-sur-micropatcher,里边有micropatcher.sh和install-setvars.sh两个重要文件。
2、首先将micropatcher.sh拖入终端窗口,再将U盘从Finder里拖入终端窗口,回车执行。
3、等待完成后,按同样的方式处理install-setvars.sh。
无论什么设备,都一定先用时间机器Time Machine完全备份一次。不管后面是因为安装失败恢复原系统,还是安装成功恢复设置,都有用。
至此,准备工作完成。
1、重新启动Mac,按住Option键,直到出现引导菜单。这里要选择EFI启动,如果有多个EFI启动选项,选择黄色图标的那个。选择了以后,通常在几秒内就会自动关闭,当然,也有可能跟我一样,Mac立即就关闭了。
2、然后再次开机,同样按住Option键,这次选择安装 macOS Big Sur。
3、建议使用磁盘工具,把主驱动器全盘抹除格式化为APFS系统卷。
4、执行安装程序并等待。
5、按补丁作者所说,大部分早于2011年的Mac,例如MacBook 2010系列,都会遭遇内核错误而反复重启。我也不例外。不过人家都提示了,当然是有方案的。在重启过程中,按住Option键,像上面的第2步一样,选择安装 macOS Big Sur。如果在这个过程当中又报错了,不要气馁,连续两次都进入引导菜单,并选择安装 macOS Big Sur,就可以了。
6、在安装助手中打开终端,输入以下内容。记得将[Macintosh\ HD]替换为自己主驱动器的名字。再次温馨提示多用Tab键。
1 | /Volumes/Image\ Volume/patch-kexts.sh --2010 /Volumes/[Macintosh\ HD]. |
7、重启MacBook,这样安装会继续顺利进行,直至最终完成。
8、再次进入MacBook,已经是Big Sur的启动界面,在设置过程中,希望你还记得我们之前用Time Machine备份过一次,这下大用场来了。因为之前是完全重新安装,因此我们可以通过备份恢复绝大部分资料和设置。这里千万要记得出现资料传输时,如果你希望恢复资料和设置,一定一定一定要现在恢复。错过了就没有机会了。
9、等待所有设置完成。最后,进入系统。欢迎来到Big Sur。
如果你要按照本篇操作,并且有一定的英文阅读能力,请一定阅读补丁作者原文。他写的比我目前看到网上的任何一篇教程都要清晰和详细,各种意外情况都包含在内。
网上有说,在安装完成后,一定不要操作以下两种模式启动mac ,会导致无法引导启动。本人没有试过,也不会去试,大家可以借鉴一下。
1、重置配置开机:
按住 shift + control + option + 开机键四个按钮,大概20秒,松手。
2、 清除缓存开机:
开机按住 command + option + P + R 四个按钮20秒松开,让电脑开机。
macOS的内置Time Machine实在是一个非常有用的东西,如果有闲置硬盘,甚至壕气的你有Time Capsule,那不要吝啬,开着,太有帮助了。
]]>打开开发者调试窗口,发现是因为无法访问README.md文件。
这就奇怪了,因为这个文件跟首页同级目录存放,而且没有什么特殊权限。
于是想到了是不是网站配置文件的问题。
打开宝塔,查看nginx的配置,果然,README.md被放到了禁止访问的文件列表中。
去除掉就好了。
收工。
]]>首先看生成的微信小程序里,最大的部分是vender.js,1.8Mb。如果这个能缩小一些,那就有希望。
先从npm插件入手,看看哪些是还可以压缩。自己找了一圈,发现只有 moment 插件有机会优化,比如去掉中文以外的所有语言文档。
在vue.config.js中增加
1 | plugins: [ |
然而发现效果微乎其微,就减少了200k左右。
在网上查了一下资料,发现即便配置了开启运行时压缩,其实也只是生产环境下有用,开发环境下是不会进行压缩的。
要全部都压缩,需要在vue.config.js增加这段代码
1 | optimization: { |
这样打包以后,发现vender.js只有600多k了,而且其他文件也都跟生产环境一样,全部压缩了。
可能有朋友或者以后的自己会纳闷,那为什么还需要一段代码单独来开关这个功能?因为如果始终开启,在微信小程序工具里,调试窗口里也就一堆看不懂的压缩消息了。
]]>这次在自己的博客上记一下,免得总是找度娘。
结束gogs进程,gogs默认端口位3000(这里一定自己要匹配自己的端口),查询端口进程
1 | $lsof -i:3000 |
然后杀死进程
1 | $kill -9 [pid] |
然后启动服务
1 | $nohup ./gogs web & |
收工。
]]>cmd来替代操作,所以就没管它。但是最近powershell好像使用得特别多,就各种不方便了,所有npm安装的软件几乎都用不了。均提示:
1 | 无法加载文件 xxx ,因为在此系统中禁止执行脚本。有关详细信息,请参阅 "get-help about_signing" |
解决方案很简单,管理员身份打开powershell,运行
1 | set-ExecutionPolicy ALLSIGNED |
然后选择“Y”。解决。
]]>老版本的服务端是基于fastadmin开发的,于是我查看了一下,真的有一个叫fastadmin助手小程序的插件,可以在服务端方便的生成crud接口,同时提供小程序段代码。
二话不说,入手。
然后……
尴尬了,原来fastadmin的版本是2018,但是助手小程序要求202008以后的版本才可以。
升级过程也不算顺利,记录一下吧:
1、首先下载最新版fastadmin完整包,本地安装。
2、备份原项目。
3、使用BeyondCompare比对,逐一更新项目文件。这里需要注意一下,由于大部分目录都没修改过,其实可以直接覆盖就好了。但是application目录下肯定有不少新增文件,还包括config和database,一定要仔细比对,逐行添加和修改。
1、删除public/assets/libs目录所有内容。
2、保证bower和composer的配置文件都是最新的。
3、使用bower install安装前端依赖。
4、使用composer update安装php依赖。注意,在安装过程中,有可能出现
1 | putenv() has been disabled for security reasons |
或者
1 | shell_exe() has been disabled for security reasons |
之类的错误,原因只是对应的php版本禁用了这个函数,允许使用就好了。
1、使用navicat连接原项目和新安装fastadmin的数据库。
2、选中新数据库,选择菜单工具->结构同步。这里首先只同步所有存在的数据表结构,忽略掉新增的。
3、选择菜单工具->数据传输。将新增的表添加到原项目中。
1、直接启动ngnix,访问项目看有没有问题,没有问题就可以跳过了。
2、然而我写这一步,当然是因为我的出问题了😢 进入站点提示:
1 | Parse error: syntax error, unexpected ':', expecting '{' in E:\wamp64\www\yii\vendor\symfony\polyfill-php80\bootstrap.php |
很容易的搜到了原因,新的依赖包polyfill中没有支持 php5.6,所以把项目使用的php环境改为了7.2,一切恢复正常。
1 | ... |
好吧,因为处理完了才想起来应该记录下来,所以记不得全文了。
但是错误原因在console里写得很清楚,就是unity 2019已经内置了System.Data.dll,但是我们原来的项目在处理excel的时候,由于2017和2018都没有System.Data,所以我们导入了。现在二者冲突了,所以必须去掉一个。
当然,肯定是删除我们导入的,然后一切恢复了正常。
]]>于是先命令行查一下到底是什么占用了大量空间。
1 | find / -type f -size +100000000c -exec du -sh {} \; |
然后发现了这堆东西
1 | ... |
呃……询问以后没有什么用处,于是直接删掉了
想了想,感觉总靠人力发现不行,而且又是测试服,只要定期清理就好了。
于是打开宝塔面板,添加计划任务->Shell脚本,文本框里加上
1 | find /www/server/redisBak -name "redis.log" -exec rm -rf {} \; |
收工。
]]>路途漫漫,但是功夫不负有心人,最终使用一个插件解决Category pagination fix。
知其然,还要知其所以然。原文注释提到:the 'page' looks like a post name, not the keyword "page",也就是说wordpress会把分页路径中的page当成文章名来处理,自然就找不到了。
整个插件内容如下:
1 | /** |
另外,在用wp_query请求内容的时候,需要记得传递分页参数 paged 。
然而处理方法很简单:
1、Win+R后,输入inetcpl.cpl;
2、点击高级,勾选使用TLS 1.2。

如此即可。
]]>
虽然作为一个资深互联网入坑者,早已知道这个等待也有可能遥遥无期的。但是对于我这个阿里云和Teambition的重度使用者来说,还是十分期待。
看邮件内容,3-6周内会进入下一个阶段,估算一下,2-3个月应该就能拿到网盘资格了。
不知道百度网盘目前作何感想。
]]>然而失策了……
居然安装失败了,消息列表写着安装[php-7.4]【已完成】耗时29秒,然而软件商店里php7.4还显示着“安装”按钮。
赶紧查看下执行日志吧(摘录关键的):
1 | No package 'libjpeg' found |
原因很明确了,应该安装libjpeg包就可以了。
于是连上ssh,执行安装命令:
1 | yum install libjpeg libjpeg-devel |
搞定。安装php7.4。成功。
]]>1 | Err [Imp] 1153 - Got a packet bigger than 'max_allowed_packet' bytes |
解决方法如下:
1、首先使用root登录mysql
2、然后执行以下命令:
1 | set global max_allowed_packet=1000000000; |
于是可以放心大胆的开始折腾机器了。
年龄大了,其实也不想折腾太多,只想能当作普通备用机就行了。网上到处搜罗了一下,刷机什么的就不想干了,打算用最简单的安装应用来实现。
V91版本开启USB调式是输入*#*#5858#*#*,其他版本可以自行上网搜索。
开启USB调式以后,需要安装一个第三方市场,因为口袋阅本身是不允许下载应用的。最简单就是电脑安装豌豆荚,然后连接手机,这样就装上了豌豆荚手机端。以后要下载网页的apk是可以通过豌豆荚的。当然,我又通过豌豆荚装上了酷安。
下面说一下变身需要的两个重要软件:
1、Button Mapper Pro
2、E-ink Launcher
两个App的作用已经通过名字体现得淋漓尽致了。首先通过酷安把 E-ink Launcher 安装好。然后可以在电脑上下载 Button Mapper Pro,拷贝到手机内存中,然后通过任意市场找到apk来安装。
接下来的设置有点复杂,主要关于 Button Mapper Pro:
首先在打开App以后,会进入无障碍设置:
1、点击最下面的 去设置
2、点击 音量键快捷方式
3、打开
4、点击 快捷方式服务
5、点击 Button Mapper
6、点击 确定
7、返回
8、点击 屏幕锁定时也可以用
9、返回
10、点击 Button Mapper
11、打开
然后进入 Button Mapper 进行详细设置:
1、点击主页键
2、打开自定义
3、点击 单击
4、点击 操作
5、点击 大约第二个选项的位置
6、选择 E-ink Launcher
7、点击最近应用按键
8、打开自定义
9、再点击 单击
10、点击 大约第一个选项的位置
11、选择 最近
这样,大功告成,基本实现了日常机的需求。
如果对省内存有要求,还可以通过禁用QQ阅读来节省运存
1 | adb shell pm disable-user com.yuewen.cooperate.ekreader |
首先网站使用了let’s encrypt的免费证书,然后使用了百度云加速进行cdn加速,最后,网站使用了wordpress作为cms管理。
证书本身没有问题,wordpress肯定也没有问题(之前运行得好好的),那么锅可能会在百度云加速。
经过简单的尝试,只要把ssl证书添加到百度云加速控制面板的证书列表中,再打开安全设置的https加密即可(建议使用全程加密)。
记录一下,备忘。
]]>首先,安装npm包:
npm install --save hexo-helper-live2d
然后在hexo的配置文件_config.yml中添加如下配置,详细配置可以参考官方文档:
1 | live2d: |
然后下载模型,模型名称可以到模型仓库参考,一些模型的预览可以试试这个博客。
最好使用npm命令安装对应的模型包,例如:
npm install live2d-widget-model-shizuku
所有模型列表如下:
确实还是挺好看的。
)
当然我也一直在思考这个小程序能不能再多为班上提供点什么便利的服务?比如上线几天后,就增加了基于语雀接口的资讯模块。
要说一开始想到的是资讯,不如一开始想到的其实是图片和视频分享。但是说起来容易,做起来肉疼。图片和视频托管都是白花花的银子。从一开始我就没有想过要靠这个挣一分钱(当然也没想过要往里投入什么钱)。所以其实寻觅这个功能的实现方式,花费了相当长的时间。
第一时间想到的自然是各个对象存储,因为大部分都有免费额度,但是因为自己是基于无服务端开发,不想再去敲服务端代码了,哪怕只有简单几行。第二考虑的是国内非常有名的免费图床:sm.ms,但是恰逢去年改版,目前已经不允许客户端直接访问,必须服务端验证身份,所以也只有放弃。当然也有想过已经用上的语雀服务,但是语雀虽然提供了资源知识库,却并不提供相关接口,也就此放弃。
最后很幸运的碰到的imgur,一个令人难以置信的高质量图床,提供免费的空间和各种功能,以及丰富的api。当然有一点很关键:该服务在墙外。
首先记录一下如何使用api,方法基本来自于这篇博客:https://letswrite.tw/imgur-api-upload-load/。
其实如果只是get方法,而且要获取的内容都是public的,那这步完全可以简化。因为用CLIENT_ID就可以通过验证了。
但是如果是私有或者说要上传,那对不起,这步是最麻烦的。
先列举一下需要的链接:
Imgur api 说明文档:https://apidocs.imgur.com/
Imgur app 注册:https://api.imgur.com/oauth2/addclient
Postman 下载:https://www.getpostman.com/
Authorization type 选择第二个不需要回调 URL。输入email后点击submit,就可以看到 App 的 ID、secret。记下scret,这个只出现一次,服务端不保留,之后只能重新生成。
了解注册过程的朋友们先不要开喷,因为这就是我的操作步骤。接下来,把之前没有填写的回调URL给补上……在Redirect那里,填写https://www.getpostman.com/oauth2/callback。

然后点击update。
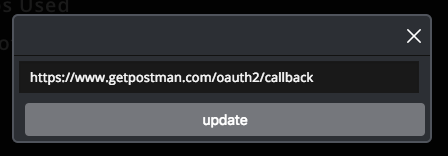
打开Postman,新建请求页,授权type选择OAuth2.0,然后点击Get New Access Token。
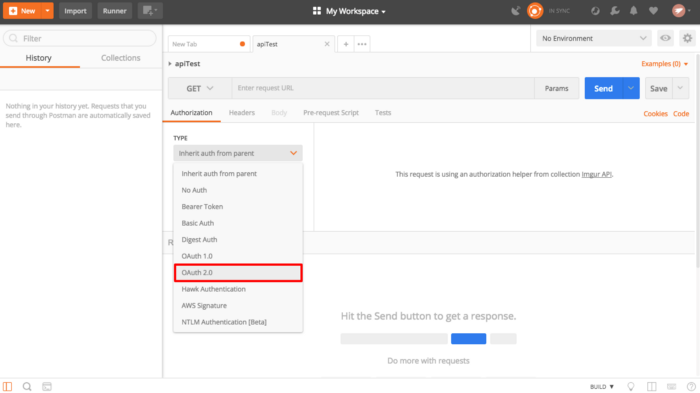
在弹出框中填写以下信息:
Callback URL:https://www.getpostman.com/oauth2/callback
Auth URL:https://api.imgur.com/oauth2/authorize
Access Token URL:https://api.imgur.com/oauth2/token
Client ID、Client Secret:这个应该记录下来了,直接填入就是
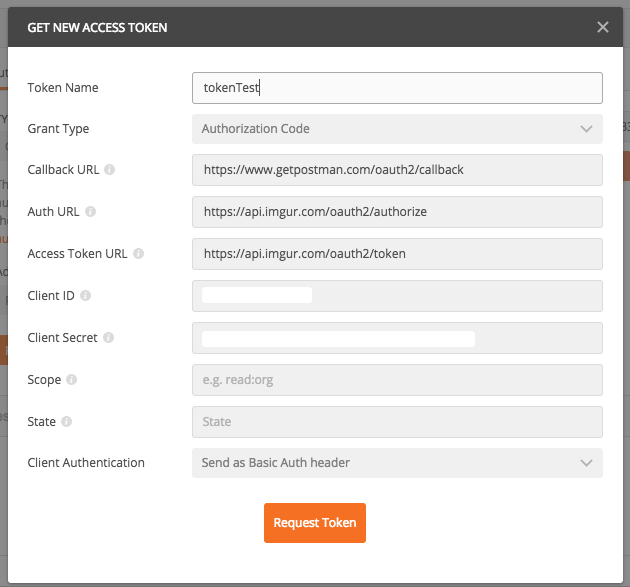
点击 Request Token,就弹出 Imgur 的登录框。注意,要命的地方来了。
如果你是邮箱注册,那么恭喜你,直接就可以登录,然后获取到token,就像下图一样。
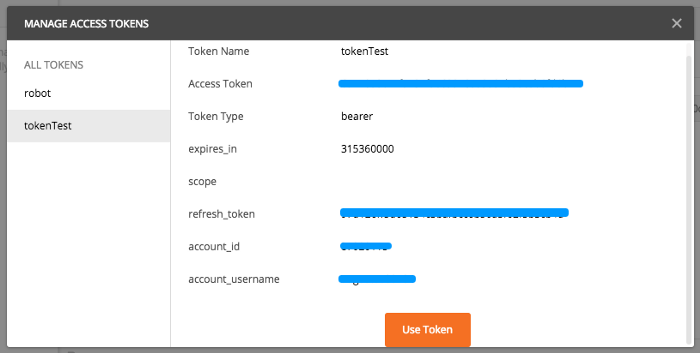
如果你是第三方授权的,那么也恭喜你,回到你的浏览器网页,退出登录,选择忘记密码,重新设置密码以后,才可以在刚才的登录框里登录。
记得记下Access Token,否则还得再做一遍刚才的事情。
因为我目前不使用上传接口,都是直接使用imgur的后台上传,所以直接进入下一阶段,获取内容:
1 | const id = 'YOUR-CLIENT-ID'; |
真是非常感恩有这样优秀的服务,也感谢语雀,使得无服务端的小程序得以实现。
PS:关于怎么能正常的在国内使用这个服务,可以留言跟我交流。为了所有希望正常使用该服务的朋友还可以享受一段时间,就不在这里po出来了。也恳请所有正在使用imgur的朋友积点德,把这么好的服务用到正道上。
]]>电脑上安装的是beyond compare 4,但是因为很久没用了,早过了评估期。
度娘了一下,临时解决方案也挺简单的。
1、window+R打开管理,输入regedit
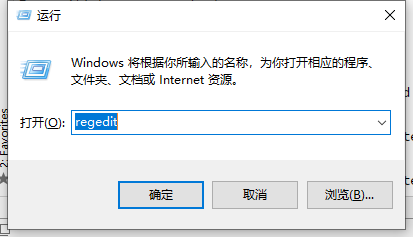
2、注册表中找到 HKEY_CURRENT_USER\Software\Scooter Software\Beyond Compare 4 ,找到其中的 CacheID,删除掉
3、找到 beyond compare 安装路径中的BCUnrar.dll, 删除
再次打开就可以使用了!
PS: 有条件还是使用正版吧,毕竟开发不易,大家都要吃饭的。
]]>于是立马打开gitlab开始编辑,然后就有了这篇简单的博客。
也就是说,之前定的计划里,在线编辑文章,并且自动发布,也完全可以实现了。
最后只剩下如果移动设备编辑的时候,没有办法实现图片上传cdn了。
以后再思考怎么来实现了。现在已经方便了很多。
]]>但是在装完系统以后又出现了更悲催的事情——打开word文档一直不断的弹出提示“由于你的缓存凭据已过期,我们无法上载或下载你的更改”或“无法保存或检查所做修改,因为缓存的凭据已到期,请重新登录”的警告。
这不仅仅只是影响了视觉,关键每修改一个字或者保存一次,都要卡顿很长的一段时间,完全没法工作。
轻轻度娘,就找到了解决方案:https://blog.haitianhome.com/onedrive-office-huancun-pingju.html
罪魁祸首是onedrive里多此一举的“文件协作”功能。按文章作者的理解,onedrive好心的去同步保存office的文件,但是因为是云操作,文件不能及时上传,所以就挂起操作,这个时候office就会弹出警告;当上传后,office的警告就消失了,因为是协作需要不断查询、保存的操作,于是就重复弹出“缓存的凭证到期,无法保存修改”的警告。
在onedrive将“文件协作”功能关闭,然后重启Office软件。
进入onedrive“更多”—“设置”,点击“office”项卡,把文件协作下“使用Office应用程序同步我打开的Office文件”前的勾去掉即可。
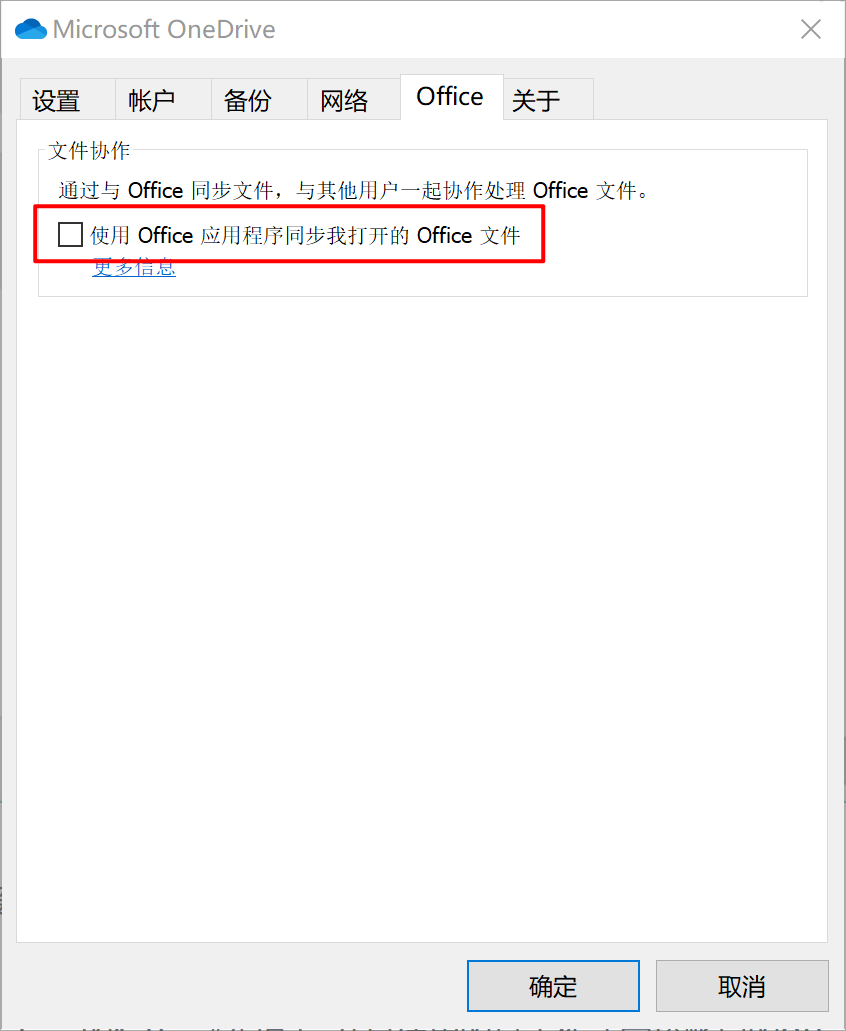
重启Office即可解决“缓存的凭据到期,无法保存修改”的警告问题。
]]>这样减少了相当多的人力工作。
主要分为两个过程:
第一步很关键,但是也很简单。创建GitLab私有仓库以后,在项目根目录添加.gitlab-ci.yml配置文件,以便上传代码后GitLab CI使用。
其中有两个关键点。第一个是标记expire_in,不然会自动删除的。第二个是我这里配置了分支是master,这个依自己情况而定。
1 | # This file is a template, and might need editing before it works on your project. |
自动部署这个折腾了很久。先描述过程,后面再说自己挖的坑。
增加FTP服务器配置后,.gitlab-ci.yml配置文件如下:
1 | # This file is a template, and might need editing before it works on your project. |
上述配置已更新为下面内容 (相关链接 解决Hexo使用GitLab持续集成部署阿里云虚机lftp无法全部完成的问题 )
1 | # This file is a template, and might need editing before it works on your project. |
大致流程是先安装lftp工具,再上传。特别注意,这里为了不在代码中暴露关键信息,使用了$USERNAME $PASSWORD $HOST来获取CI/CD中提前配置好的变量值。
这个坑嘛,估计无人能懂。一开始部署的时候,觉得好像没有什么问题,但是最后生成的文件都是0kb。想着应该能有输出吧。
上CI/CD日志一看,一脸懵逼,居然说没有layout,那指定是主题出问题了。
突然想到自己的主题原来是拿去做了开源项目给大家使用的,一检查,原来是作为submodule放在这个项目中的,所以没有上传到仓库去。最后依照这篇文章的方法去掉了submodule,一切恢复正常。
https://www.jianshu.com/p/7acb3a2fc05c
世上本没有坑,倒腾的次数多了,自然就挖好了坑。

怎么回事呢?因为站点用的是前些年淘到的超便宜万网云虚机,一年才50多块钱。在使用静态博客时,完全没有任何问题,轻松应对各种压力。
但是换到wordpress以后,问题出来了,不知道是高版本wp还是别的插件问题,仅仅切换7天,服务器被阿里云关闭2次——因为资源使用超标了。
这就尴尬了,是不是?
所以呢,在第二次被关闭后,毅然决定换回hexo。但是我并没有忘记当初为什么要抛弃hexo,所以以下的问题必须要一一解决才行。
这个应该是要分两个步骤,分别是:1、可以脱离webstorm一类的ide,使用在线编辑器写作;2、可以脱离对pc的依赖,使用任意设备随时写作。目前实现了第1个目标,很简单,几行命令解决问题。
1 | $ npm install --save hexo-admin |
这个其实才是想切到wordpress最根本的原因,由于静态博客无法记录动态数据,因此一开始就完全依赖于第三方社会化评论。然而第三方评论的陆续退出,使得以前辛苦积攒的评论化为泡影。
后来一度使用了gitment。说实话,并没有什么不好用的。但是访问博客的人未必拥有github账号,而github的可访问性在一段时间内也让我充满了疑问。
得益于互联网技术和开源库的发展,Hexo也有更加适合国内环境的评论系统出现。比如我目前所使用的valine。
配置起来非常容易,请参考这篇博客:hexo 博客增加Valine/gitalk评论插件
这是一个附加题目。人毕竟都希望能缩短做任何事情的时间,以便有时间拓宽或者延申到自己希望的领域中去。如果需要打开一个网页或者特定的管理工具,还要选择目标地址,选择图片上传,未免也太耽搁时间了。hexo-admin 其实已经做到了这点,只是还不够多。它只能快捷的将图片放置到/img文件夹中,无法实现上传CDN。
目前也还没有找到完美的解决方案,但是PicGo这个项目已经能比较方便的与hexo-admin配合使用了。
访问这个网址即可:https://github.com/Molunerfinn/PicGo
先这样,以后有时间研究新的配置方案再更新。
]]>这次转回WP还是花了不少功夫,主要是在导出文章上。
长话短说,看看导出导入文章都需要做些什么。
1、从Hexo导出feed。首先在站点的_config.yml配置文件中找到feed节点,确保配置如下:
1 | #feed |
2、使用 hexo g 或者 hexo server 生成atom.xml文件。
3、在搭建好的WP中安装 feedwordpress 插件,并进行同步操作。(完全不用担心插件兼容性,跟5.x版本的WP完美兼容)
导入后的文章会比较混乱,主要体现在以下几个方面:
1、原来的标签都被当做分类了。这个时候只能耐心的删除所有分类,并重新添加。然后加上分类标签。
2、语义式的文章链接全部丢失,需要重新给所有文章修改别名。
3、代码高亮需要重新配置,WP默认code标签的解析不是好不好看的问题,是根本不能看。逐篇文章检查……要死要死……
轻易确实不打算再换环境了,年纪一把,折腾不起了。
]]>近来HybridApp需要更新的情况下,我都尽量在往DCloud迁移了,毕竟人家是团队维护的框架,稳定性更有保证。但是也发现了一个很蛋疼的地方,Dcloud不支持修改targetSDKVersion,但是客户的需求最高啊。总不能为了修改一个targetSDKVersion,专门去维护一个android studio版本吧。
谷歌了一下,果然很快找到方法,原文在此:http://www.saycoding.cn/portal/article/detail/1526895431139400
流程如下:
#1、下载 apktool
https://ibotpeaches.github.io/Apktool/install/
下载前两个 apktool.bat 和 apktool.jar
将两个文件放到一个目录内命名为 apktool
#2、解压apk
将 target.apk 放到文件夹 apktool 内
1 | cd apktool |
执行成功后 目录下生成 target 包 找到 apktool.yml 打开文件
找到
1 | sdkInfo: |
修改 targetSdkVersion 为 26
#3、重新打包
生成文件:
apktool b target -o new_target.apk
完事,然后该签名签名,改加密加密就好了。不知道有没有后患,测试起来没什么问题,先解决当下的困难吧。
]]>1 | +-- react-redux@5.0.5 |
很奇怪,因为感觉这些东西都相对成熟了,怎么还会出现依赖问题呢?
Google了一下,解决方法在此:https://github.com/poetic/meteor-reacterminator/issues/33
大概描述一下:
1、打开package.json,在依赖部分写入
1 | "redux": "^3.5.2" |
2、命令行进入项目,输入下面命令单独安装redux
1 | $npm install --save redux |
3、再次安装react-redux
1 | $npm install --save react-redux |
完工!
]]>有点兴趣研究一下react-native,于是需要更新android sdk。但是这次用东软的代理地址更新相当慢,而且总出错。索性上网打算再找一个靠谱一些的。
度娘的姿势你懂的,翻来覆去就那么几个答案,幸好还是发现了一个与众不同的。
腾讯Bugly镜像
访问地址:http://android-mirror.bugly.qq.com:8080/include/usage.html
使用方法都懂的:
1、打开Android SDK Manager,点击Tools -> Options…。在代理服务器和端口处分别填入“android-mirror.bugly.qq.com”和“8080”。记得要勾选“Force https://… sources to be fetched using http://…”

2、检查一下代理是否正常,点击Package -> Reload。

OK! Have fun~
]]>现在有所变动了,时间上也宽裕了很多,陪陪家人之余,也再多记录点东西。
这两天抽空又折腾了一下博客,发现nodejs,hexo各种更新,原来没什么问题的博客也各种出错。索性删了几篇,懒得折腾。
在操作命令行时,突然觉得一直Win+R,然后cd到需要的目录去是一件很sb的事情。在ubuntu和osx下都可以很方便的在文件夹中打开命令行工具,立马想看一看windows行不行。于是打开博客目录,点了一下鼠标右键。

呵呵,什么都没有。
好吧,我还是去度娘了一下,居然答案很少,没有人转载吗?最后在 这个博客 找到了答案。
只需要在点击鼠标右键时,按住Shift,就会出现“在此处打开命令窗口(W)”的选项,真是方便多了!

但是git有个很烦的问题,没有在明显的位置提示可以保存密码,所以一直以来都忍受着不断输密码的痛苦。
昨天Fenix跟我说他保存上密码了,但是不记得怎么做的,于是出于学(xian)习(mu)新(ji)知(du)识(hen)的积极心态,我自己也上度娘走了一圈,找到了如下方法
方法一:
设置 -> git 编辑本地 .git/config 增加
[credential] helper = store 保存,输入一次密码后第二次就会记住密码了
方法二:
Windows中添加一个HOME环境变量,值为%USERPROFILE%在“开始>运行”中打开%Home%,新建一个名为“_netrc”的文件用记事本打开_netrc文件,输入Git服务器名、用户名、密码,并保存:machine github.com #git服务器名称login user #git帐号passwordpwd #git密码在windows上建_netrc
copy con _netrc #创建_netrc文件#依次输入以下3行:machine github.com #git服务器名称login username #git帐号password password #git密码在最后一行后输入ctrl+z,文件会自动保存并退出
再次在git上提交时就不用重复输入用户名密码了
]]>Build、Clean等等神马按钮都是灰色的,不能点击。研究了一会,没找到问题的症结所在,所以直接谷哥了,得到的解决办法很简单:
点击菜单上的Project
选择New Schemes…
直接使用默认值
done了。
估计在导出Xcode项目的时候,程序还在使用老的配置文件。
]]>度娘了一下,步骤蛮简单的:
#第一步:列出uuid
运行cmd,执行命令
1 | VBoxManage list hdds |
得到uuid。
#第二步:修改磁盘大小
例如需要修改为60G:(修改大小前,要关闭所要修改的虚拟机)
1 | VBoxManage modifyhd 虚拟机的uuid --resize 60000 |
本方法只支持VDI格式
]]>.gitignore文件成了必然。项目目前只需要将Assets文件夹纳入版本控制即可(后期可能也会将ProjectSettings纳入管理)。
如果还需要将ProjectSettins纳入管理,在编写.gitignore文件前,可以进行以下几步,将设置以文本形式存储以利于版本控制(有利有弊,自己权衡):
1.在 Edit->Project Settings->Editor->Version Control Mode 中选择 Visible Meta files。
2.在 Edit->Project Settings->Editor->Asset Serialization Mode 中选择 Force Text。
3.保存场景和项目。
下面是一份参考的.gitignore文件:
1 |
|
折腾了好几天,终于用上了,但是也有非常恶心的事情,那就是使用ng-repeat造成的卡顿。
AngularJS的ng-repeat一直都让我感觉非常方便,可以很轻松的遍历数组生成Dom元素。但是,少量的绑定增加就会带来更大的多的$digest循环开销,从指令方面来说,创造一个可能的静态渲染组件,并在真正需要外都独立在Angular监控体系外是相当有用的,应该保持对隐式创建的watch对象的留心。比如在想好应用结构、coding前关心一下自己可以减少多少个watchers。
也许最终的计算器会脱离AngularJS框架,毕竟它还是适用于SPA,而且对安卓机还是有些挑剔。
]]>玩了一下,居然点亮了大部分,原来我已经这么腻害了么,嚯嚯嚯嚯~
我的链接:http://skill.phodal.com/#_a2b2cde3fh3i2jkmr2s2tuvwxy2_1_GSGundam
话说有Github帐号的童鞋应该填入自己的用户名哦,可以直接抓取头像的。
慢,难,险,都不是问题,只要还在前进。继续学习!

Google就不用想了,原因大家都懂。百度站内搜索一直没能成功实现,原因不明,也懒得找明,只有指定域的方法可行。
一早听说了Swfitype这枚神器,但是始终没腾出来时间研究。随便百度时无意找到了这篇文章(http://www.jerryfu.net/post/search-engine-for-hexo-with-swiftype.html),才好好研究了一下。
原文引导作用很好,就是有若干处错误,所以在下干脆就重新整理了(图均借用了原文)。
虽然本文是基于自己的主题Gacman(当然,也完全适用于Jacman和Pacman),但是其实各个主题都大同小异。先展示一下效果吧:我要搜索“装甲纵队”
首先前往Swiftype的官网https://swiftype.com注册一个账号,然后根据指引建立好自己网站对应的索引。
然后切换到install面板,如下图:

进入安装面板后需要先配置一下自己的站点,按照下图的配置来操作:

其中的网址注意把www.jerryfu.net部分替换成自己的网址。
然后点击配置界面左侧的“SWIFTYPE INSTALL CODE”来获取所需要的js代码,获取类似下边的代码:
1 | <script type="text/javascript"> |
直接把这段代码拷贝到主题目录中layout_partial的footer.js或者header.js中,以保证每个页面都运行了Swiftype代码。可以考虑加上判断条件,比如下文的if(theme.swiftype.enable)。
在主题下的_config.yml文件中添加如下代码(注意不要打断其它配置,可以考虑加在自定义搜索附近或干脆文件最后),增加一个swiftype的配置选项:
1 | swiftype: |
然后到Hexo根目录中的source目录下建立一个search文件夹,再在其下建立一个index.md,index.md中写入如下代码:
1 | layout: search |
然后到主题目录中layout_partial目录下打开header.ejs,在搜索模块的各条件之间添加一个条件(这里的class样式是Gacman特定的,各个主题都应该用自己的):
1 | <% } else if(theme.swiftype.enable){ %> |
还是layout_partial目录,打开search.ejs,同样是为Swiftype增加一个条件:
1 | <% } else if(theme.swiftype.enable) { %> |
嗯,这样就完成了。hexo g,hexo d,all done~
最关心的就是重要他人部分。因为我和阿宝一直认为一个人的性格、个性就是来源于他的成长环境,而这很大程度上决定了他的命运。在这个人文环境中影响最大的就是重要他人。重要他人的缺失和错误影响,都将会是难以挽回的遗憾。
这部分找到了一篇非常不错的文章,作了一些摘录和修改。
在生命的最初几年,对个体产生重要影响的人物无疑就是我们的父母。一般来说,在个体离开家庭,上幼儿园和小学之前,父母对孩子的影响无可替代。可以说,在这个时候,也是做人家父母最舒服的时候,自身权威意识膨胀,孩子的崇拜也无限。
在埃里克森看来,人生发展的第一个阶段所要解决的任务,就是基本的信任感和不信任感,这个时间大致从出生到1岁之间。此时的我们,由于能力有限,主要的活动只有一项,吃奶,这也是我们当时快乐的源泉。而母亲则是满足我们需要的最重要的人物,我们的生存和幸福都依赖于她,我们与母亲的交流,是我们最初的人生经验。
根据埃里克森的观点,如果我们遇到的是一位慈爱而敏感的母亲,她能敏锐地感知到我们的需要,在我们需要的时候能出现在我们身边。那么,我们就会形成对世界的一种满足和信任,觉得自己不是无助的,他人是可以信任的。即使母亲某一时候不在我的身边,我也不用担心,因为和她接触的经验告诉我,只要我需要她的时候,她是会按时出现的,我们不必焦虑和烦躁,安心睡我们的大觉就是了。一位慈爱而敏感的母亲,喂养出来的是一个对他人具有充分信任感的人。
但是,如果我们遇到了一位粗心大意的母亲,有的时候她高兴了就让我们喝点奶,有的时候不高兴我们怎么哭都没有办法,我们就是在这种饥一顿饱一顿的环境中成长。如果这样,我们会觉得母亲的行为是不可预测的,这个世界也是不可信任的,母亲离开的时候我只有大声哭喊,因为我不知道她什么时候才回到我们身边。一位粗心大意的母亲,喂养出来的是一个对世界充满怀疑和不信任的人。
补充
这个时候需要的是一对理智、清醒、慈爱的父母。对于男孩来说,父亲教会他如何与同性相处、希望自己成为什么样的人,而母亲则教会他如何与异性相处、将要选择什么样的配偶。对于女孩来说则相反。孩子将体会到他人是否值得信任,人生是否无助。在这个时期,孩子也将初步形成对权威的态度。
当孩子们飞速中成长为一名小学生的时候,父母的权威地位无疑被孩子的老师所替代。说起来,和大学、中学老师比较起来,不见得小学老师的水平是最高的,但论起在学生心目中的地位,却绝对非小学老师莫属。所有的小学生都有一句口头禅,“我老师说……”。
然而,可以肯定的是,影响大,责任也大。小学老师从当老师层面来讲是最牛的,说什么话学生都相信。但也正因为如此,小学老师麻烦事做多,因为小学生相信你,什么事情都告老师。小学老师是好当的,因为我们正赶上了孩子把老师作为最权威人物所推崇的时候;小学老师也是难当的,因为我们不小心的一句话,可能伤害的是学生的一辈子。
补充
这个时候需要的是至少一位负责、理性、有爱心的老师。权威是个什么样的概念?该怎样对待权威?怎样与权威进行交流?这个时期的老师将告诉孩子们。
处在青春期的中学生们,在放弃了自己的母亲和老师为权威人物的时候,他们会更为重视自己的友谊,他们更为重视的是自己能否在同龄人群体中找到共鸣,能否得到朋友的认可。这个时候,对他们影响最大的人可能不是老师和父母,而是自己的铁哥们和铁姐们。也正是在这个时候,老师的权威容易遭受到挑战,他们在学生心目中的威信也很难建立起来。面对着一群处在“暴风骤雨”阶段的年轻人,作为他们的老师,也是很难有所作为的。如果青春期的孩子,再碰上更年期的家长或老师,那可真是充满了戏剧性的冲突。
补充
这个时候需要的是至少一位正直、善良、友好的亲密好友。他们之间的交流模式会教会他如何与同龄人相处,是否应该信任周围人等等。
如果生命历程比较平稳,顺利地升到了大学,这时候朋友对于个体而言还是很重要的,但这时朋友有了分化,朋友具有更强的选择性,尤其是,当谈了场恋爱的时候,恋人的影响就更大了。人生在哪个阶段最容易“重色轻友”,答案很明显,就是大学阶段。
当大学生谈起一场恋爱,给人的感觉有时候就像参加了邪教组织,或者“被传销”一样,精神亢奋而又迷迷糊糊。为了亲密的爱人,他们可以对周遭的一切视而不见。处在这个阶段,爱情使他们忘记了一切清规戒律。
补充
这个时候需要的是一位能够分享、也能够分担的恋人。嗯,没什么好说的了,这就是为谈婚论嫁铺路,所有的经验都将在最后的婚姻里体现。
大概这样就结束了……吗?我个人还有一点看法,其实后三个阶段的选择,很大程度上在第一个阶段就已经决定了。所以父母至关重要。当然,重要他人只是头把交椅的相互替代,而不是从生命中消失。所有提到的这些重要他人、以及没有提到的(尤其在一些重要他人缺失的情况下),都会对人格发展产生影响。
这部分是在寻找重要他人的时候带出来的问题,算是相互补充吧。虽说他的理论并不是所有人都认同,毕竟临床观察有主观成分,可能有失偏颇,但同时我个人还是觉得非常有参考价值。下面内容均来自度娘。
埃里克森的人格发展理论把个体自我意识的形成与发展划分为八个相互联系的阶段。

从出生到十八个月左右是婴儿期。这是获得基本信任感而克服基本不信任感阶段。所谓基本信任,就是婴儿的需要与外界对他需要的满足保持一致。这阶段婴儿对母亲或其他代理人表示信任,婴儿感到所处的环境是个安全的地方,周围人们是可以信任的,由此就会扩展为对一般人的信任。
婴儿如果得不到周围人们的关心与照顾,他就会对外界特别是对周围的人产生害怕与怀疑的心理,以致会影响到下一阶段的顺利发展。
从十八个月到三、四岁是童年期。这是获得自主感而避免怀疑感与羞耻感阶段。个体在第—,阶段处于依赖性较强的状态下,什么都由成人照顾。到了第二阶段,儿童开始有了独立自主的要求,如想要自己穿衣、吃饭、走路、拿玩具等,他们开始去探索周围的世界。这时候,如果父母及其他照顾他们的成人,允许他们独立地去干一些力所能及的事情,并且表扬他们完成的工作,就能培养他们的意志力,使他们获得了一种自主感,能够自己控制自己。
相反,如果成人过分爱护他们,处处包办代替,什么也不需要他们动手;或过分严厉,这也不准那也不许,稍有差错就粗暴地斥责,甚至采用体罚。例如,孩子由于不小心打碎了杯子,尿湿了裤子,成人就对其打骂,使孩子一直遭到许多失败的体验,就会产生自我怀疑与羞耻之感。
四到五岁是学前期。这是获得主动感而克服内疚感阶段。个体在这阶段的肌肉运动与言语能力发展很快,能参加跑、跳、骑小车等运动,能说一些连贯的话,还能把自己的活动扩展到超出家庭的范围。除了模仿行为外,个体对周围的环境(也包括他自己的机体)充满了好奇心,知道自己的性别,也知道动物是公是母,常常问问这,动动那。这时候,如果成人对于孩子的好奇心以及探索行为不横加阻挠,让他们有更多机会去自由参加各种活动,耐心地解答他们提出的各种问题,而不是嘲笑;禁止,更不是指责,那么,孩子的主动性就会得到进一步发展;表现出很大的积极性与进取心。
反之;如果父母对儿童采取否定与压制的态度,就会使他们认为自己的游戏是不好的,自己提出的问题是笨拙的,自己在父母面前是讨厌的;致使孩子产生内疚感与失败感(所谓内疚感,就是认为自己做错了事情,做坏了事情),这种内疚感与失败感还会影响下一阶段的发展。
从六岁到十一、二岁是学龄初期。这是获得勤奋感避免自卑感阶段。学龄初期儿童的智力不断地得到发展,特别是逻辑思维能力发展迅速,他们提出的问题很广泛,而且有一定的深度。他们的能力也日益发展,参加的活动已经扩展到学校以外的社会。这时候,对他们影响最大的已经不是父母,而是同伴或邻居,尤其是学校中的教师。他们很关心物品的构造、用途与性质,对于工具技术也很感兴趣。这些方面如果能得到成人的支持、帮助与赞扬,则能进一步加强他们的勤奋感,使之进一步对这些方面发生兴趣。 埃里克森劝告做父母的人,不要把孩子的勤奋行为看作为捣乱,否则孩子会形成自卑感,认为自己不如别人,应该鼓励孩子努力获得成功,努力完成任务,激发他们的勤奋感与竞争心,有信心获得好成绩;还要鼓励他们尽自己最大努力与周围人们发生联系,进行社会交往,使他们相信自己是有能力的、聪明的,任何事情都能做得很好,即使是参加赛跑,也会认为自己是跑得很快的。总之,使他们怀有一种成就感。
从十一、二岁到十七、八岁是青春期。这一阶段的核心问题是自我意识的确定和自我角色的形成。
“同一性”这一概念是埃里克森自我发展理论中的一个重要组成部分,它具有非常广泛的含义。它可以理解为社会与个人的统一,个体的主我与客我的统一,个体的历史性任务的认识与其主观.愿望的统一;也可理解为对自己的过去、现在和将来,即在任何情况下都能够全面认识到意识与行动的主体是自己,或者说能抓住自己,亦即是“真正的自我”,也可称为“核心的自我”。
青少年对周围世界有了新的观察与新的思考方法,他们经常考虑自己到底是怎样一个人,他们从别人对他的态度中,从自己扮演的各种社会角色中,逐渐认清了自己。此时,他们逐渐疏远了自己的父母,从对父母的依赖关系中解脱出来,而与同伴们建立了亲密的友谊,从而进一步认识自己,对自己的过去、现在、将来产生 ——种内在的连续之感,也认识自己与他人在外表上与性格上的相同与差别。认识自己的现在与未来在社会生活中的关系,这就是同一性,即心理社会同一感。
埃里克森认为,这种同一感可以帮助青少年了解自己以及了解自己与各种人、事、物的关系,以便能顺利地进入成年期。否则就会产生同一性的混乱。如:怀疑自我认识与他人对自己认识之间的一致性;做事情马虎,看不到努力工作与获得成就之间的关系。同一性混乱,还表现在对领导与被领导之间的共同点与差异看不清,要么持对立情绪,要么盲目顺从等。在两性问题上也会发生同一性的混乱,认识不到两性之间的同一与差异等。
从十七、八岁至三十岁是成年早期。这是建立家庭生活的阶段,这是获得亲密感,避免孤独感阶段。亲密感,是人与人之间的亲密关系,包括友谊与爱情。亲密的社会意义,是个人能与他人同甘共苦、相互关怀。亲密感在危急情况下往往会发展为一种互相承担义务的感情,它是在共同完成任务的过程中建立起来的。
如果一个人不能与他人分享快乐与痛苦,不能与他人进行思想情感的交流;不相互关心与帮助,就会陷入孤独寂寞的苦恼情境之中。
这是中年期与壮年期,是成家立业的阶段。这是获得创造力感,避免“自我专注”阶段。这一阶段有两种发展的可能性,一种可能是向积极方面发展,个人除关怀家庭成员外,还会扩展到关心社会上其他人,关心下一代以至子孙后代的幸福。他们在工作上勇于创造,追求事业的成功,而不仅是满足个人需要;另一种可能性是向消极方面发展,即所谓“自我专注”,就是只顾自己以及自己家庭的幸福,而不顾他人的困难和痛苦,即使有创造,其目的也完全是为了自己的利益。
这是老年期,亦即成熟期。这是获得完美感,避免失望感阶段。如果前面七个阶段积极的成分多于消极的成分,就会在老年期汇集成完美感,回顾—生觉得这一辈子过得很有价值,生活得很有意义。相反,如果消极成分多于积极成分,就会产生失望感,感到自己的一生失去了许多机会,走错了方向,想要重新开始又感到为时已晚,痛不胜痛,于是产生了—.种绝望的感觉,精神萎靡不振,马马虎虎混日子。
埃里克森在分析每个阶段肘,都提出一些积极的建议。例如,他认为,一个人不应该对任何人都信任,不信任感也有一点用处,有了不信任感后,对于外界的危险会有一种准备,对于外界不愉快的事情可有一种预期,否则一遇社会挫折就感到不可思议或束手无策,不利于自我的成长。但埃里克森认为,在人际关系中信任与不信任感要有一定的比例,信任感应该多于不信任感,以有利于心理发展。
他还认为,自主感也不能无限制地发展,也必须有—定的怀疑感与羞耻感,如果过分相信自己,以后就不容易适应社会准则,变得独断孤行。埃里克森认为,自主感应强于怀疑感与羞耻感。儿童的勤奋感中也应该有一点失败的经验,以便今后能经受住失败的挫折,但又不能过分地经常地遭受失败,经常失败就会产生自卑感。
以上是埃里克森自我发展的八个阶段,从中可以看到自我的形成与社会文化因素的关系,也可以看到自我与社会生活在个体人格发展中的作用。他的八个阶段是他临床经验的总结,尚缺乏严格的科学事实作依据,但比起弗洛伊德强调本能的生物学观点来,侧重了社会文化因素在自我意识形成与发展中的作用,他的理论有相对的合理性,在西方心理学界有相当大的影响。
有研究表明,埃里克森自我发展的八个阶段在具体的年龄段上的划分有些偏前,因此如果我们看到自己所属的心理发展阶段小于自己的生理年龄时不必沮丧。
最后习惯性吐个槽。现在再回头看有些理论,真是描述得太不容易推广了。在我看来,心理学应该是一门值得被普及的科学,它其中的一些常用知识理论应该被描述得浅显易懂,而不是靠晦涩的专业术语来突显自己的地位。这对大众和心理学自己都是有利的。
]]>但是作为一个Hybrid应用,还能怎么样呢?Wishwolf建议我还是把浏览器内核打进安装包里,用体积换性能,起码给客户的体验要好些。
在这个项目之初就试过把Crosswalk打包进安装包里,单是支持Arm平台,安装包就活生生的增加了20mb,但是20mb换来的性能提升实在是微乎其微,所以放弃了。
先说说这次的结果吧,给看官们一点信心。
这次打包的是Cordova Crosswalk (ARM) 10.39.235.15 Stable,Chromium内核版本39,禁用js scrolling而改用native scrolling。
实测结果:
4.4版本以下系统,性能明显提升,页面滚动流畅度大大提升,页面切换卡顿感减少。
4.4版本以上系统,性能稍有提升,页面滚动流畅度稍有提升,页面切换卡顿感减少。
5.0系统版本模拟器,性能提升很少,页面滚动流畅度有改观,页面切换无变化。
安装包体积增加约18mb。
怎么样?会不会觉得这点体积还是换来了不少价值?
提升的原理自然是很明显的,4.4版本以下的系统使用的是Webkit内核,从4.4开始才使用Chromium内核,而5.0系统也不过使用了Chromium 37内核,这里直接换成了Chromium 39,性能提升不言而喻。
其实打包并不难,关键是中途有各种坑供大家踩,为防止老年痴呆提前发生,先把自己打怪升级的过程(踩过的两个大坑)记下来。
1、第一坑:ionic cli 1.3.2 开始官方支持使用cli直接打包。
1 |
|
作为一个官方脑残粉,一般官方提供了服务,哪怕他是alpha 0.0.1版我也愿意试试。嗯,果然不出所料上当了。
各种报错,各种调试。期间还改动过多次Crosswalk和android的版本,最后还是无奈放弃了。
2、第二坑:手动集成Crosswalk。
嗯,没错。就算是手动集成也有大坑。
首先,不要尝试cordova platform android@3.5.1以上的平台版本,纯属浪费时间。
第二,不要尝试Crosswalk 10.39.235.15 Stable以上的浏览器内核,纯属浪费时间。
好了,那么切入正题,说一说简单的集成步骤。
1、首先进入目录,创建3.5版本的android平台:
1 | $ cd yourproject |
2、删除 platforms/android/CordovaLib 目录中的所有内容:
1 | $ rm -Rf platforms/android/CordovaLib/* |
3、将解压好的Crosswalk目录中的 framework/ 所有文件拷贝到 platforms/android/CordovaLib 中(如果你实在需要同时支持arm和x86平台,那把两个该目录下的文件都拷进去就可以了。普通情况下,一般没必要为x86平台浪费那20mb体积):
1 | $ cp -a <path_to_unpacked_bundle>/framework/* \ |
4、将 VERSION 拷贝到Android项目根目录:
1 | $ cp -a <path_to_bundle>/VERSION platforms/android/ |
5、Crosswalk需要两个权限才能运作,如果你安装的插件里没有,那就需要手动在 platforms/android/AndroidManifest.xml 里添加一下。(我比较懒,直接在cordova官方插件network-information添加了android.permission.ACCESS_WIFI_STATE的需求)
1 | <uses-permission android:name="android.permission.ACCESS_WIFI_STATE" /> |
6、就要完工啦。按以下顺序编译项目:
xwalk_core_library
CordovaLib
kitchensink
1 | $ cd platforms/android/CordovaLib/ |
以上完成,恭喜你,不出意外的话,你的项目就可以跑起来了。
1、先按命令行方式创建3.5版本的android平台,然后打开ADT/Eclipse。
2、按导入Android Existing Android Code into Workspace 的方法,将解压好的Crosswalk中的 framework/ 文件夹导入ADT/Eclipse,会出现下面两个项目:
Cordova
xwalk_core_library
3、导入你的Cordova项目,导入过程中不要选择CordovaLib项目,因为我们要选择Crosswalk的Cordova包作为依赖。
4、右键点击主项目,选择 属性/Properties ,点击 Android ,点击 Add…/添加… ,这里要把 CrosswalkCordova 和 xwalk_core_library 项目都作为主项目的依赖库。添加完毕以后应该看起来像是这样的:
5、清理所有项目。
6、要完工咯。按以下顺序编译项目:
xwalk_core_library
CrosswalkCordova
your application project
这种方法也就完结啦。
最后小絮叨一个。为了适应最广泛的应用,cordova选择了支持对Html5单页面应用进行最好的支持。这不坏,网页前端攻城狮因此可以很快的转型为app前端开发,而且几乎没有学习成本,也能对原生略有了解。然而这不得不牺牲了很多优秀的原生体验,转而变成了“将就”。
Fenix已经对Android原生开发十分熟练,iOS原生也已经能做个大概。我做了好几个cordova项目了,也差不多该转型了,当然,纯粹的原生对我将是个很大的挑战。所以下一个项目应该是多页面应用作为过渡吧。比如Supersonic或者Apicloud。

这一系列问题硬生生的花了我四天时间绕着弯去想临时办法解决它们。但是到network-infomation和toast的时候实在是绕不过了,于是只好静下心来思考方法。
原来在用jqmobi的时候从来没有出过这个问题,那十有八九都是因为angularjs了。虽然并不知道具体原因,但是早就知道ngCordova这个项目,只不过之前的ionic app都只是离线展示的作用,没有涉及到这么多功能,因此觉得这个项目对自己用处不大。
但是这次不同了,整合只花了1个多小时,却解决了我4天熬夜都没搞定的问题。值得反省啊!
整合起来很简单,只要在angular.js/ionic.bundle.js之后、cordova.js之前引入即可。
1 | <!-- ionic/angularjs js --> |
将其作为Angularjs的依赖注入到module中。
1 | angular.module('myApp', ['ngCordova']) |
如此,前期工作就做完了,剩下的就是根据插件列表中所需要的内容来添加插件和代码了。
例如,我需要判断在线还是离线,比我自己写方法还要简单,直接这样就行了。
1 | $ionicPlatform.ready(function() { |
嗯,夫复何求。

作者是因为知乎上的一个问题而写了这篇文章和这个程序,使用HTML5+JS进行开发,可以将任意图片转换成WWDC2014海报的样式:用色调如彩虹般绚丽的圆角矩形来拼成原图。

我只想说,效果超乎想像。Canvas确实可以大有作为。
看官们就自行体验吧。
以下贴上所有代码:
HTML部分:
1 | <div id="toolbar"> |
CSS部分:
1 | body { |
Javascript部分:
1 | var canvas; //画布 |
消费者在既定的预算线约束 $ I = P_1X_1 + P_2X_2 $ 下寻求效用 $ U(X_1,X_2) $ 极大化,是一个条件极值问题,即:
$$ \cases{ {MaxU(X_1,X_2)}\\{s.t.I = P_1X_1 + P_2X_2} } $$
解决方法是用拉格朗日乘数法。
首先制造拉格朗日函数:
$$ L = U(X_1,X_2) + λ(I - P_1X_1 - P_2X_2) $$
注:λ = 边际效用 / 商品单价,这个函数的意思是购买商品1和商品2所得的效用,加上购买商品的所剩余预算产生的效用,等于一个值L。
将上式分别对$X_1$、$X_2$、$λ$求导并令其等于0,可得:
$$
\cases{
{\frac{\partial L}{\partial X_1} = \frac{\partial U}{\partial X_1} - λP_1 = 0}
\\{\frac{\partial L}{\partial X_2} = \frac{\partial U}{\partial X_2} - λP_2 = 0}
\\{\frac{\partial L}{\partial λ} = I - P_1X_1 - P_2X_2 = 0}
} %}
$$
注:
算式一相当于假设所有的钱都去购买了商品1,那么已经购买的每一个商品1所产生的效用等于边际效用。
同理,算式二相当于假设所有的钱都去购买了商品2,那么已经购买的每一个商品2所产生的效用等于边际效用。
而算式三即是在均衡效用的情况下,购买商品1和商品2的预算,刚好等于消费者的既定预算。
设效用函数 $ U = X_1^{\frac{1}{2}}X_2^{\frac{1}{2}} $ ,两种商品的价格分别是 $P_1=4$元, $P_2=5$元, 消费者收入为$1000$元,试求消费者的最优选择。
(省略其中一种解法,不然自己全混淆了……)
首先制造拉格朗日函数:
$$ L = X_1^{\frac{1}{2}}X_2^{\frac{1}{2}} + λ(1000 - 4X_1 - 5X_2) $$
分别对$X_1$、$X_2$、$λ$求导并令其等于0,可得:
$$
\cases{
{\frac{\partial L}{\partial X_1} = \frac{\partial U}{\partial X_1} - λP_1 = \frac{1}{2}X_1^{-\frac{1}{2}}X_2^{\frac{1}{2}} - 4λ = 0}
\\{\frac{\partial L}{\partial X_2} = \frac{\partial U}{\partial X_2} - λP_2 = \frac{1}{2}X_1^{\frac{1}{2}}X_2^{-\frac{1}{2}} - 5λ = 0}
\\{\frac{\partial L}{\partial λ} = 1000 - 4X_1 - 5X_2 = 0}
}
$$
整理得:
$$
\frac{\frac{1}{2}X_1^{-\frac{1}{2}}X_2^{\frac{1}{2}}}{4} = \frac{\frac{1}{2}X_1^{\frac{1}{2}}X_2^{-\frac{1}{2}}}{5} = λ
$$
化简为 $4X_1 = 5X_2$,
代入 $1000-4X_1-5X_2 = 0$,
可得消费者最优选择为:
$X_1 = 125$,$X_2 = 100$
$$ c’ = 0 $$
$(x^α)’ = αx^{(α-1)}$
特殊:
$x’ = 1$, $(x^2)’ = 2x$
$(\frac{1}{x})’ = -\frac{1}{x^2}$, $(\sqrt{x})’ = \frac{1}{2\sqrt{x}}$
$(log_αx)’ = \frac{1}{x\ln α}$,$(\ln x)’ = \frac{1}{x}$
$(\sin x)’ = \cos x$, $(\cos x)’ = -\sin x$
大概就是这样吧,但愿我们都理解对了。
]]>整个架构已经搭建完成了,但是也有很多零碎的东西需要补充。比如没有404页面。
以前是Wordpress自己就带的,也懒得改了。这次得自己来了。
要创建404.html很容易,直接在source根目录下创建自己的404.html就可以。hexo s会直接在public目录下生成文件。
其实,404页面可以做更多有意义的事,来做个404公益项目吧。现在,看下我的404页面一个ibruce.info上不存在的页面,做点有意义的事情,也对得起这个域名。
]]>hexo g始终无法生成css样式文件。这下就该万能的谷哥登场了。在github上找到了解决方法,而且居然这个issue就在hexo项目里的……传送门在此:https://github.com/hexojs/hexo/issues/995
1 | $ npm install hexo-renderer-stylus@0.1 --save |
然后继续自定义主题……
]]>本来已经在一篇一篇的改了,今天木哈哈突然提醒我应该有工具的。想想也是,于是谷哥了一下,前人还真留下了点东西的。
这个工具本来是给jekyll用的,虽然我用的Hexo,但是他能导出markdown格式的文章就足够了。名字很不错ExitWP。嗯,虽然我很懒,但是被折磨得不轻的我,也赞同这个标题。
言归正传,先给个项目的传送门:https://github.com/thomasf/exitwp
这个项目大部分文件都2年没动过了,不过并不影响使用。
先说一下我的环境:
1、Wordpress 4.1
2、Hexo 2.8.3
3、Windows 8 x64
大概说一下使用方法吧:
1、从Wordpress导出文章或页面,在工具→导出里就可以办到,最后会得到若干个xml文件。
2、下载ExitWP项目到任何地方解压,可以直接下载,也可以使用git clone。
1 | $ git clone https://github.com/thomasf/exitwp |
3、安装ExitWP的依赖,包括一下几个Python,PyYAML,Beautiful soup。可能最后一个以来需要说一下,因为Python和PyYAML都可以直接安装的,但是Beautiful soup需要命令行一下。其实也很简单,在命令行里cd到Beautiful soup的解压目录中,然后执行下面命令就可以了。
1 | $ python setup.py install |
4、将之前导出的所有xml文件复制到ExitWP解压目录的wordpress-xml目录中。
5、在命令行中cd到ExitWP的解压目录中,执行以下命令即可。
1 | $ python exitwp.py |
6、最后,会在build/jekyll/<你的域名>目录中找到很多让人头大的.md文件。
好了,不说了,我去哭一会。
]]>首先是通过cordova查看可以模拟的设备类型:
1 | $ ./platforms/ios/cordova/lib/list-emulator-images |
以上。
]]>谷哥了一番,还真有如此神器!Mac 科学神器——chnroutes登场!!
作者大神是条天朝汉子,在GitHub里他也说了,其实这个项目利用来自APNIC的数据生成路由命令脚本,让科学客户端在连接时自动执行。通过这些路由脚本,可以让用户在使用科学工具作为默认网关时,不使用科学访问中国国内IP,从而减轻科学工具负担,并提高访问国内网站的速度。大数据万岁啊!感谢APNIC和jimmyxu大神!
项目地址:https://github.com/jimmyxu/chnroutes
此项目不仅仅是针对Mac,而且同时支持windows/linux,以及基于linux的路由器。
Mac OS X下的使用步骤着实很简单:
下载项目,解压chnroutes.py这个文件;
打开终端进入下载文件所在的目录,执行python chnroutes.py -p mac,在该目录下会生成2个文件,ip-up和ip-down;
1 | $ python chnroutes.py -p mac |
4. 回到终端,进入目录(/etc/ppp)执行:sudo chmod a+x ip-up ip-down
1 | $ cd /etc/ppp |
结束了,就这么简单。连上测试一下吧。
如果一切正常的话,访问 http://www.whatismyip.com/ 会显示为国外地址,访问 http://www.ip138.com/ 则会显示为国内地址。
如果不想要分流了,直接把/etc/ppp下面那2个文件删了就行了。
Done.
PS:国内能不能搞个认证神马的,让因工作需要出墙的人更方便一点啊,这点钱一定要拿给私营企业来赚么?
]]>翻了很多国内的帖子,装遍了各种懒人版,可惜一个版本都无法成功。最后放弃了懒人版,直接原版安装,通过墙外谷歌解决了。基本完美,→原帖在此←。
先说说大致情况和存在的问题,看官们先确认是否能接受:
触摸板只有基本功能,无法实现手势(例如双指滚动、三指切换程序等)
默认内置WiFi模块无法工作(下文有替代方案)
音频和麦克风正常,但低音炮和HDMI音频不能工作
FN键可控制音频和多媒体(音量控制单独操作正常,但跟界面上的音量控制并不同步),背光正常(这是废话,因为是板子在控制),对于亮度、禁用触摸板、WiFi均不起作用(WiFi本来就不能工作……)
目测睡眠完美,测试5次,每次都能正常唤醒
主板虚拟化可以开启,但是安卓模拟器仍然无法使用x86镜像
读卡器不能识别
安装完蓝牙不能使用,但是可以在安装完成以后自行配置
亮度控制不太正常,有时会自动调到接近最亮,另外不能调到最暗,否则会黑屏(不要问我怎么知道的 )
ACPI传感器工作正常,使用了HWMonitor
给个图看看吧:

接着是我的机器配置:
17.3” 寸全高清 1080p LED 防眩光显示器
第三代 Intel® 酷睿 i7-3630QM 2.4 Ghz
8GB 双通道 DDR3 SDRAM ,1600MHz
128GB Plextor SSD M5 PRO(已安装Windows 8.1 - MBR,有系统保留分区)
1TB 5400RPM SATA HDD ST1000LM024 HN-M101MBB(资料分区 - MBR)
32GB mSATA SSD SanDisk(用于安装Mac OS X Yosemite - GUID, BIOS 设置为 AHCI,mSATA无法作为启动盘,需要使用其他硬盘或者U盘启动)
NVIDIA GeForce GT 650M GDDR5 2GB (独显,必须用DSDT屏蔽掉)
Intel HD Graphics 4000 (内置显卡和HDMI enabled by DSDT+patched AppleIntelFramebufferCapri.kext )
WiFi (默认内置无线网卡无法启用,可以根据tonymacx86上的教程更换为Atheros 9285芯片的WiFi模块来驱动,也可以上EDUP系列USB网卡,推荐EDUP(EDUP) EP-MS1558 300M,京东有卖,便宜好用)
对于以上配置,7720之间的主要区别就是在于CPU了,你可以针对自己的CPU来配置电源管理,不过理论上不修改也可以用。
最后是需要准备的东西:
1、一台苹果电脑,或者可以运行苹果系统的虚拟机
2、一个大于8G的U盘(我是用的SanDisk Cruz Edge 16G)
3、下载Yosemite的App安装包(现已在下文的百度网盘中分享,这里给一个异次元的→下载地址←,是10.10版本,看官们也可自行下载10.10.1版)
4、下载需要用到的工具和配置,包括UniBeast、U盘Extra文件夹、MutiBeast、Yosemite Extra文件夹和SLE文件夹。给一个百度网盘分享,如下:
链接: http://pan.baidu.com/s/1mg62uJe 密码: vyoa
以上内容都可以接受的童鞋们,你们可以继续往下看了。
1、进入你已经准备的苹果电脑或者虚拟机,将下载好的Yosemite App安装包拷入应用程序文件夹(如果熟悉英文的童鞋,现在就可以把系统主语言切换为英文,运行UniBeast的时候需要)
2、插上U盘,运行磁盘工具,选中U盘
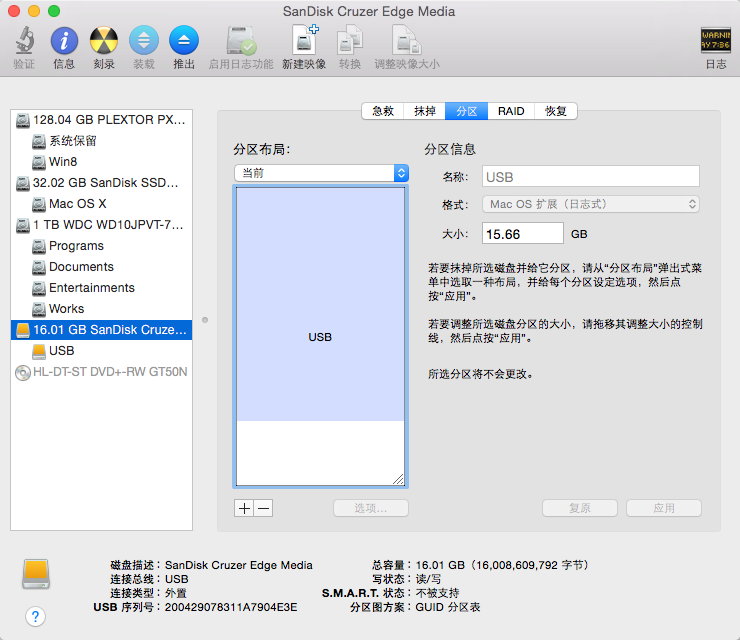
3、选中分区标签,然后选择1个分区
4、点击选项,选择GUID分区表
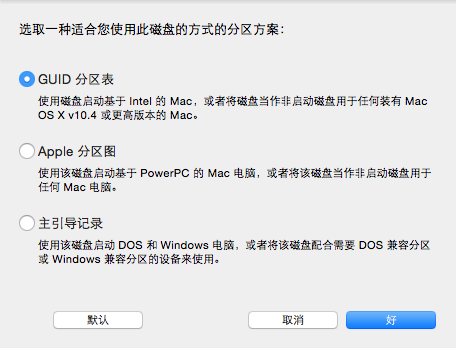
5、分区名称命名为USB,格式选择Mac OS 扩展(日志式),点击应用,开始格式化
6、解压下载的 UniBeast-5.0.2.zip ,打开UniBeast(记得把系统主语言改为英文),一路Continue、Continue、Continue、Agree,直到出现选择安装目标。选择USB,并Continue
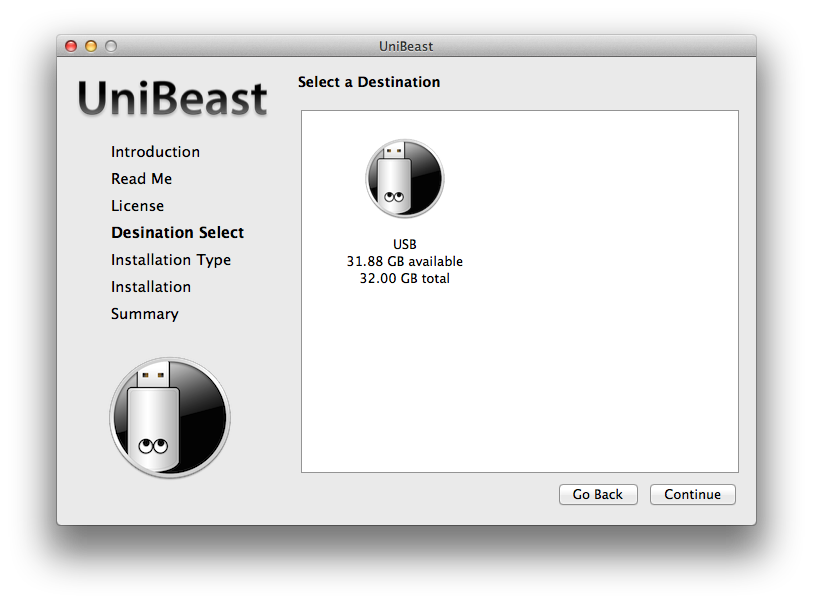
7、接着选择Yosemite,继续Continue

8、选择Laptop Support,继续Continue
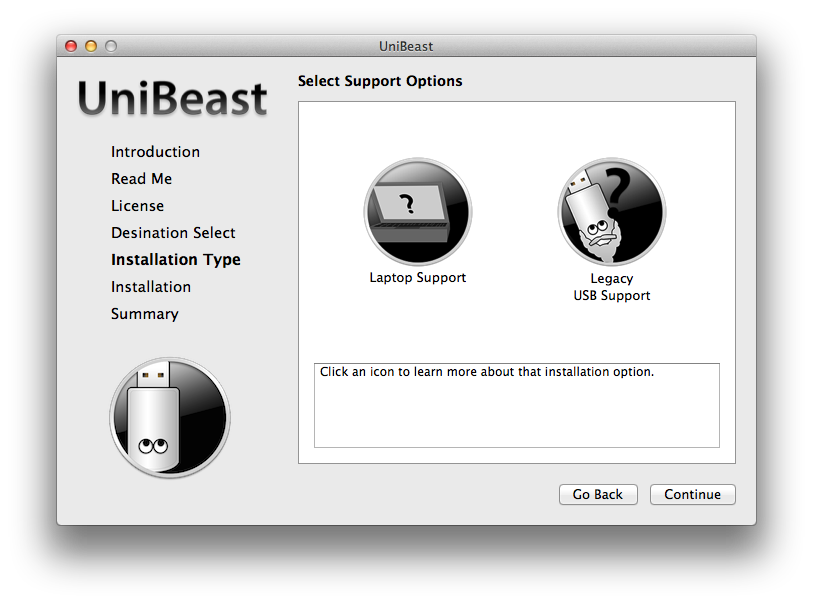
9、输入登录密码,点击Install进行安装。等待大概15分钟(我的U盘是2.0接口,3.0应该会快很多),千万不要拔掉U盘、关机神马的
10、删除U盘里Extra文件夹里的内容,将之前下载文件中的 USB Drive-Extra.zip 中的内容解压到U盘里的Extra文件夹中
11、另外,建议删除蓝牙驱动,即S/L/E目录下的2个IOBlueToothxxxxx.kext,否则会出现强行让你开启蓝牙键盘开关的情况
12、建议将网盘 Tools.zip 里的文件都解压出来放到U盘根目录,用得着。
1、插好U盘,启动Dell 7720 17R SE(如果之前步骤是用虚拟机做的,就重新启动计算机,你懂的),Bios设置进行如下修改:
Intel SpeedStep ~ Enabled
Virtualization ~ Disabled
Integrated NIC ~ Enabled
USB Emulation ~ Enabled
USB Powershare ~ Enabled
USB Wake Support ~ Disabled
SATA Operation ~ AHCI
这个时候一定要把虚拟化Vitualization禁用,不然启动过程会出问题,如果一定要启用,那就等所有内容配置好以后再启用。
同时记得设置USB优先启动,或者启动的时候按F12来选择启动盘。
2、在Chimera启动界面选择USB,启动参数最好加上 -v -f -x ,以便一次成功。我是没加-x也成功了的。加-v是为了看如果出问题,是出在哪里。其他启动参数已经在 org.chameleon.Boot.plist 中写好了
3、进入OS X Yosemite后的安装就大概说说了,网上教程非常多。首先是格式化目标安装盘,仍然使用磁盘工具,参考之前制作启动U盘的步骤,选择要安装的目标硬盘,选中分区标签,格式化为一个分区,选项选择GUID分区表,格式选择Mac OS 扩展(日志式),取一个好记的名字(比如Mac OS X),点击应用。然后返回,接着就开始安装了。
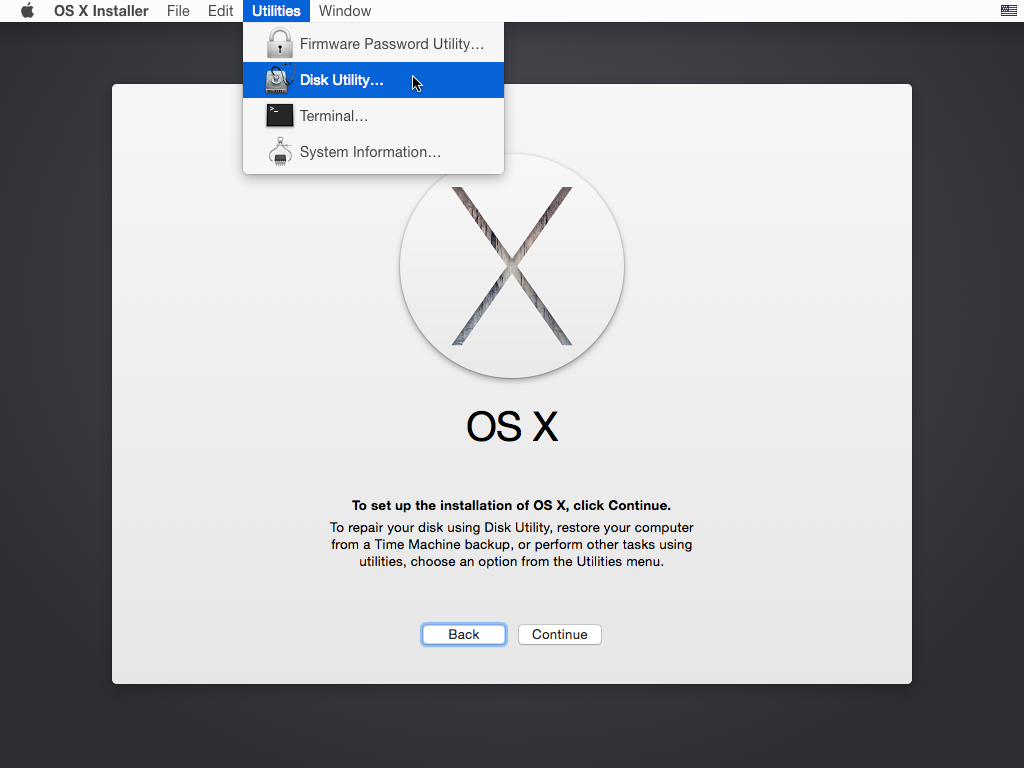
等上一会,系统就安装完毕了。
保证U盘插好,重新启动系统。这里有个分支,如果你熟悉Windows下利用HFS+或者MacDrive来操作Mac分区文件,那接下来的工作在Windows里操作实在很方便。当然,在Mac OS X里也麻烦不到哪里去,实际上跟Windows下配置差不多。
1、Windows下进行配置
1.1 进入Windows系统,安装HFS+ 10.3(之前分享的百度网盘文件中已经提供 - hfs_win_trial_c10.3.zip),安装时选择10天试用,安装完毕后直接重新启动。重启进入Windows后,在注册窗口中填入zip压缩包注释中的内容,你懂的
1.2 这时候你应该已经可以看到Mac OS X的盘了。进入后完整删除Extra文件夹中的所有内容,将下载文件 YosemiteHD-Extra.zip 中的所有内容拷进去。然后进入 System/Library/Extensions/ ,将下载文件 YosemiteHD-SLE.zip 中的所有内容拷进去,如果有重复的,最好直接将原来已有的备份,然后删除
1.3 重新启动,继续选择USB,用之前可用的启动参数进入安装程序,选择磁盘工具,选中Mac OS X分区,点击修复磁盘权限
1.4 重新启动,选择Mac OS X,如果幸运的话,你已经可以不加任何参数进入了,当然,保险起见 -v -f 还是加上的好。
1.5 进入系统后,配置好你的账户,就可以进入系统了。建议不要创建网络账户,如果实在需要,也在进入系统后,配置好网络再说。如果你的Mac OS X系统盘没有使用SSD,那么恭喜你,安装已经完成了,享受你的黑苹果吧!
1.6 如果和我一样,Mac OS X是安装在SSD上的,那么我们还有点事情要做。下载百度网盘中的 Tools.zip ,解压后可以得到很多文件。只需要打开 Del Inspiron 7720 SE.mb ,这是已经配置好的MultiBeast文件。现在还需要勾选上TRIM Enabler,让SSD能够正常工作。
好了,这下是真的配置完成了。欢迎再看看最后的小结。
2、Mac OS X 下进行配置
2.1 Chimera启动界面选择Mac OS X,使用启动参数 -v -f -x,这次-x不能少。
2.2 依次执行Windows步骤中的1.2、1.6。记得在Finder的偏好设置→边栏里,把“xxx的Macbook Pro”勾选上,这样可以比较直观的看到文件夹路径。当然熟悉的童鞋用终端来拷贝可能更快,因为可能涉及到权限问题,终端直接sudo就ok了。如果实在不知道怎么将 YosemiteHD-SLE.zip 中的内容拷贝到系统中,可以使用 Tools.zip 解压后文件夹里的 Kext Wizard 来操作。选择Installation标签,然后将需要安装的kext选取到Browse里,勾选Backup kexts that will be replaced,目标位置选择S/L/E,点击Install安装即可
2.3 如果你的Mac OS X安装在SSD上,请参考Windows步骤中的1.6操作。如果不是,则直接到下一步。
2.4 打开百度网盘下载的 Tools.zip 解压后文件夹里的 Kext Wizard,在Maintenace标签页中勾选全部,点击Execute修复权限

好了,这种方式也是真的完成了。
每次黑苹果都是一段闹心的历程,但愿这篇拙劣的教程能减少一些童鞋的烦恼。这篇教程已经尽量傻瓜式,跳过了诸如DSDT、SSDT等黑苹果过程必须了解的内容。如果有朋友能在此基础上进行改进,欢迎交流!
好久没写这么长的东西了,手残了啊……继续项目的iOS版开发了……
]]>之前有个已经装好10.9,但是分辨率只有默认的1024x768,各种不爽。
还记得博客里曾经有人问我怎么调整分辨率,虽然当时我也觉得太小,不过因为用mac的时间很少,就编译+发布,所以查得不多,也没找到办法。
这次仅靠度娘就找到了方法,分享一下。
在命令行中输入以下语句(注意,需要在vbox的安装目录下):
1 | $ VBoxManage setextradata \"MacOSMavericks\" VBoxInternal2/EfiGopMode 4 |
其中"MacOSMavericks"要换成自己的虚拟机名称,而不同的分辨率对应如下:
0 – 640×4801 – 800×6002 – 1024×7683 – 1280×10244 – 1440×9005 – 1920×1200值得注意的是:如果发现没有效果,很可能你需要用管理员权限来打开cmd和vbox!
以上方法10.10 Yosemite同样适用。
]]>但是,我万万没有想到,黑苹果没能成功装上,工作用的分区却挂了。

过程就不废话了,直接分享找到的好东西吧:
**《电脑数据恢复工具箱》 汉化新世纪出品 **
下载地址:http://www.hanzify.org/software/13831.html
各种恢复软件的集合,而且全部可用,功能完全。
我就用了传统的EasyRecovery就恢复了所有文件,幸好幸好。
不然手里还有没完成的项目,不然估计客户都会发飙的。


项目中一度纠结与AngularJS如何动态显示不同的html内容。
本来是希望直接使用下面的语句来实现:
1 | <div> {{html}} </div> |
但是很尴尬的是,这样不能识别出html标签,而是直接将html里的页面标签全都显示出来了。这当然不是我想要的效果。
谷哥了一番,没想到在官网上就找到了我想要实现的效果,而实现的主角就是今天的 $compile 服务。
https://docs.angularjs.org/api/ng/service/$compile
节选一下关键部分内容,Javascript:
1 | <script> |
Html:
1 | <div ng-controller="GreeterController"> |
总之就是用$compile服务创建一个directive ‘compile’,这个complie会将传入的html字符串或者DOM转换为一个template,然后直接在html里调用compile即可。
我基本就是直接copy过来就可以用了,各位看官自便咯~

在ubuntu下因为qq沟通太困难了,只好还是想办法恢复了Windows作业。但是Win妹还是很不争气的出了很多问题,最后一步就来自于NodeJS。

npm install -g cordova的时候,虽然看起来只有2次错误,一次npm ERR! Failed to parse json,一次npm ERR cb() never called。但就这两个问题就耗掉了我一个下午去度娘谷哥。然而最后所有的搜索结果都没解决我的问题。
没办法,只好自己分析。昨天网络一直有点故障,不记得是不是那个时候装了codova,加上看到命令行工具里提示npm-cache里的某个package.json不对,于是到C:User你的目录AppDataRoamingnpm-cache里看了一下,果然对应的那个json文件只有2kb,打开一开是空的。随便检查了一下,还有几个也是空的。
索性把npm-cache全删了,重新安装。果然一切都好了……
]]>1 | <a href="tel:4008888888">拨号吧!</a> |
这是几个意思?
谷歌度娘了好久,各种乱七八糟的解决方案都看过了,终于在google上发现了真相!
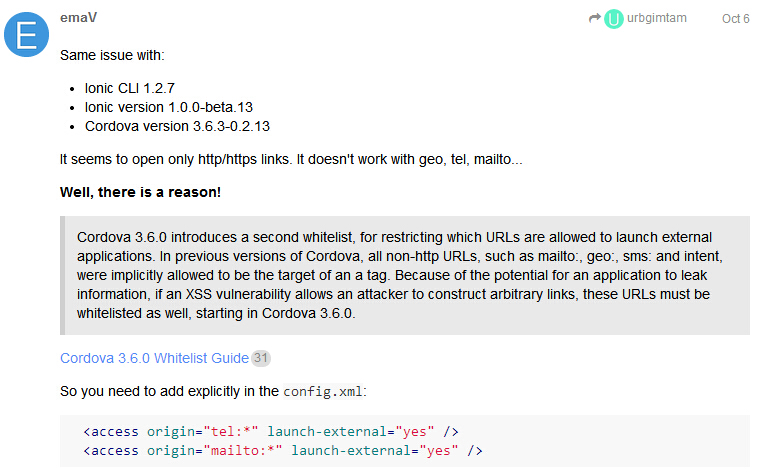
总的来说,意思就是从cordova 3.6.0开始,mailto、geo、 sms等等这些非http请求的地址,也被列入限制范围内,需要在config.xml里加入白名单来允许访问。
-v一下自己的cordova版本。

呵呵
哎,不知道说什么了,已经没脾气了,解决了就好。
近来身体越来越透支了,得多吃点来撑住了。
话说,Fenix跟我都越来越没脾气了。据说人没了脾气就离成功不远了。
我们这是要成功的节奏?
]]>但是鉴于在移动平台上的碰壁,无论是jQuery本身,还是与它思想一致的zepto、jqMobi、jQuery Mobile,抛开为了简单的功能不得不写好几段代码这样的情况,更让人头疼的是,它们都难以避免的出现了效率问题,尤其是在安卓手机上。
于是开始了一段长达两个月的探索,寻找适合Html5应用开发的平台。最终,AngularJS和Titanium被选中,由于后者学习成本更高,因此出身于google的AngularJS成为了首选。
最初接触AngularJS是一段并不太顺利的过程,因为jQuery虽然是面向对象语言,但是默认就并非MVC模式,而是我自己戏称为过程式的面向对象语言。个人其实非常适应这种模式进行开发,对于我这样非技术出身的开发,更方便理解。然而,选中AngularJS就决定了我必须挑战我的习惯,因为它生来就是MV*(MVW、MVVM、MVC)框架,它将结构抽象到了一个更高更简化的层次。
在实战了几个项目以后,无意中发现了这篇文章《有jQuery背景,该如何用AngularJS编程思想?》(http://blog.jobbole.com/46589/),仔细阅读了以后,我对AngularJS有了更好的认识,也更加理清了自己的学习和开发思路,也更坚定了近几个项目都不会混用jQuery和AngularJS的想法。
全文如下:
“我可以熟练使用jQuery进行客户端应用的开发,但是现在我希望开始使用Angular.js。哪位能描述一下这个过程中必要的模式变化吗?希望您的答案能够围绕下面这些具体的问题:
我如何对客户端web应用进行不同方式的架构和设计?它们之间最大的区别是什么?(译者注:指jQuery和Angular.js)
有什么是我不该做或者不该使用的;而又有什么是我应该做或者应该使用的呢?
有没有一些服务端的考量/约束呢?
我在寻找的就是一个关于jQuery和Angular.js之间的详细的比较。”
在jQuery中,你会先设计一个页面,然后让它变得动态化。这是因为jQuery是为了扩展而设计的,并在这个前提下变得越来越臃肿。
但是在Angular.js中, 你必须从一开始就在脑子里挂着架构的弦。不要一开始就想着“我有这样一个DOM,我想让它做X”, 你必须从你要完成的目标开始思考,然后设计你的应用, 最后才是设计你的视图。
类似地,不要一开始就带着这样的想法:jQuery可以完成X,Y,Z,所以我只要在其上为模型和控制器添加Angular.js就行了。在起步阶段这确实很容易勾引你,这也是为什么我总是推荐Angular.js新手根本不要使用jQuery,至少要在他们习惯了“angular 方式”之后。
我在这里(译者注:指stackoverflow)和邮件列表上看到过很多开发者,他们用150或者200行代码的jQuery插件,然后利用一堆让人困惑的复杂的回调和$apply与Angular.js粘合起来建立这些详尽的解决方案;最终确实可以跑起来! 但是其实这个问题在大多数情况下,我们可以用一小段Angular.js代码来重写jQuery插件即可,而这种方式会让一切刹那间简单明了可理解。
我觉得这类问题的底线是:当你在解决问题时,首先利用“Angular.js思想”去做;如果你不能想出一个方案,那么就在社区里询问;如果还是没有简单的解决方法,那么再请随意使用jQuery吧。但是注意,千万别让jqeury成为你的拐杖,不然你将永远无法真正精通Angular.js。
首先你要知道,单页面结构也是应用。它不是网页。所以我们需要有服务端开发者思想加上客户端开发者思想。 我们必须考虑如何将我们的应用拆分为独立,可扩展,可测试的组件。
那么你要怎么做呢?你如何做到利用“angualrjs思想”呢?这里有一些普遍的原则,与jQuery作为比照。
视图是“正式记录”
在jQuery中,我们通过编程方式来改变视图。我们可以像下面这样通过ul标签来定义一个下拉菜单:
<ul class="main-menu"> <li class="active"> <a href="#/home">Home</a> </li> <li> <a href="#/menu1">Menu 1</a> <ul> <li><a href="#/sm1">Submenu 1</a></li> <li><a href="#/sm2">Submenu 2</a></li> <li><a href="#/sm3">Submenu 3</a></li> </ul> </li> <li> <a href="#/home">Menu 2</a> </li></ul>在jQuery中,根据我们应用的逻辑,可以用类似下面的语句来激活它。
('.main-menu').dropdownMenu();当我们只是看着视图的时候,不会立刻看出它的功能。对于小应用而言,这样是没问题的。但是对于大型的应用,情况就一下子变得令人困惑并且难以维护。
但是在Angular.js中,视图是基于视图的功能的正式记录。我们的ul是像下面这样声明的:
<ul class="main-menu" dropdown-menu>...</ul>这两者其实做了同样的事情,但是在Angular.js的版本中,任何看到这个模板的人都知道将要发生什么。不论何时,开发团队里有任何新的开发人员加入,她可以一眼看出有一个叫做dropdownMenu的指令作用在视图上;她根本不需要凭直觉猜测或者研究下代码才找到正确的答案。视图本身就告诉我们将会发生什么了。清晰多了。
angualrjs的新手经常会问这样一个问题: 我如何找到某一类所有的链接并且给它们添加一个指令呢?当看到我们回复的时候小伙伴都震惊了:压根别去这样做。但是劝你不要这样做的原因是,这样做就像是一半jQuery,一半angulrjs,而这真心很糟。这里的问题是,开发者想在angualrjs的情境中使用jQuery方式。而这绝对不会玩得转。视图是正式记录。超出指令的范围(这点下文会谈论更多),你绝不要去改变DOM。而且指令是应用在视图中的,目的自然也一目了然。
记住:不要先设计再修饰。你必须先进行架构,然后再考虑设计。
数据绑定
这是Angular.js目前最酷的特性之一,并且秒杀我前文提到的各种需要的DOM操作。不需要你自己动手,Angular.js将自动更新你的视图有木有!
在jQuery里, 我们响应事件并更新内容,大概是这个样子:
$.ajax({ url: '/myEndpoint.json', success: function ( data, status ) { $('ul#log').append('<li>Data Received!</li>'); }});视图则看上去是这样的:
<ul class="messages" id="log">除了关注点混合的问题,这里同样有之前提到的表征目的的问题。更重要的是,我们不得不手动引用并更新dom节点。并且如果我们想要删除一个日志,我们不得不再次对dom编程操作。我们怎样才能抛开dom来测试逻辑呢?还有,如果我们希望改变展现呢? 真是让人凌乱。。。 但是在Angular.js中,我们可以这样做:
$http( '/myEndpoint.json' ).then( function ( response ) { $scope.log.push( { msg: 'Data Received!' } );});我们的视图看上去是这样的:
<ul class="messages"> <li ng-repeat="entry in log">{{ entry.msg }}</li></ul>但是考虑到刚才提到的问题,我们的视图看上去可以是这样的:
<div class="messages"> <div class="alert" ng-repeat="entry in log"> {{ entry.msg }} </div></div>现在,替换掉了无序列表,我们使用Bootstrap警告框。同时我们根本不需要改变控制器代码!更重要的是,不论日志何时或者如何更新,视图也会跟着改变。自动的!漂亮!
虽然我没有在这里演示出来,但是数据绑定是双向的。所以这些日志信息同样可以在视图中被编辑,就像这样:
<input ng-model="entry.msg" />是不是更开心了?
不同的模型层
在jQuery中,dom有点像模型。但是在angualrjs中,我们有一个分离的模型层, 而这个模型层可以让我们用任何方式管理,完全独立于视图。这对于上面说的数据绑定很有帮助, 还可以维护关注点分离,并且引入更多的可测试性。其它的答案提到了这点,所以我这里就不再赘述了。
关注点分离
以上所有的这些把我们带入了这样的主题:保持你的关注点分离。你的视图表现的像记录什么会发生(大部分情况)的正式记录;你的模型表现你的数据;你有一个服务层来执行可重用的任务;你执行dom操作并通过指令扩展你的视图;并且你用控制器来组合这些。这些同样已经在其它答案中提到,我在这里唯一还要提出的一个事情就是可测试性,我会在下文的另一节里专门讨论。
依赖注入
依赖注入是让我们实现关注点分离的方法。如果你是一个服务器端的开发者(从java到php),你可能对这个概念已经非常熟悉了,但是如果你是一个来自jQuery的客户端的朋友,那么你可能会认为这个概念是傻浅挫。但是它可不是:)
从一个更广的观点来看, 依赖注入意味着你可以非常自由的声明组件,然后你可以通过任意其它组件,呼叫一个它的实例,然后授权。
你不需要知道载入顺序,或者文件位置,或者其它类似的东西。这种强大的力量可能不会立刻显现,但是我这里会提供一个(通常)的例子:测试。
比如在我们的应用中,需要一个通过REST API,同时也依赖于应用状态,本地存储实现了服务器端存储的服务。当在我们的控制器上跑测试的时候,我们不希望与服务器端通讯-毕竟我们在测试控制器。我们能够仅仅添加一个与我们原始组件同名的mock服务,注入器将确保我们的控制器自动获取伪造对象–我们的控制器不会也不需要知道它们的区别。
那么既然提到测试……
这个其实是关于架构的第三节的一部分,但是这个主题非常重要,所以我需要将其提出来作为自成体系的部分。
那些你看过,用过,写过的所有jQuery插件,它们中有多少有相应的测试包?不是很多吧? 因为jQuery可不是很遵守这个规矩。但是angualrjs是。
在jQuery中, 测试的唯一方法是用示例页面来独立地创建组件,针对该页面我们的测试可以实施dom操作。于是我们就不得不分离地开发一个组件然后将其集成进我们的应用。多么不方便啊!
那么多时间啊,当我们使用jQuery开发时,我们选择使用迭代开发代替测试驱动的开发。可以谁又能怪我们呢?
但是因为我们有关注点分离,我们能够在Angular.js里反复使用测试驱动开发。举个例子,我们想要一个超简单的指令来指示在菜单中我们目前的路径是什么。我们可以在视图中这样声明我们想获取的:
<a href="/hello" when-active>Hello</a>好了,我们现在可以写个测试:
it( 'should add "active" when the route changes', inject(function() { var elm = $compile( '<a href="/hello" when-active>Hello</a>' )( $scope ); $location.path('/not-matching'); expect( elm.hasClass('active') ).toBeFalsey(); $location.path( '/hello' ); expect( elm.hasClass('active') ).toBeTruthy();}));我们运行测试,并确认它是失败的。那么我们来写下我们的指令:
.directive( 'whenActive', function ( $location ) { return { scope: true, link: function ( scope, element, attrs ) { scope.$on( '$routeChangeSuccess', function () { if ( $location.path() == element.attr( 'href' ) ) { element.addClass( 'active' ); } else { element.removeClass( 'active' ); } }); } };});现在我们的测试通过了,并且我们的菜单按照请求运行。我们的开发是迭代并且测试驱动的,太酷了哦!
你会经常听到“只在指令里做dom操作”。这是必要的。请对它表示出尊重!
但是让我们谈点更深入的。。。
一些指令只是装饰那些在视图里的已有的(想想ngClass),因此有时候就直接进行dom操作,基本上都能搞定。但是如果一个指令像个“widget”并有一个模板,
那它同样要遵守关注点分离原则。也就是说,这个模板也应该与它在链接和控制器函数里的实现保持最大的独立。
Angular.js自带着一套工具让这件事变得简单; 使用ngClass我们能够动态的更新类;ngBind允许双向的数据绑定;ngShow和ngHide以编程的方式显示或隐藏一个元素;还有更多–包括我们自己写的那些。换句话说, 我们可以不用DOM操作来实现所有的酷炫的事儿。 dom操作越少,指令越容易测试,它们也更容易样式化,在未来它们也更容易改变,并且也变得更加可重用和可分发。
我看到很多Angular.js开发新手将指令当做放置一堆jQuery的地方。换句话说, 他们认为:“既然我不能在控制器里做dom操纵,那么我就把这段代码放到指令里”。当然这看上去好多了,但是通常这仍然是错的。
想一下在第三节里我们编写的日志记录。即使我们将其放到一个指令里,我们仍然希望用“anggualjs方式”来做这件事情。这仍然没有做任何dom操作!在很多情况下dom操作是必须的,但是这种情况其实比你想的少得多!在你在你的应用中到处使用dmo操作之前,问问你自己,这真的是必须的吗。可能有更好的方法呢。
这里用一个简单的例子来展示我们经常会看到的一个模式。我们需要一个切换按钮。(注意:这个例子有那么一点人为设计的技巧并且有点啰嗦,但是很多更复杂的情况其实也完全可以根据这个例子的方式来解决。)
.directive( 'myDirective', function () { return { template: '<a class="btn">Toggle me!</a>', link: function ( scope, element, attrs ) { var on = false; $(element).click( function () { if ( on ) { $(element).removeClass( 'active' ); } else { $(element).addClass( 'active' ); } on = !on; }); } };});这里有一些错误。第一,jQuery不是必须的。我们这里做的一切都不需要jQuery!第二, 即使是我们的页面上已经有jQuery,也没有理由一定要在这里使用它;我们可以简单的使用angular.element,而且就算在一个没有jQuery的项目中我们的组件仍然可以工作。第三,即使我们假设为了让这个指令工作,jQuery是必须的,如果jqury被加载,那么jqLite(angler.element)一定会使用jQuery。所以我们不需要使用$(译者注:jQuery的一个标识符号,是jQuery函数的别名)–我们可以使用angular.element。第四, 紧接第三点,jqLite元素不需要被包裹在$里–传递给link函数的element已经是一个jQuery元素!第五, 我上一节已经提过的,为什么我们要将模板混合进我们的逻辑呢?
这个指令可以更精简的重写(即时在更复杂的例子里也一样):
directive( 'myDirective', function () { return { scope: true, template: '<a class="btn" ng-class="{active: on}" ng-click="toggle()">Toggle me!</a>', link: function ( scope, element, attrs ) { scope.on = false; scope.toggle = function () { scope.on = !$scope.on; }; } };});再次强调,模板的那些代码都是在模板里的,所以你或者你的使用者能够很方便的将其换成一个符合任何需要的样式,同时逻辑不被改变。这就是重用性-赞!
当然,还有其它很多好处–比如测试 – 这很容易! 不论什么在模板中,指令的内部API绝不会被接触,所以重构就变得容易。你可以在不接触指令的情况下随意改变你的模板。并且不论你怎么变,你的测试仍可以通过。
耶!
所以如果指令不只是一组jQuery风格的函数,那么它们是什么呢?指令其实就是html的扩展。如果html不能完成你希望它做的一些事情,你就写一个指令来做,并且当它是html的一部分来使用。
换句话说, 如果Angular.js一下子无法完成手头的工作,想想看你的团队是否能用ngClick、ngClass等来搞定它。
别用jQuery。甚至都别引用它。它会阻碍你。当你有个问题已经知道怎么用jQuery来解决的时候,在你将手伸向$的时候,试试能不能在Angular.js的规范内解决。如果你不知道,就问!
十有八九最佳的方法是不需要jQuery的,而当你选择用jQuery的时候反而会导致更多的工作呢。
原文链接: stackoverflow
]]>在度娘和谷哥的帮助下了解到可能是谷歌字体的关系,自己用开发者调试工具对网络加载进行检测,发现确实后台使用了谷歌字体的API。谷歌早就被墙了,所以浏览器反复的请求谷歌服务器导致无法正常加载页面,拖慢速度也就是正常的了。
解决方法是在当前主题的functions.php中加入下面的代码:
1 | //禁用Open Sans |
select 是 AngularJS 预设的一组directive。下面是其官网api doc给出的用法:AngularJS:select
大意是,select中的ngOption可以采用和ngRepeat指令类似的循环结构,其data source可以是array或者是object。针对两种data source又有衍生的好几种用法。但是官网的例子实在是太少了。
下面是针对几个不太容易理解的用法的例子。
先上controller
1 | function selectCtrl($scope) { |
usage: label for value in array
1 | <select ng-model="selected" ng-options="m.productName for m in model"> |
说明
usage中的 value 也就是 ng-options 中的 m,而 m 是数组model的一个元素,它是一个变量
usage中的 label 也就是 ng-options 中的m.productName, 其实就是一个 AngularJS Expression
usage: label for value in array
1 | <select ng-model="selected" ng-options="(m.productColor + ' - ' + m.productName) for m in model"> |
说明
usage: label group by group for value in array
1 | <select ng-model="selected" ng-options="(m.productColor + ' - ' + m.productName) group by m.mainCategory for m in model"> |
说明
group by,通过$scope.model中的mainCategory字段进行分组ngModel的值usage: select as label for value in array
1 | <select ng-model="selected" ng-options="m.id as m.productName for m in model"> |
说明
ng-model的值。在这里,ng-model等于m.id,当ng-model发生改变的时候,得到的是m.id的值DNSCrypt是OpenDNS发布的加密DNS工具,可加密DNS流量,阻止常见的DNS攻击,如重放攻击、观察攻击、时序攻击、中间人攻击和解析伪造攻击。DNSCrypt支持Mac OS和Windows,是防止DNS污染的绝佳工具。
DNSCrypt使用类似于SSL的加密连接向DNS服务器拉取解析,所以能够有效对抗DNS劫持、DNS污染以及中间人攻击。
DNSCrypt的Windows客户端版运行后,会自动在状态栏显示服务状态,并自动修改DNS服务器地址为127.0.0.1,通过本地加密的方式安全连接OpenDNS,这样,本地所有的DNS请求都会加密进行从而绕过DNS污染,最终顺利解析到正确IP地址,根据我的测试,这个工具可以一劳永逸地解决所有DNS污染问题,包括此次针对Dropbox的DNS污染。
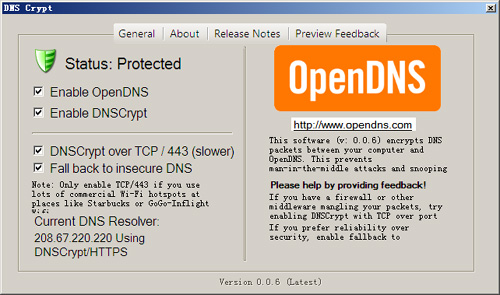
DNSCrypt官方介绍页面:http://www.opendns.com/about/innovations/dnscrypt/
DNSCrypt下载地址:http://shared.opendns.com/dnscrypt/packages/windows-client/DNSCryptWin-v0.0.6.exe
DNSCrypt MAC版源码,Windows版源码。
]]>利用解决其它事情的空闲,跟戴尔客服咨询了一下维修的问题,悲剧的是风扇只有一年质保,明显我的已经过了。直接问客服价格,他也不清楚,给了我附近维修站的电话和地址。不问不知道,一问哎呀卧“哔—”。就这么个破风扇,非原装的就要收我150,吃人哪?哥书读的少,你别骗我。
于是自己上淘宝搜了一下,果然很多**Dell 7720 风扇**的货,而且基本上都可以在含运费50以下的价格买到。幸好没上当。随便挑了一家先放购物车。
像我这么谨慎的人当然不可能立即下单了,首先必须要确认自己能换才行。于是风扇还没入手,就开始拆机了。
7720拆机非常简单,而且网上有**完整的官方说明**!戴尔的确有他的优势,连拆机都有官方说明,只要照做,一切ok。但是,即便如此简单也可能有意外的……下文会提到……
1、按说明拆下D面和C面的壳,螺丝一定不要弄混了。

2、特别注意拆D面的时候一定要把光驱连带拆下,不然D面有3颗螺丝是无法看到的。

3、是哪3颗螺丝呢?就是下图这里的螺孔了。有没有发现其中有一个孔不对劲?要大一点,而且有磨痕。因为悲剧就发生在这里啊!不知道是哪位大侠装配的时候菊花一紧,力道过猛,把这脆弱的铝制螺丝拧得死紧,我只用了两下就给拧花了,Orz……坑我呢哥?还好哥练过,正好俺爹的电钻还在……

4、就是它了,一共用到两种批头。先用尖头(瓷砖打孔用)定位,以防后面使用小孔螺纹批头的时候位置打偏了。接着再用小孔螺纹磨掉整个螺丝的头部即可。

5、整个螺丝头部磨掉以后,壳自然就开了。

6、来欣赏一下打开后的杰(can)作(ju)吧!图中的亮点就是螺丝的尸体。


拆好了机,自然安装风扇就不在话下了。顺道还清理了一下灰尘。接着当然是:买了风扇,坐等2天,安装完毕,电脑复活!
苦逼的码字生活继续……
]]>自从用了米2以后,曾经没少为输入法的问题折腾,问题出在对【美观、体验、功能】三者平衡的高标准严要求。

第一个被淘汰的是搜狗。本来自己曾经是搜狗的老用户,体验、功能上面其实都还是不错的(尤其还有我自己的在线词库)。为什么淘汰呢?因为搜狗小米版不给力啊,阉割得太厉害了吧?那一定有人说你用原版好啦。这么说吧,如果原版有跟小米版一样的皮肤的话,估计我就用了。没办法,这就是一个看脸的世界。使用时间大概在5个月左右。
第二个被淘汰的是百度。这位选手我就不多说了,虽然电脑版还不错,但是手机版我没法吐槽了,这东西完全不是我的菜。亮点是它也有小米版,皮肤很和谐。不过也就仅此而已。使用时间大概在1个月左右。
省略掉中途试过的N多输入法(留下印象的也只有触宝而已,不过表现普普通通),下一个被正式淘汰的是QQ输入法。我用他完全是因为我是个泛QQ用户,凡是QQ有的服务,别家没有明显比他家好的,我就会用他的……QQ输入法其实表现也就是普普通通,皮肤也只能找到一个勉强合格的,但是毕竟是我PC上使用最久的输入法,词库最全,所以成为了到目前为止我使用时间最长的手机输入法。使用时间大概在8个月左右。
最后到了今天的主角,目前除了系统自带以外,唯一存活在我手机上的输入法——讯飞输入法。安装他完全是出于偶然,当年给父母的越狱ipad mini安装第3方输入法的时候,支持手写的根本就没有什么可选择的,当然就讯飞了。而且使用下来感觉还是很不错,识别率高,连笔都可以。
而我将他安装到我手机上的原因,正好是我需要一个在我不知道怎么拼的时候,能手写的输入法。
为什么不选别的呢?市面上可以手写的输入法到处都是。但是有一点,当时可以在键盘输入的同时直接手写的可不多,这点体验对我这样有追求(?)的人来说,非常重要。再加上之前对他使用上友好度的体验,识别率的感受,差不多就定下来用他了。
呵呵,其实没那么容易。我是个看脸的人,怎么可能只用功能和体验就打败我呢?所以最终让我使用这个从没真正了解过的输入法的原因是,当时他有一套用户自制的小米皮肤(后来被官方收为“典雅灰”了,看九宫格的笑脸表情就能明显分辨与其它官方皮肤不同)。嗯,我被征服了。
【正文】
前面扯太多了……以至我自己感觉好像都要结尾了似的……
今天的题目是语音输入,所以讯飞那些NB的功能,像连笔输入、叠字输入什么的,其它输入法也有,也不是讨论范围内的东西。真正把其它输入法瞬间秒成渣渣的,就是语音输入功能了。
因为阿宝要帮单位一位不太懂电脑的师傅打一份文稿,而小小宝在她下班后是一定找她的,所以我得把这个任务接过来。嗯,看到几大页的字,我头都大了。
对于我这样能偷懒就一定要偷的人,怎么可能老老实实打字呢?所以我掏出了手机,准备体验讯飞输入法的看家本领——语音输入。人家科大讯飞本来就是专业从事智能语音及语音技术研究的啊。
体验下来本人有以下几点感受:
1、官方说识别率90%以上,这绝不是吹的。几千字的文稿输入下来,修改的地方没过三位数,而且大部分都是标点,文字除了人名以外很少出错。同时,要知道,这篇文稿涉及到很多专业术语。而这些术语完全正确,一个都没错!
2、连续输入的情况下,只要阅读者正确断句,标点符号都能在正确的位置打出来。之所以说是正确的位置,是因为讯飞并不能完全正确的识别应该用什么标点符号。尤其是逗号和句号,基本没法分辨。而引号、顿号、书名号之类的就更不用想了。曾试过直接读出“顿号”这两个字,自然,讯飞很诚恳的把这两个字打在了屏幕上。
3、网络不稳定的情况下,还是需要下载离线语音的。离线语音包的识别率也还是很不错,对比24Mb的容量来说,实在很实惠。
【附带】
为什么还来个附带?因为手机保存失败了啊!输入几千字全部泡汤了啊有木有?!坑爹的手机版wps不带这样的!

于是我回到PC上,抱着试一试的想法,安装了讯飞输入法电脑版。
不曾想到,PC上的讯飞也非常给力,识别率稍比手机端低,怀疑是麦克风的问题。对比QQ输入法的语音输入功能,200%一击必杀啊。
【结论】
讯飞输入法,个人目测最牛逼的语音输入法(没有之一)。
【PS】
就我现在这博客的pr、指数神马的,就足以说明这肯定不是软文。但是科大讯飞的朋友们,你们看我这么靠谱的用户,能给个什么奖励不?

判定攻击源和确定处理办法的第一步自然是查看日志,但是一看,有一种蛋蛋的忧桑……居然只有最基本的IP、访问时间、访问页面等信息,连user-agent都木有啊。
其实Apache的日志还是很强大的,我们可以在httpd.conf中找到下面这段代码:
LogFormat \"%h %l %u %t \"%r\" %>s %b\" common这就是日志格式定义的地方。该行指令创建了一种名为“common”的日志格式,日志的格式在双引号包围的内容中指定。格式字符串中的每个变量代表着一项特定的信息,这些信息按照格式串规定的次序写入到日志文件。
%...a: 远程IP地址 %...A: 本地IP地址 %...B: 已发送的字节数,不包含HTTP头 %...b: CLF格式的已发送字节数量,不包含HTTP头。 例如当没有发送数据时,写入‘-’而不是0。 %e: 环境变量FOOBAR的内容 %...f: 文件名字 %...h: 远程主机 %...H 请求的协议 %i: Foobar的内容,发送给服务器的请求的标头行。 %...l: 远程登录名字(来自identd,如提供的话) %...m 请求的方法 %n: 来自另外一个模块的注解“Foobar”的内容 %o: Foobar的内容,应答的标头行 %...p: 服务器响应请求时使用的端口 %...P: 响应请求的子进程ID。 %...q 查询字符串(如果存在查询字符串,则包含“?”后面的 部分;否则,它是一个空字符串。) %...r: 请求的第一行 %...s: 状态。对于进行内部重定向的请求,这是指*原来*请求 的状态。如果用%...>s,则是指后来的请求。 %...t: 以公共日志时间格式表示的时间(或称为标准英文格式) %t: 以指定格式format表示的时间 %...T: 为响应请求而耗费的时间,以秒计 %...u: 远程用户(来自auth;如果返回状态(%s)是401则可能是伪造的) %...U: 用户所请求的URL路径 %...v: 响应请求的服务器的ServerName %...V: 依照UseCanonicalName设置得到的服务器名字在所有上面列出的变量中,“…”表示一个可选的条件。如果没有指定条件,则变量的值将以“-”取代。分析前面来自默认httpd.conf文件的LogFormat指令示例,可以看出它创建了一种名为“common”的日志格式,其中包括:远程主机、远程登录名字、远程用户、请求时间、请求的第一行代码、请求状态,以及发送的字节数(LogFormat "%h %l %u %t "%r" %>s %b" common)
有时候我们只想在日志中记录某些特定的、已定义的信息,这时就要用到”…”。如果在“%”和变量之间放入了一个或者多个HTTP状态代码,则只有当请求返回的状态属于指定的状态代码之一时,变量所代表的内容才会被记录。
观察刚才定义common处的上下文,我们还可以发现apache的默认配置文件就预置了多种格式,而combined就是我所需要的。只要把每个访问目录的CustomLog都使用combined就可以了。
PS:最后确定是CC攻击。小样们,我们准备好了。
]]>首先当然就是初始化数据表,把测试数据都干掉,不要影响正式游戏数据。
1 | TRUNCATE TABLE table_name; |
方便自己不要忘掉,我已经把它们存到了我的navicat for mysql中 :)
]]>刚开始我还觉得很庆幸,因为内屏没事,液晶屏照样显示得很好,所以以为没事,等按上去没反应才意识到……OGS全贴合原来还有这个缺点,想当初看人家的手机保护外屏裂了,照样用得挺好。我就没这么幸运了 T-T
第一反应当然是找小米官方服务,但是搜了一下,如果直接换屏,统一价490。太狗血了( ´Д`)……况且最近的小米之家也得要1个小时才能过去,太远了。(好吧,其实主要还是因为那490……)
于是只好转战淘宝,卖的还挺多,价格也基本上没有过 300的。淘了很久淘到了这家店:【小米2屏幕总成】。卖家很好,东西也很便宜,我选的原装后压不带框才170包邮,还送好些东西。据说原装后压的概念就是把好的外屏和好的内屏合在一起。个人认为没有原装总成那么完美,但是绝对值这个价。
对于唯一给店家这宝贝中评的那位朋友,我只想说你太认真了。想要纯正原装就不要省这点钱……
当然,我能发这个日志说明我选对了,我的米2复活了。后来因为光线感应的问题还咨询过卖家,结果他还特地打电话过来给我讲解。这么好的服务,赞一个!
废话说差不多了,来分享一下更换触摸屏的流程吧。
1、碎裂当天立即拆机(卖家宝贝页面有非常详尽的拆机视频,建议看过有把握了以后再开干)。我看到主板背后写的字,虎躯一震。为毛突然觉得我的米2档次骤降……

2、把屏幕拆下来大概是这个样子的。螺丝共有3种,分类保管好,别丢了。还有供触摸、减震和绝缘的几个胶片也别弄丢了。

3、用电吹风开到热风档,把贴屏用的胶吹软,把屏幕取下来。我这屏幕取下来是真坑啊,下面的小碎片要挨着抠……但是这也是值得的,因为就这个外框还得要30块钱呢。

4、拆完后的全家福,一个都不能丢啊!

5、这是卖家寄来的东西。包装没拍,其实包得特别好,尤其是屏幕。赠品包括:2张胶贴(用来把屏幕粘到外框上)、1个撬棒、1个小起子、1对螺丝封帖(没用上,反正也不会去小米之家修)、1张磨砂膜(卖家已帮忙贴到屏幕上,贴得非常完美)、1张高透膜、1个软胶保护套(本来我有保护套了,而且卖家送这个……太不适合我了……)。

6、两块屏幕站对比较一下,真心看不出来区别。

7、背面比较。话说为毛我旧的屏幕后面的石墨散热层有这么多划痕?

8、正式安装以前先测试一下。完全没问题,准备安装。

9、先把外框上原来的胶全部清理干净(就是那些白色的),底部的屏幕碎片也再次确认都清理掉了。
然后把赠送的胶贴贴上去,好固定屏幕。卖家给了2个胶贴,如果1个贴坏了,还可以有备用的,很细心。
不过像我这样DIY成性的人,1个足矣 :D


10、贴上屏幕,再把所有部件组合起来,完工。启动。

使用2天以后有点小小的瑕疵,屏幕右上方有一条亮痕,但是只在黑屏下能看见。不过按照目前屏幕的工艺,这么一条亮痕想要扩散到影响使用,恐怕得等到我淘汰米2的那一天了吧。
之前提到光线感应有问题(微信尤其明显),我发现不是卖家跟我说的原因,应该是跟屏幕一点关系也没有,而是有可能我拆机的时候碰到哪里了。因为在使用小米手机的硬件测试(_##64663##_)时,发现光线感应数值一切正常。所以拆机有风险,DIY需谨慎哪。
不过对我来说,这次经历仍然非常完美。满足了。
]]>之所以说是标准,是因为完全按照官方文档来创建,而不是像之前那篇日志《PhoneGap开发心得(一) 搭建PhoneGap+Eclipse+Android环境》的做法。废话少说,开始吧。
1、首先是常规的环境要配置好,JDK(点击这里下载)、ADK(点击这里下载)、Eclipse(点击这里下载)、Eclipse装上ADT插件(打开Eclipse中的菜单 “Help”->”InstallNewSoftware”进入软件安装界面,点击“Add”按钮,Location地址栏填入:https://dl-ssl.google.com/android/eclipse/)。然后Node.js(http://nodejs.org/)的安装,GIT(http://git-scm.com/)的安装也是必不可少的。这些都跟之前的日志所描述的大同小异,就不赘述了。但是一定要记得把应该配置的环境变量配好!
2、接着来看正规军的操作方式吧,我们准备安装配置最新的Cordova项目。我的主工作环境是Windows8,所以就写Windows下的方式啦。打开命令行工具(Win+R→cmd),输入:
1 | C:>npm install -g cordova |
继续等待cordova CLI下载配置一堆东西,ok。
4、接下来创建android平台的内容。首先进入项目目录:
1 | C:项目目录>cd hello |
很自然的,再次等待cordova CLI blablabla处理一堆玩意。
5、现在android项目也创建好了,然后我们该来点实际点的东西了。把之前写好的网站项目拷贝到 **C:项目目录hellowww **中,如果你有的项目将会发布多个平台,这一步会比较重要,因为它不但将省去你挨个向各个拷贝网站项目源码的过程,更重要的是会免除挨个检查遗漏和错误的悲惨经历。
从现在开始,就可以在这个www目录中编辑网站项目了。
但是别忘了,虽然这个时候你的项目里面可能没有cordova.js,但是仍然必须引入才可以,如果用到了插件,还需要引入cordova_plugins.js。
6、刚才拷贝到www目录的网站项目源码怎么在android平台项目中生效呢?很简单:
1 | C:项目目录hello>cordova build |
当然,如果你的项目中已经有多个平台了,而你只希望编译android项目,那么:
1 | C:项目目录hello>cordova build android |
7、下面轮到Eclipse登场了。打开Eclipse,新建一个项目,选择“Android Project from Existing Code”,然后选择C:项目目录helloplatformsandroid,然后导入所有项目。至此,标准方式创建完成。
8、为什么我要选择标准创建方式?因为添加各种插件十分方便,所以接下来是讲如何创建插件:
1 | C:项目目录hello>cordova plugin add org.apache.cordova.network-information |
在此官方页面(http://cordova.apache.org/docs/en/3.5.0//guide_cli_index.md.html#The%20Command-Line%20Interface)可以看到都有哪些插件可用。
好了,一切ok。记得每次修改了网站项目以后,都在CLI中build一次,这样才能保证Eclipse编译出来的项目是最新的。
]]>onbeforeunload 不能满足要求,因为像Chrome就不响应,而有不少浏览器都是基于Chromium二次开发的,肯定会有相似的问题。很幸运,度娘到了一个非常好用的方法,不敢藏匿,拿来与大家分享。
1 | var UnloadConfirm = {}; |
该方法兼容IE6+、Firefox、Chrome和Safari,而且对Alt+F4 、右键关闭都起作用。更厉害的是,对移动浏览器也一样好用。
]]>话说阿里云备案很给力啊,第二次使用了,用户体验再次提升。
不但全程免费,而且还免费顺丰寄送照相用的背景布。有任何问题,万网的妹子都会打电话过来通知修改,还会给出修改建议。全程都so easy,呵呵。
阿里云备案地址:http://beian.gein.cn。
另外以前的看官们也应该发现博客的名字变了,原来叫“GSGundam知识库”,这是从博客大巴延续下来的名称,但是备案时不允许用“知识库”之类的名字。后来改了2次,万网妹子都电话过来说不行。
于是干脆不着急,回想了一下自己的历程,发现印证了一句老话“磨刀不误砍柴工”,用现代一点的名言则是引用乔布斯的斯坦福大学演讲中的一句“你必须相信这些片断会在你未来的某一天串连起来”。我到底经历了什么历程呢?从高中开始大概有这些:
1、高中跟着大学老师学了3年专业美术;
2、大学参加了动漫社团,做了1年创作部长;
3、大学自学html和网页开发IDE,并开设了1个校内下载站、1个校内学习站、1个校内论坛;
4、毕业后投过不少简历,选择了重庆一家较大的软件工作做游戏,碰巧后来几乎所有在重庆比较nx的游戏人都从这里出来,或者来这里工作过;
5、在重庆经历过一家创业公司担任主策后,又去了北京想学习运营,于是去了一家现在是页游巨头之一的公司;
6、可能是由于自己学习的特质,在又去了一家大型公司以后,在家参加了一个网页设计师班,这个也在之前的博文中提到了。虽然只有短短2、3个月,但是彻底补齐了我在网页设计和制作上的基本功空白;
7、最后以一家创业公司经历了整个开发流程和运营流程的经历结束了北京之行以后,回到了家乡自行创业;
8、现在的业务主要是网站和游戏。博主也意识到,正这么多年来的经历才造就了自己的今天(虽然还没有什么成绩……呵呵……)
好了,费这么大劲,想说的其实就是,我的博客改名叫“GSGundam砍柴工”了。说这么多也是为了让大家不要觉得这个名字太土……
我的话说完了。[鼓掌]
]]>于是手贱的我自然会想到利用它更多的功能……比方说,网络打印机。
之所以想到这个功能,是因为5年前买过一台佳能 Pixma ip1980,现在功能完好(连外观都跟新的似的),但是由于桌面上实在没有地方放,于是现在每次用都要从放满东西的柜子里取出来,用完又放回去,神烦啊!
废话少说了,实现过程大概是这样的:
1、将打印机连上 EeePC 1005PX 上,打开电源。
2、打开群晖网页界面,选择 控制面板→外接设备→打印机。我这里直接已经识别到了打印机,但是原来的默认设置是不对的。
3、点击要设置的打印机,选择 打印机管理→设置打印机。因为ip1980只是一台打印机,没有其它功能,所以选择了网络打印机。同时启用AirPrint,方便家里的apple设备进行打印。最重要的是选择好打印机驱动程序。由于驱动列表中没有1900系列,所以我选择了可能最相近的2000系列驱动。幸运的是能够进行识别。
4、接着使用群晖助手操作终端来安装设置网络打印机。打开群晖助手,选到打印机设备标签,点击新增按钮。
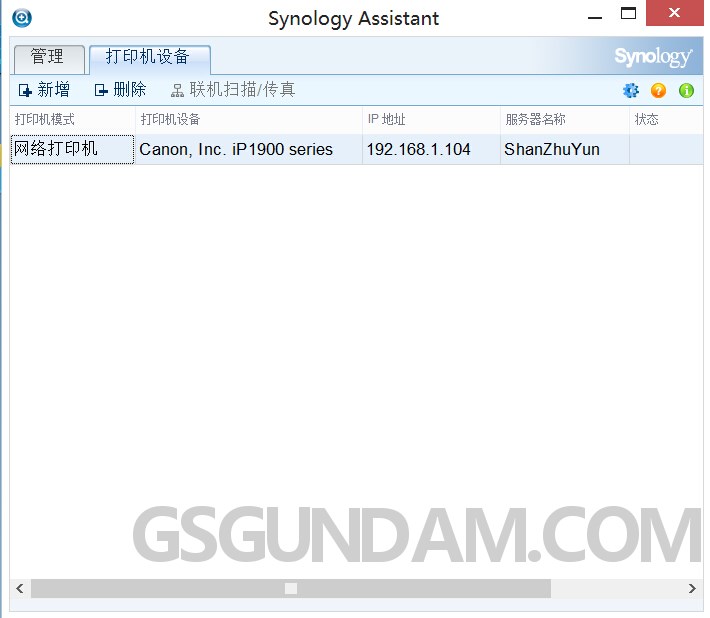
5、可以看到在设置向导里出现了需要添加的打印机,接着下一步,选择正确的驱动程序,安装完毕!

用笔记本测试打印了一下,一切正常,完美!
等抽空试试AirPrint。
话说等下一次有空闲了再倒腾一下看1005PX能不能网络唤醒(虽然理论上不太可能,这是一台笔记本啊喂!)。
]]>这次的问题主要有两个:
1、中部产品展示图片在IE8中不显示;
2、新闻Accordion内容错位。
其实这两个问题都很好解决:
1、随便google一下,就知道是 max-width:100% 造成的,改成 max-width:none 即可;
2、在不同的分辨率下(使用@media),写入分别适应不同的css样式即可。
既然说起来这么简单,为嘛我还要说是不归路呢?不就是因为要针对IE8的唯一CSS Hack么……不能影响其它浏览器……
算起来,我总共绕了三圈:
1、尝试在css里直接hack,这样的话,基本不会增加加载量,也不会影响运行效率。度娘谷哥了一下,的确有效的有这些:
1 | div { |
注意写csshack的顺序,其中:
1.background-color:red\0;IE8和IE9都支持;
2.background-color:blue9\0; 仅IE9支持;
(1)区别FF(IE8)与IE6 IE7
backgorund:orange; FF和IE8背景色将为橘黄色
*backgorund:red; IE6和IE7背景色将为红色
(2)区别FF(IE8)与IE6与IE7
background:orange; FF和IE8背景色将为橘黄色
*background:red !important; IE7背景色将为红色
*background:blue; IE6背景色将为蓝色
(3)区别FF(IE8)与IE6与IE7
background:orange; FF和IE8背景色将为橘黄色
*background:red; IE7背景色将为红色
_background:blue; IE6背景色将为蓝色
(4)区别FF与IE6 IE7 IE8 IE9
color:gray; FF等非IE浏览器字体色将为灰色
color:red9; IE8 IE9字体色将为红色
*color:green; IE7字体色将为绿色
_color:blue; IE6字体色将为蓝色
但是为什么我最终放弃了呢?因为这个在比较简洁清晰的css里还比较好。但是这个项目运用了框架和各种js,css被修改的几率大大增加,导致追踪问题的复杂程度也加大。
说简单点,其直接后果就是IE8的问题解决了,同时又带来了IE9、10、11的问题,分别hack的时候,发现还有更多问题要解决。
记得以前余叔说过,如果一个解决办法在解决这个问题的同时还会带来新的问题,那这就不叫解决办法。
2、直接用JS写CSS样式,这样相比前一个方式会增加加载量和渲染时间,但是只要能解决就好。
这样的话,主要是使用的方法来判断浏览器类型,然后执行jQuery的CSS方法。
比如这样:
1 | <!--[if IE 8]> |
这个方法为什么也被抛弃了呢?说来也怪,明明跟之前CSS一样,但是居然不起作用。第一个方法折腾了太久,这个方法就懒得debug了,直接用最简单粗暴的方法解决好了。
3、最后用了最笨的方式,也是最耗费加载时间和效率的方式,但是也是最安全最不影响其它部分的方式。即是使用的方法来判断浏览器类型,来加载css文件,而这个css文件里只写入针对IE8的样式修正。
1 | <!--[if IE 8]> |
好了,一切问题都解决了。
]]>先来看看漂亮的5.0界面 :)
最初想入手一台nas,完全是因为小小宝的诞生。家里所有人都录像、拍照、录音,结果所有东西都分散了。于是想到需要有一台家用服务器来汇总存储小小宝的各种资料,免得大家的设备出现什么问题,结果再也找不回这些东西。毕竟曾经就因为小本硬盘、台式机硬盘、西数移动硬盘同时挂掉,一部分婚纱照的底片就从此消失了。想起来以前统计学老师上课说的:小概率事件不会发生,但是必然发生……
在网上搜索了很多信息,了解到原来nas不仅仅是我原本想像的作为存储,nas也不仅仅是一堆NB的服务器硬件,它应该是一个软硬件套件,是作为终端设备的延伸,是对终端设备在实用性和易用性方面的扩展。
在充分了解了的西数 MyBook系列、D-Link DNS系列、铁威马、ORICO和群晖(Synology DiskStation)几个主流品牌系列以后,我认定群晖就是我要寻找的The One。尽管在数据安全性、硬盘损耗方面,群晖是普遍遭人诟病的。但是综合它漂亮的界面、良好的操作体验、众多的系统套件(尤其能与百度云同步,在我看来完美的解决了数据安全性问题)。
上网转一圈群晖,差点吓尿,最便宜的不带硬盘999,虽然用料看起来还是不错,但是那性能跟自己买配件比渣得……这哪里是我等屌丝玩得起的东西……
但是,还发现了个好东西——黑群晖。似乎名称取自于黑苹果,说白了就是破解了的群晖系统。有了这东西,不就是我们屌丝的福音么!
琢磨着在网上捣鼓一下硬件DIY吧,之前不是还整了个《TP-Link WR842N 路由散热DIY》么。于是在网上淘了块别人 推荐的主板 ,东西很新,老板人也很好,可惜似乎我自己的内存条跟它不配,折腾了2天,试了5条,只有1条能用,最后装系统还总是失败……幸好我说了,老板人很好,爽快的给我退掉了。(在这个过程中还不忘给我炫耀一下他能一次成功 - -||)。
本来已经无奈的绝望了,认为只能等自己成了暴发户再玩nas了。
幸运的是不知被哪里来的闪电劈中脑袋,想起来家里还有两台闲置的华硕EeePC上网本——一台 1000HE 和一台 1005PX。1000HE比较悲剧,不知道哪个部件出了问题,很难再点亮了。但是1005PX还一切正常,于是赶紧实验。
装机过程完全参考 《NAS群晖DSM 5.0-4458 傻瓜安装教程》,当然,资源也是在那里下的。我这里也提供一个 下载地址 ,其中包含了官方3612xs机型5.0-4458版本的PAT文件(174.9M),Gnoboot-alpha7-4458.img文件(32M),然后是win32diskimager文件(13.6M)。Gnoboot-alpha10其实也是可用的,不过这不是重点,各位看官随便用一个就好。
教程写的是傻瓜安装教程,过程到底有多傻瓜呢?我下面用几行文字说明:
用win32diskimager将img文件写入U盘。(注:U盘要始终用作黑群晖引导,所以就不要想着拔下来了。有米的同志们可以考虑 闪迪酷豆 ,小巧得能让你1分钟就搞丢它。)
把U盘插上小本(没有的同志们淘个 二手的EeePC 1005PX 应该再合适不过了,完全够用,还是整机,保证能用,省的瞎折腾。如果实在有必要,就把 硬盘 换一换就ok了。),设置U盘启动。记得使用网线连接路由,黑群晖不认识它的无线网卡。
3) 开机后屏幕上会出现三个选项,选择第二项gnoboot-me,然后继续,直到出现 DiskStation Login:
然后到PC或者笔记本上运行群晖助手,可以到 官网下载。运行以后应该能查找到1台NAS。
双击,然后按照步骤进行安装,中途选择之前下载的pat文件。
输入1005PX的IP地址。然后就出现了华丽的登录界面。
最后剩下的就是折腾了。总之套件中心的Cloud Sync、Cloud Station、Video Station对我来说是非常有用的。
Cloud Sync连上百度云,随时随地将上传到DSM的文件同步到云端,再不用想我到底拿那3点几个T来做什么 :P
Cloud Station同步PC设备的文件。
Video Station让移动设备能够远端直接播放视频。
手机端主要用得上的是DS File(上传/浏览文件)、DS Video(观看云端视频)、DS Photo+(浏览云端图片)。
当然,其实使用各种设备直接访问网页版控制台,所有功能都能实现,非常方便。
最后,放一个京东的 白群晖展览 ……只能妄想一下了……
]]>Ctrl+F打开顶部搜索栏以后,勾选上Regex就可以使用NB的正则表达式进行搜索了。
比如这次我希望把文件中的以 href=”../i 开头,以 “ 结尾的字符串都找出来。只要在搜索框输入以下文本(其实我说得简单,耗掉了许多时间都没能写对正则表达式,还是靠了Fenix的帮助):
href="../i[/w|-]*"接着就会发现所有符合条件的文本都被高亮了,现在想干什么就干什么啰~
]]>其实制作这么一个 **Font Awesome中文文档网站 **非常简单,但是维护它却是一个长期、需要耐心的工程。
![]()
目前翻译整理了最新的 4.1.0 版,随着其官网的更新,新的内容将同步更新到中文文档网站中。
另外,将原站点改为了单页网站,方便游客浏览。
自从4.0版开始,作者就加入了不少具有中国特色的图标,例如微信、微博等,越来越适合国内站点使用。
希望越来越多的人能成为 Font Awesome 以及** Font Awesome中文文档网站 **的受益者。
翻译过程中难免遗漏出错,如果有任何问题和建议,请不要吝啬言辞,联系我们吧。
当然,也可以直接在本站中留言 ;P
]]>一直都用poco相册做外链,之前的都没问题,怎么现在就不行了呢?
对比能显示和不能显示的图片地址,发现不能显示的前缀均为 img16-c ,试着把 -c 去掉,居然就可以了!(⊙o⊙)
世界真奇妙啊……

需要transition属性,于是刚打完transi几个字后,补全出现的一幕吓到我了,所有浏览器的transition方法全都出来了。

Tab补全后接着出现了更神奇的画面,修改红框的属性,所有浏览器对应的transition属性值一起在改变。

我之前跟Fenix说PhpStorm是我用过的最强大的php网页编辑器,没有之一。现在我更加这么认为了。
]]>说是申请资金,着实没花什么钱,混着别的地方要用的小零件,零零碎碎24块,加11块邮费,一共35……DIY精神么,屌丝的DIY精神,核心就是性价比!
一共购入:
12厘米风扇*1
4Pin口转USB线*1
17_17_2mm 散热片*4
20_14_6mm 散热片*3
20_20_6mm 散热片*1
22_22_6mm 散热片*1
*撬棒+三角片 1
*塑料扎带 100PCS 1
看起来好丰富是吧?我也这么觉得……
好吧,废话少说,DIY开始!
1.拆机是在淘宝下单之前就拆了,为了测量散热片的尺寸,没有撬棒和三角片,所以是暴力拆解,没能办到无损。左下的卡口和右侧的散热口有破损,基本没影响。
可以看到稳定性奇差的Ar9331主控板子很简洁干净,加上esmt的16m内存,整体给人的感觉就是,这个路由的成本真的很省啊,坑死啦……连电容位都不给上满……以后再要败东西一定要听阿宝的:一步到位!


2.快递包来了,NND,这是用屁股坐过?盒子瘪成这样了!

3.来个散热片与裸体路由的合照

4.这次的散热方案因为要用到外置风扇散热,所以三片散热足矣。CPU正面背面各一片,内存上一片。这个方案参考了小米论坛上一位朋友的帖子。
购入的散热片均自带散热贴,撕下蓝色膜就可以直接贴了,很方便。


5.按照尺寸使用了一块20_20_6mm贴在CPU上,一块20_14_6mm贴在内存上,一块17_17_2mm超薄的就贴在CPU背面。反复按压几次就好了。没能在卖家那里看到6mm高的22mm长条形散热片,所以内存没贴满。还是贴满的散热更均匀,但没办法了,将就吧。


6.然后开始真正称得上DIY的散热风扇底座制作。
屌丝就不用高大上的材料了,家里空盒子很多,随便找了个亚麻籽油的小盒子,比较干净也比较结实,表面难看点也没关系。

7.把盒子拆开,将风扇放到希望安装的位置上,勾出轮廓,以便抠风口出来。


8.刚才勾错风口风口了,勾中心有个毛用啊……顺便把螺丝孔位也标注出来。(另外,似乎这张照片上下反了…………)

9.用刀子把风口抠出来,剪刀的切口虽然会比刀要更整齐一些,但是位置难以这么精准,而且容易损伤纸板。
同时用锥子把螺丝孔位戳穿,方便一会从另一边上螺丝。

10.接着也要把四周的底部出风口给切出来。

11.固定风扇啦,风扇配的四根短螺丝就够用。注意,补切了一个线的出口,从侧面出比从下边出更方便、更美观。DIY嘛,在过程中就要不断改进。
如此一来,基本完工了。剩下的就是收尾而已。


12.收尾工作主要是模具成型和外观美化。用人话说,就是贴边和喷漆。
贴边用的是玻璃胶,时间长久而且有韧性。估计盒子坏了,它也不会开胶。家里有小小宝,就放在阳台上用书固定了一天,那结实程度,杠杠的!(感觉家里的书已经很久没有派上过用场了,终于重出江湖!)
家里有一罐7年前买的银色喷漆,居然还没用完。喷出来还挺好看的。照片里加了盖子(就是之前抠出来那块),不使用的时候可以放在上面挡挡灰尘。

13.最后来个成品图。

风扇超静音,还没通电时多口充电头的电流声音大。粗略估算风扇功率是2瓦,也就是这么一直开一年也就18度电。
当然,要响应节能环保嘛,晚上拔掉电源就是。
]]>之前趁降价入手了一台Netcore NW710,一方面家里的TP-Link WR842N在主卧的信号特别差,一方面看NW710有桥接功能,就琢磨着用两台路由器无线桥接组网,扩大信号范围。
1.我使用TP-Link作为主路由。为确保一次成功,排除组网过程中会出现的干扰因素,将本机的IP(IPv4)设置成了固定的192.168.1.101,与主路由(192.168.1.1)网段一致。
2.进入TP-Link设置页面,首先在DHCP菜单中确保DHCP是启用状态(一般都开着的,不然拨号上网都成问题)。
3.在无线网络基本设置中设置好无线网络名称SSID、信道(我这里测试下来9信道使用的人最少,干扰最少,据说6和9能照顾到部分神奇的设备)、频段带宽(不要选自动,20或者40都行,记下来,辅助路由需要与其设置一样)。确保WDS未开启。主路由到此就设置完了。
4.然后使用Netcore NW710作为辅助路由。进入高级设置,先进入网络参数>内网配置,将LAN IP 配置中的IP地址设置为192.168.1.2,方便在出现差错时进行调试。保存并重启。
5.接着保证两个路由同时开启,进入无线配置> WDS配置,点击AP探测,找到主路由的无线SSID,选择连接
6.再进入无线配置>无线基本配置,工作模式选择WDS,参数设置与主路由WR842N一致
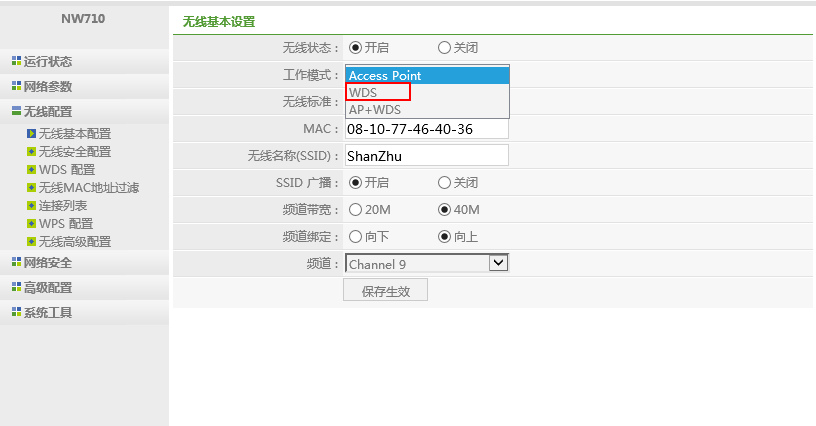
7.最后在不重启路由的情况下,将桥接的辅助路由NW710的DHCP关闭,相关设置在网络参数>内网配置。重启路由,至此设置完毕。
至于为什么没有成功,上网度娘谷哥了一下,也有类似的情况发生,据说不同品牌不能桥接的情况很正常。于是很蛋疼的看着两个不能同时使用的路由,不知道说点什么好……
话说回来,最近TP-Link WR842N掉线十分频繁,看网上的各种吐槽,才了解到原来WR842N算是个阉割玩意,比起来其它型号,缩水十分严重,于是拆机来看,内容果然比较简陋。关键是机子散热差,夏天抽筋频繁不是我一个人的事情,在网上是普遍现象。暂时只能用Netcore NW710代替着,虽然信号要更好一些了,但是也时而会断线,尤其有时网速严重受影响,一搜索,果然又是个缩水玩意儿,便宜果然没好货么?
到淘宝上淘了一些散热配件,准备给WR842N做个简单的散热,看情况能不能好些。
]]>铁拳的设定和模型是逆向的,因为Fenix需要先完成一个模型进行游戏开发,因此铁拳作为极风游戏冠名机甲——Dasher,直接跳过了原画制作了模型。
铁拳的设定稿跟模型稍有区别,主要集中在手臂和“铁拳”上,但身体结构基本一致——大型4喷口助推器,巨大的肩甲,硕大的前臂和拳头。
废话少说,看看吧。透视似乎还是有问题,但线条比之前流畅了。

熟悉某个游戏的人应该能很容易发现原型的出处。
近乎完全颠覆Fenix上一版的设计,只保留了悬浮底座。采用黄色光来显示其能治疗的特性。
主要是原型和设计方向太一致了,所以直接用了……(好吧,其实是我懒了)
炮台尾部修改了2次,我已经画晕了,最后透视出问题了,各位看官将就吧……

很久没画原画了,生疏得很,随便批。反正Fenix已经开始制作了 ;P
追猎者:较上一版本修改幅度较大,只保留了步行机和4炮管武装的设计。采用鸟足设计以增大步幅,增加手臂关节突显武器特色,修改开放式驾驶舱为封闭式以增加神秘感。

雷神:保留电磁轨道炮和坦克底座的大体设计思路,修改较少。减少高度、增加宽度来显示厚重感,并通过灯光来渲染整体效果。

PS:知道RF签名意思的童鞋都是老朋友了哈~
]]>将图标意义改得特别明确以后,准备重新提交应用,打开虚拟机,结果……
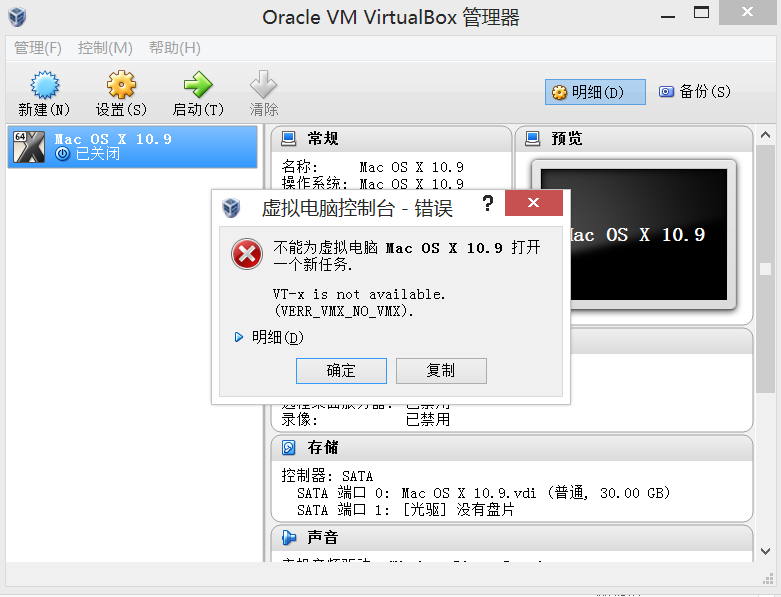
你们这是要闹哪样……
之前也出现过这样的问题,但是正赶上加装SSD,所以重装了一次系统,问题也就解决了。这次又发生了这样的事情,为毛?
大概捋了捋,其实问题应该很明确了,因为两次Vbox不能使用都是在安装了VS2013以后的事情,也就是说多半都是微软的Hyper-V占用了CPU的虚拟化通道。
随便Google了一下,还好不算复杂,关闭Hpyer-V就可以了。

我只能淡淡的忧桑了……
]]>绝对是史上Windows用VBox安装OS X 10.9 Mavericks的最强教程,没有之一!
由于虚拟机不支持 Apple Quartz Extreme/Core Image, 需要 Quartz Extreme 的应用软件例如 iBooks Author,Pixelmator,SketchBook 等不能在虚拟机下使用 。
安装步骤
⑴ 下载:http://pan.baidu.com/s/1hqebqYw
VirtualBox-4.3.6-91406-Win.exe
Oracle_VM_VirtualBox_Extension_Pack-4.3.6-91406.vbox-extpack
HackBoot_Mav.iso
OSXMavericks2.iso (解压 OSXMavericks2.part1.rar, OSXMavericks2.part2.rar, OSXMavericks2.part3.rar)
⑵ 双击安装 VirtualBox-4.3.6-91406-Win.exe 及 Oracle_VM_VirtualBox_Extension_Pack-4.3.6-91406.vbox-extpack
⑶.1 在 VirtualBOX 新建虚拟电脑
名称 : Mac OS X Mavericks
操作系统 : Mac OS X
版本 : Mac OS X 10.9 Mavericks (64 bit)

⑶.2 内存分配最少 2048 MB 以上

⑶.3 创建新的虚拟硬盘

⑶.4 选择 VDI (VirtualBox Disk Image)

⑶.5 选择 Dynamically allocated

⑶.6 设置虚拟硬盘位置及大小, 建议大小为 20 GB (最好 40 GB)

⑷.1 打开 VirtualBOX 虚拟机的设置, 在设置的系统 -> 主板, 去掉 “软驱”,取消勾选 “启用 EFI”

⑷.2 系统 -> 处理器, 选择双核 CPU 数量 = 2

⑷.3 显示 -> 显卡 -> 显存大小设置到最大 128 MB
勾选 Enable 3D Acceleration

⑸.1 在设置的 Storage -> Storage Type 属性 Controller SATA 的光盘图标 Choose a virtual CD/DVD disk file 选择HackBoot_Mav.iso 文件

⑸.2 在 HackBoot_Mav.iso 的启动引导下, 如下 OSX Boot 页面出现后,在虚拟机菜单 CD / DVD Drive -> Choose a virtual CD/DVD disk file 选择 OSXMavericks2.iso 文件

⑸.3 按键 F5刷新后, 图标标签变为 OS X Base System,回车开始安装系统

启动过程可能停在这里一分钟

⑸.4 开始时, 选择安装语言

⑸.5 安装系统开始时,找不到任何有效的硬盘 , 使用菜单 实用工具 ->磁盘工具 格式化虚拟硬盘

⑸.6 左边点选硬盘, 选择 “抹掉”, 名称 Name 录入 “Mavericks”, 然后点击 Erase 抹掉

⑸.7 格式化完毕, 关闭磁盘工具后, 点选 Mavericks 磁盘, 点击 安装

安装系统需要 30 分钟以上

安装 Mac OS X 系统完毕。

⑸.8 安装系统后, 需要重新启动, 虚拟机选 Close 及 Power Off 关闭虚拟机

⑸.9.1 关闭 Mac OS X Mavericks 虚拟机后, 在设置的 Storage -> Storage Type Controller SATA 属性 退出OSXMavericks2.iso

⑸.9.2 CD / DVD Drive 的光盘图标 Add CD/DVD Drive 选择 HackBoot_Mav.iso 文件

⑸.10 在 HackBoot_Mav.iso 的启动引导下, 如下 OSX Boot 页面出现后

⑸.11 在虚拟机菜单 CD / DVD Drive -> Choose a virtual CD/DVD disk file 选择 OSXMavericks2.iso 文件

⑸.12 按键 F5刷新后, OSX Boot 图标标签变为 OS X Base System(绿灯亮),回车再次进入安装系统

启动过程可能停在这里一分钟
⑸.13 再次进入安装系统,这次选实用工具菜单 -> 终端

⑸.14 进入终端, 安装内核扩展,依次输入命令

⑸.15 依次输入命令如下:
umount /Volumes/Maverickshdiutil attach /dev/disk0s2 -mountpoint /Volumes/mntcp -rp /Backup/Kexts/ElliottForceLegacyRTC.kext /Volumes/mnt/System/Library/Extensionscp -rp /Backup/Kexts/FakeSMC.kext /Volumes/mnt/System/Library/Extensionscp -rp /Backup/Kexts/NullCPUPowerManagement.kext /Volumes/mnt/System/Library/Extensionschmod -R 0755 /Volumes/mnt/System/Library/Extensions/ElliottForceLegacyRTC.kextchmod -R 0755 /Volumes/mnt/System/Library/Extensions/FakeSMC.kext chmod -R 0755 /Volumes/mnt/System/Library/Extensions/NullCPUPowerManagement.kextchown -R root:wheel /Volumes/mnt/System/Library/Extensions/ElliottForceLegacyRTC.kextchown -R root:wheel /Volumes/mnt/System/Library/Extensions/FakeSMC.kext chown -R root:wheel /Volumes/mnt/System/Library/Extensions/NullCPUPowerManagement.kexthdiutil detach /Volumes/mnt⑸.16安装内核扩展后, 退出终端后, 必须等待虚拟机的硬盘指示灯熄灭, Power Off 关闭虚拟机

⑹.1 关闭 Mac OS X Mavericks 虚拟机后, 在设置的 Storage -> Storage Type Controller SATA 属性 CD / DVD Drive 的光盘图标 Add CD/DVD Drive 选择 HackBoot_Mav.iso 文件

⑹.2 在 HackBoot_Mav.iso 的启动引导下, 如下 OSX Boot 页面出现后 , 使用右键选择启动 Mavericks (绿灯亮),回车开始启动系统

⑹.3 启动 Mac OS X Mavericks 虚拟机文件后, 进入 Mac OS X 设置国家

⑹.4 输入用户名称和用户初始密码

⑹.5 完成其他安装步骤后,不要启动 iCloud 也不要注册, 并成功进入 Mac OS X 系统

如需要更改时区 (左上角的 苹果菜单 -> 系统偏好设置(System Preferences) -> Date & Time)
如需要更改语言 (左上角的 苹果菜单 -> 系统偏好设置(System Preferences) -> Language & Text), 重启后才更新
⑹.6 在 苹果菜单 -> 系统偏好设置(System Preferences) -> “安全性与私隐” 里面选择 “任何来源” (用于安装 MultiBeast)

⑹.7 使用 Mac OS X Mavericks 的 Safari, 下载 http://pan.baidu.com/s/1bnb3D9P 及自动解压 MultiBeast-Mavericks-Edition-6.0.1.zip
下载 MultiBeast 6.1 更新 : http://pan.baidu.com/s/1sjCUOGH
⑹.8 自动解压后的文件是在 下载 文件夹里面, 双击 MultiBeast 启动安装

点选 Quick Start, 点选 EasyBeast

⑹.9 点选 Build 及最后点击右下角的 Install 开始安装

⑹.10 等待几分钟后,安装完毕后, 在 Mac 关机。

⑹.11 Mac关机及关闭 Mac OS X Mavericks 虚拟机后, 打开 VirtualBOX 设置虚拟机, 在 Storage -> Controller SATA 属性退出 HackBoot_Mav.iso 文件

⑹.12 及在虚拟机设置的 系统 -> 主板 勾选 “启用 Enable EFI”

⑹.13 启动虚拟电脑, 会直接启动 Mac OS X Mavericks 虚拟硬盘, 以后并不需要 Hackboot_Mav.iso 光盘文件的引导

⑺ 重新启动虚拟电脑后, 可选择挂上磁盘映像 xcode_5.0.1_gm_seed.dmg 安装 Xcode 5 及command_line_tools_os_x_mavericks_for_xcode__late_october_2013.dmg 安装 Command Line Tools

⑺.1 使用 Mac 的终端, 取消强制 iOS 项目的签名
SDKFILE=”$(xcode-select –print-path)/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS7.0.sdk/SDKSettings.plist”
sudo /usr/libexec/PlistBuddy -c “Set :DefaultProperties:CODE_SIGNING_REQUIRED NO” “$SDKFILE”
sudo /usr/bin/plutil -convert binary1 “$SDKFILE”
复制代码
⑺.2 在 Xcode 测试编译适用于iOS的终端 MobileTerminal 项目
下载 MobileTerminal 项目文件夹 :  mobileterminal-520-A.zip (234.82 KB, 下载次数: 73)
mobileterminal-520-A.zip (234.82 KB, 下载次数: 73)

⑻.1 本地机器连接到虚拟机, 除了挂上磁盘映像以外, 还有 2 个方案, 方案一 使用SMB 文件共享
SMB文件共享从其他设备访问Windows 7
在 Windows 7的机器 控制面板 -> 所有控制面板项 -> 网络和共享中心 -> 进阶共用设定”
参考 : http://support.apple.com/kb/PH13882?viewlocale=zh_CN
在 Mac 虚拟机的设置

⑻.2 本地机器连接到虚拟机, 方案二 本地机器使用 PuTTY 及 WinSCP 远程登录
⑻.2.1 在虚拟机的设置选择 网络 -> 端口转发 Port Forwarding

⑻.2.2 添加规则 TCP 协议 主机端口 2222 转发 虚拟机端口 22 如下

⑻.2.3 Mac 虚拟机, 苹果菜单 -> 系统偏好设置 -> 共享 内启动 远程登录

⑻.2.4 本地机器用 PuTTY 或 WinSCP 连接到虚拟机, 使用本地机器地址 localhost 及端口 2222


相关帖子
在 Win 7 下使用 VirtualBOX 虚拟机安装 OS X 10.8 Mountain Lion 及 Xcode 4.5 http://bbs.weiphone.com/read-htm-tid-5329046.html
iOS 7 开发的好东西【本地下载】http://bbs.weiphone.com/read-htm-tid-7244970.html
为了解决这个让人伤感的问题,irst也折腾了无数遍,硬盘检测了若干次,免费杀毒软件挨着用,仍然无济于事。
啊,对了,这个问题是windows8.1的taskhostex.exe进程间歇性抽风发作,占用磁盘读写60%-100%,查遍谷歌度娘也没找到解决方法,哪位大侠有高招请赐教。
好了,回到正题,谷歌上有一条来自ms community的建议,说是使用标题中提到的Windows Denfender Offline进行木马病毒排查。

抱着试一试的态度,去微软官网下载了beta版安装程序(官网说8.1要使用beta版)。进入流程就傻眼了,还要下载文件……立马开始搜索mdo的iso文件,但是…网上居然没有!于是开始自己下载。历经1个小时和6次重试,终于把镜像下载到本地了。刻盘,重启,进wdo扫描,无果……
想到既然都下了,那还是贡献出来吧。
]]>在原来最大适应1200像素的基础上,新增了1600像素宽度适应。优化了各种分辨率下的显示,部分元素做了特殊处理。

新版本的账单分期计算器安卓版已经在豌豆荚上架了( http://www.wandoujia.com/apps/com.dashgame.billstagingcalc )。
因为电脑最近抽筋得厉害,所以干什么效率都低,加上还有比这个 更优先的工程,所以iOS和Windows Phone版的账单分期计算器就延后了。
]]>以上这些,都不是今天的论题。
这么火、这么虐的游戏只在手机上怎么行?所以有人用html5复制了Flappy Bird,除了画面比原作要更简单,核心绝对一样,喜(nue)大(ren)普(wu)奔(jin)吧!
有一位兄台给我分享了这个项目,并且是开源的,代码就在GitHub上, https://github.com/chairuosen/FlappyBird-By-JS
当然你可以在这个网址(http://bird.ruosen.io/)上找到这个游戏,获得高(zi)分(nue),并且与其他人进行排名比较。
[

这个更巧了,之前就跟Fenix学习AS3来着。这部分个人有点小骄傲,因为感觉自己起点比较高。但是在学习的过程中才发现,原来我还有很多可学的。
原因很简单:所有的课程都为网页设计服务。
从画面效果、实现技巧到互动体验,全都围绕网页设计来。因此例如水波的制作,循环动画的处理,都用了我以前没用过的方式,也学到了一些广告的处理方法。
BTW,刘俊言老师以前就是做互动广告的。
好了,最后展示一下劣作吧,只有3个比较拿得出手,自己最喜欢大门五郎那段。
Loading
大门五郎
W3CSchool CSS 测验
]]>这期间我非常投入,正好在那之前刚学习过actionscript3,加上自己在大学期间就开过班级学习站,对网页开发其实特别有感情。以现在来看自己大学的第一个站,技术方面当然是烂到爆了,但是内容上却十分有想法,虽然是自己兴趣建站,到后来吸引了好几个同学来提供自己版本的复习大纲,整个年级更是几乎所有人都来关注网站。
好吧,有点扯远了。
整个课程讲得并不是那么深,主要以打底子为主。但是绝不是敷衍了事,我是真真实实的从中学到了语义化结构化的思维和方法。
同时我也感受到,前端技术很重要,但它是以实现设计效果为目的的。两者相互依存,才让用户在网站的浅度操作上得到良好体验。
这期间有很多作业,不少作业也很有特点。但是印象最深刻的,是刘老师即兴发挥,让我们仿暴雪官网首页。作为初学者,这个命题难度够呛,作为学委,我又必须带好头尽量实现。
虽然现在再做这样的站十分轻松了,但现在看来这个作品也不差,可见当时自己还是下了功夫的,哈哈。废话少说了,看看吧。


这个需求基本上可以概括为两点:
背景图覆盖全屏
背景图要做到浏览器自适应(同时适应高度和宽度)
脑袋里理了一下思路,直接用CSS设置背景基本上不太可能办到了。于是开始自己整理js实现的思路。
将图片独立出来,用CSS控制它position:absolute; 然后放置到最底层z-index:-1;
使用js控制其跟随页面变化,但是考虑到图片变形,因此不能直接跟着页面宽高而变化,需要按照比例。例如宽度如果小于高度与宽度的比例值,则宽度不能再缩小了,只缩小高度。
今天心情比较舒畅,索性把这个功能做成了一个插件。由于托管在Github,可能有些时候直接下载资源包会有问题,可以到 https://github.com/gsgundam/jQuery.resBg 直接引用或拷贝文件。
效果基本没问题,下面用一个html文件讲解使用方法(特别说明一下参数position,主要用途是控制是否可以查看整个背景,简单来说就是使用absolute时可能出现滚动条,而fixed不会):
1 |
|
欢迎有人来指出问题,提出建议。我会尽量完善。
]]>上传发布版本之前需要将Release处均改为发行版设置。
包括下图中的部分,开启方式为 Product → Scheme → Edit Scheme。

然后通过Product → Archive进行归档。在所有信息都正确的前提下,可以直接选择发布企业版或上传到APP STORE,这样就不用专门过一遍Application Loader了。
#2. Team成员
在Xcode中点击.xcodeproj项目文件,在中间窗口里点击Team项目,选择一个有效的成员。否则不能正常导出发行版。
#3. 证书与授权
基本参照Appstore发布流程中的步骤即可。网上文章非常多,就不赘述了。附送一篇文章地址:http://blog.csdn.net/htttw/article/details/7981395。
]]>#1. 安装
Xcode就不用说。都2014年了,一定要使用Xcode5,不然没法发布iOS7应用。
接着下载PhoneGap就好了(点击这里下载)。有个比较严肃的问题,OS X下实在找不到安装版的PhoneGap到底去了何方,所以直接下载了2.9.1版使用。
好吧,这样直接就安装完了。是不是感觉很简单的样子?
#2. 新建项目
使用PhoneGap/create命令创建项目,例如
1 | $ ./create /Users/gsgundam/Documents/Workspace/Xcode/iphone com.dashgame HelloWorld |
注意,项目目录要事先创建好,同时赋予读写权限:chmod 777
如果遇到empty folder的错误,那就把iphone目录清空一下就好了。
如果什么都没有打印,那就说明成功了。进入刚才的目录,可以看到一个.xcodeproj后缀名的文件,双击使用xCode打开。
#3. Xcode设置
默认打开目录结构如下:

与Android项目一样,www文件夹就是网页目录地址,如果直接拷贝Android项目过来,需要将cordova.js替换为iOS版的,就在之前下载的PhoneGap2.9.1的包中。
要修改安装后的显示名称,在xxx.info.plist文件中的Bundle display name,如下图。
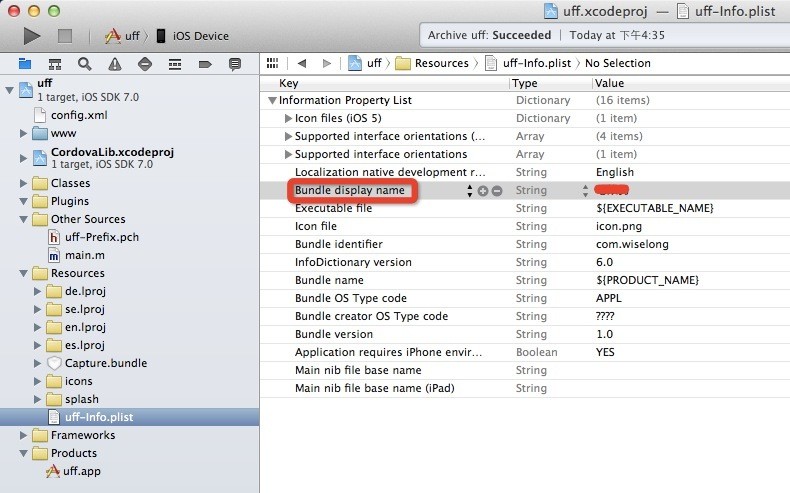
在Classes/AppDelegate.m中添加下面代码修改默认启动文件,按照实际目录修改!
1 | self.viewController.wwwFolderName = @"www"; |
点击菜单Product → Build,出现带Success的锤子图标,就成功了。
网上还说可以看看Products文件夹中,如果有一个.app文件,那就把它拖到iTunes中再拖出来就成了.ipa文件,可以直接在越狱机上安装了。我没有进行尝试,只在本地黑苹果调试成功以后,就开始上传工作了。
]]>解决办法:为activity标签中的configChanges添加screenSize属性,如下:
android:configChanges="orientation|**screenSize**|keyboardHidden"
原因:通常情况下,PhoneGap在设备旋转屏幕后不能正确获得屏幕大小导致出错。网上还有其他办法,比如调低sdk版本,但是个人发现在PhoneGap 3.3.0不适用(很多标签和代码已经与2.x不同了)。
#2. versionCode和versionName
由于不是程序出身,可能开始对这两个东西的概念不是太明确,所以也没管他。
老程序猿们估计都不会认为这个也算问题。
但是我在实际发布的时候发现了自己的问题,因为在更新版本的时候,不知道应该修改哪个。
最终依靠度娘和谷歌解决了这个疑问:versionCode是给开发团队和App商店用的,用以标记有版本改动,与build概念很像;versionName是给用户看的,没有实际的用处,只是给用户一个更简单明确的途径了解应用现在是那个版本。由于versionCode可能迅速的叠加得很大,导致用户无法正确识别版本,因此后者的作用也很大。
所以在发布公开版本时,两个都需要修改。
#3. 发布与数字签名
问题:在Google Play中提交应用,提示数字签名不为发布版,以及应用没有经过Zipalign对齐。
同样的问题没有出现在豌豆荚和亚马逊,应该是因为这二位不关心这两个问题。
解决办法:
在Eclipse中,使用ADT Export Wizard进行签名比较容易。右键单击应用程序工程,如图选择
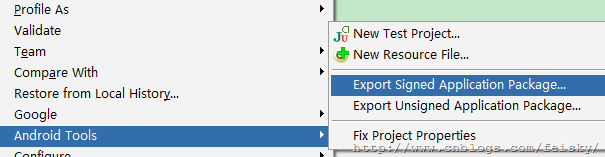
选择证书的存放路径,填写相关资料,完成,即可生成被签名的apk文件。如下图所示:
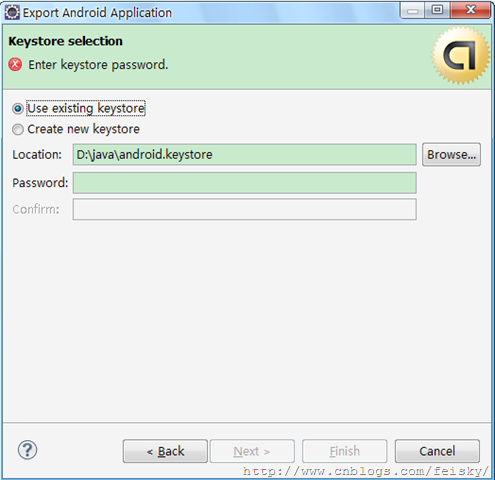
如上图所示,可以在这里选择Create new keystore来创建一个证书。输入密码,点击下一步,填写相关信息,如下图所示。
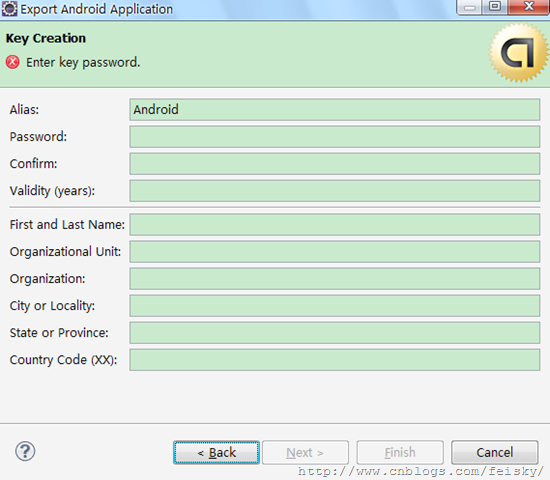
ADT导出项目自动Zipalign对齐,因此问题直接解决。
#4. 升级推送
参考以下代码即可,但是必须在xml中开启相关权限,包括网络、挂载、安装、存储。
1 | import java.io.BufferedReader; |
#1.安装
首先是JDK(点击这里下载)。不安装的话不能正常安装Android SDK。安装成功检测:启动DOS窗口start–>run–>cmd,在DOS窗口中键入:java -version,如能显示版本信息说明安装正常。
接着是ADK(点击这里下载)。安装完之后是一个Android SDK Manager,你需要下载以下组件(至少包含一个完整版本的文件内容),可能需要较长时间:
再来是Eclipse(点击这里下载)。强大的IDE,不用多说了吧。安个标准版就好。
接着给Eclipse装上ADT插件。打开Eclipse中的菜单 “Help”->”InstallNewSoftware”进入软件安装界面,点击“Add”按钮,Location地址栏填入:https://dl-ssl.google.com/android/eclipse/。
最后到了我们的主角,PhoneGap(点击这里下载)。需要注意的是,PhoneGap的最新版本似乎只支持命令行安装,可以根据官方文档安装Node.js以后直接安装,也可以下载2.x版本后备用。
#2.创建PhoneGap项目
1.在eclipse中新建Android Project。
2.在项目的目录下,新建两个文件夹:
/libs/assets/www
3.进入将刚刚下载并解压的PhoneGap包里Anroid目录,我们需要的资源都在这个目录下。
复制cordova.js这个文件(具体名称视下载的版本而定,如果是直接安装的,从新建的PhoneGap项目中拷贝一个出来即可),粘贴到/assets/www目录下。
把cordova.jar文件复制到/libs目录下(可能会发现在新版本的PhoneGap中找不到该文件,这里我提供一个3.3.0版本的,点击这里下载)。
再把xml目录复制到android项目的res目录下。
4.在/assets/www下建立index.html文件,内容看起来像这样:
1 |
|
5.将以下权限配置的xml内容复制到AndroidManifest.xml文件中(这里粘贴了所有权限,在实际项目过程中注意清除掉没用的):
1 | <supports-screens |
6.将以下内容添加到AndroidManifest.xml文件的activity标签中:
android:configChanges="orientation|**screenSize**|keyboardHidden" (关于screenSize,之后会专门说明)
这是为了保证机器在横竖屏切换的时候不会重新执行Activity的onCreate方法;
7.AndroidManifest.xml最后看起来会像这样(注意,package包名称部分的com.example.shawn应该修改为你自己的,忘了也没关系,很容易debug到):
1 |
|
其中
android.intent.action.MAIN表示是最先启动的的界面;
android.intent.category.LAUNCHER决定应用程序是否显示在程序列表里;
另外需要注意的是:
<activity android:name="outer" android:configChanges="orientation|keyboardHidden" android:label="@string/app_name" >我们的
8.在刚刚新建的Android Project中找到libs目录,在cordova.jar上点击右键,选择 Build Path->Add to Build Path。
9.最后再修改下src下的Java主文件(如果没有就自己创建一个,包名要记得跟之前在AndroidManifest.xml中写的一样):
1)添加import com.phonegap.*;
2)删掉import android.app.Activity;
3)将outer继承为DroidGap;
4)把setContentView()这行替换为super.loadUrl(“file:///android_asset/www/index.html”);
5)最后看起来就像这样:
1 | package com.example.shawn; |
super.loadUrl("file:///android_asset/www/index.html");是加载首页。
然后就可以Run一下项目,在模拟器下跑跑看,成功的话会出现Hello World的界面。Great,搭建成功!可以将网页成功的封装为Android应用了!

先看看效果:

其实挺简单的,只要用好CSS3的特性,很多效果都很好做,完全不需要教程。所以直接上代码了。
【Html部分】
1 |
|
【CSS部分】
1 | *{margin:0;padding:0;list-style-type:none;} |
很关键的是,作业要求很严格,不能瞎拼凑。什么叫严格?
要制作的网站,它的所属对象是存在的。也就是说不能为一个空想的需求方服务。所以我的作业往往都是寻找一些已经有网站的企业或单位,试图超越他们原来的设计。
站点分析。通过需求方的文化背景、面向群体等多个方面进行分析,由此来总结出设计思路和大致搭配。
素材整理。根据站点分析来整理出一些资源需求,到网上去寻找一些可参考或可使用的素材,把一个理念上的东西转变为一些可见的元素,帮助站点实体化。
草图制作。这步倒不是必须的,但是对于页面构图很有帮助,不至于大返工。
实际做的时候着实压力挺大,有时候努力去做了,也不一定能达到想要的效果。但是的确收获了很多,因为通过作业点评,可以知道自己哪些地方没处理好。(比如虹元素的首页我原来是设计的彩色的,为了呼应“虹”这个主题。但是带来的后果就是整个画面色彩过多,难以突出视觉焦点。刘俊言老师让我课后换成黑色试试。果然一下就把版面压住了。)
这些实操的课程让我受益匪浅,很多页面我都有自信超越了原版设计。展示一小部分吧(有好有坏,但是都不至于太糟)





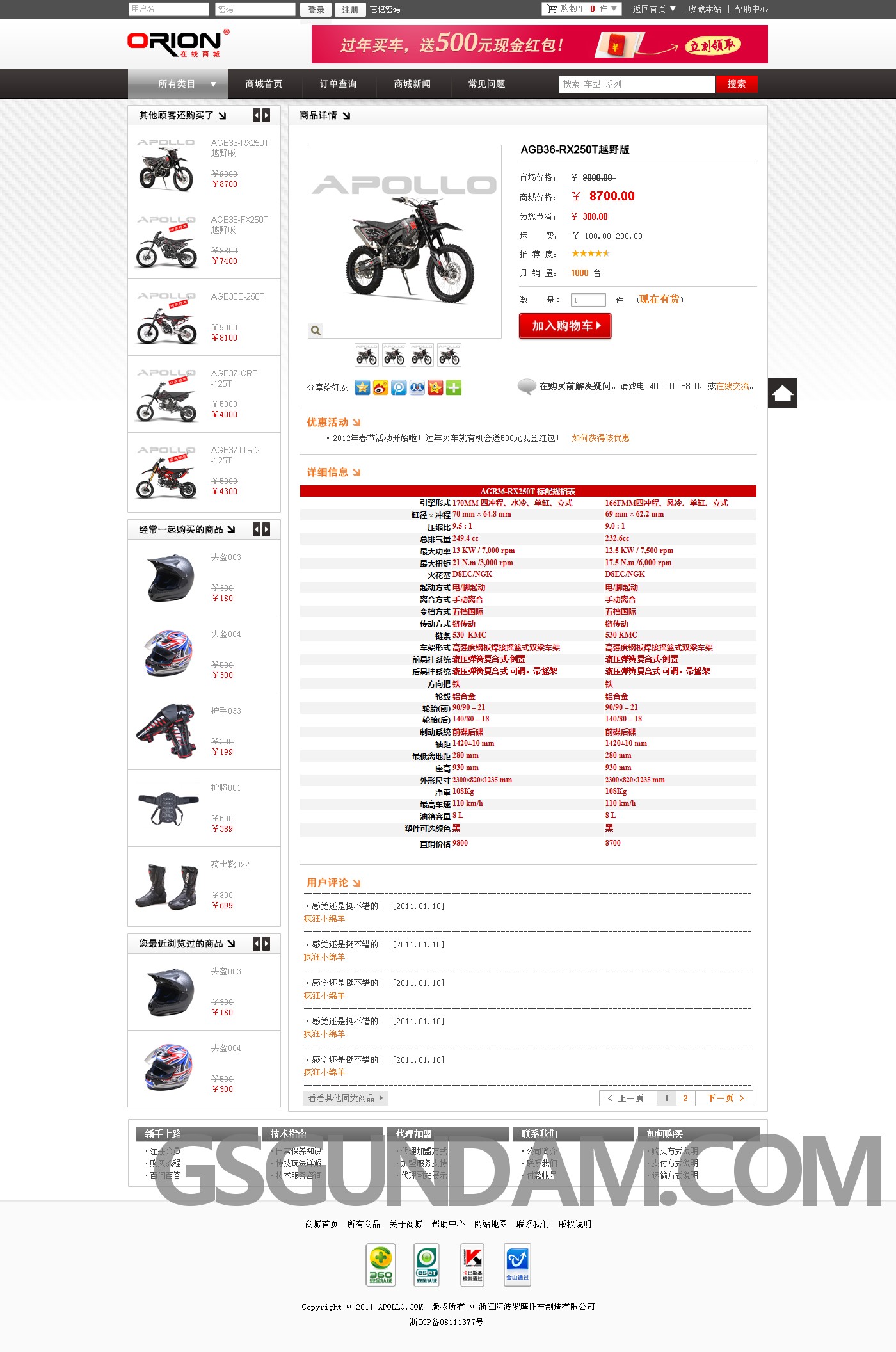

不过功夫不负有心人(随便乱用的词……),在查阅资料时,无意发现了一枚小巧而实用的神器——**emmet(ZenCoding)**。
![]()
它对我来说最重要的作用就是快速编写HTML代码。它能快成什么样子呢?
比如下面这部分代码
1 | <nav id="navbar"> |
看着这种东西会觉得php才能勉强算是救星吧?其实只要下边这段话,加上Ctrl+E就解决了!
1 | nav#navbar>ul>li.item$*5>a |
如何,是不是很棒?
这个插件支持的IDE多得吓人,Eclipse自然是支持,连Notepad++都有!不过对我来说支持Dreamweaver就心满意足了。
官方下载地址:
点击这里顺便看看官网资料:http://emmet.io/download/ ,或者直接点这里下载:Emmet.zxp
我安装的Adobe套件是CC版,下载以后一路next就安装好了。(前提是你已经安装了Adobe的Extension Manager(扩展管理器),神马?你居然没有安?没关系,赠送一个,点击这里下载。)
emmet的默认快捷键是Ctrl+E,如果没有快捷键冲突,那么你输入下面这段代码,按下Ctrl+E以后
1 | nav#navbar>ul>li.item$*5>a |
就应该可以看到以下内容了
1 | <nav id="navbar"> |
非常好用,强烈吐(ji)血(qing)推荐,网页前端苦力必备。
]]>最近主要都在做网页方面的东西,虽然现在已经使用了超越当时太多的技术和技巧,但当时星狮创想还是从网页设计方面给了我很好的启蒙,让我现在感到很感激。
当时其实并不是要想学个饭碗技能,只是碰巧想学个东西,而阿宝报了这个班,干脆就由我来学习了。没想到到现在派上了大用场。
让我不得不佩服乔布斯所说:“你现在所经历的将在你未来的生命中串联起来。”
06班有幸是刘俊言老师(星狮创想的创立者,真正师范出身)全程教授。他的讲课风格很温和,思维也很全面,优点在于让有意愿学习的人能很快理解课堂内容。(因为星狮创想当时实行一次缴费终身听课制,所以后来也参加了07班的课,廖俊枫老师真的很优秀,但是完全是启发型的,而且语言上属于决不留情的那种……不适合我的风格……)
由于自己有一些PS技巧和美术功底储备,当时在星狮创想莫名其妙的就成了学委,鸭梨山大……不过也督促我要尽全力做好每一次作业。
说到作业,就展示一部分劣作吧(第一阶段的第一部分都是各种练习,尤其PS方面非常多,网页设计部分下次再放)




度娘了一下,轻松解决。
我的问题是因为不知道为什么设置暂存盘的地方,一个硬盘都没勾选……
另外,如果没勾选主硬盘所在分区,也可能出现问题。
勾选位置在 编辑 > 首选项 > 性能
今天邮箱收到百度统计报告,下载下来,曲线是flash+xml的,但需要到Adobe网站上进行安全设置。
为了保护本地文件的安全,在默认情况下,FlashPlayer不能直接访问本地文件。如果您需要让FlashPlayer能够访问指定的本地目录,您可以采用以下一些设置方法:
1.
确认FlashPlayer要访问的本地目录或文件
首先您需要确认让FlashPlayer自动访问的本地目录或文件,如:本地的E:local。然后在这个目录中放置Flash文件(swf格式)以及Flash要访问的所有文件,如xml、txt、jpg、png等格式文件。
1.
登录Adobe官方网站进入FlashPlayer安全设置页面
URL地址:
http://www.macromedia.com/support/documentation/cn/flashplayer/help/settings_manager04.html
在这个页面中您会看到一个Flash的设置面板
1.
在全局安全设置中选择“始终允许”;

1.
点击“编辑多个位置”弹出编辑下拉菜单

1.
点击“添加位置”弹出设置安全路径面板,如图1-4

1.
点击“浏览文件夹”,选择您要设置的FlashPlayer安全访问路径,如图1-5;

1.
点击确定后,您就可以在“始终信任一下位置的文件”中看到已设置的安全路径,如图1-6;

到这一步,目录E:local就已经被成功设置成为FlashPlayer的安全访问路径,FlashPlayer在本地运行时访问这个文件夹下的文件将不再受限制。
]]>
WordPress的功能很强大,可扩展性也很强大,博客搭建完成之后,需要不断地改进完善,这样自己的博客才能够越来越好。
polaris的博客搭建完成后,想要备份博客,备份方法有多种,其中有一种是通过WordPress Database Backup插件实现。该插件提供了定期备份功能,有一个选项是发送备份数据到指定的邮箱中。然而设置之后却发现无法发送到指定的邮箱中。当时也就算了,没有细细的研究。
今天想要在博客上实现评论回复邮件通知的功能,这样有利于吸引游客再度光临。在网上一查阅,发现Windows主机+IIS+php配置,不支持php的mail()函数发送邮件,只是简简单单的提供smtp组件,无奈评论回复和数据库备份的邮件发送都不能实现。而国内很多服务器都是该种配置,polaris购买的空间就是这种配置,于是需要找到一种解决方法。
在网上一搜,看到好多关于wp-mail-smtp插件的教程,一一测试,可是发现没有一个好用。看到这些文章的评论,有不少人跟polaris一样,按照他们的方法配置怎么也不成功,而且改用了若干邮箱类型,都是以失败告终。通过自己的不断尝试,终于解决了。
借用网上的一些翻译结果。
From Email:发送者的邮件地址,也就是对方收到邮件后看到的发件人地址。From Name:发件人姓名。Mailer:Send all WordPress emails via SMTP.Use the PHP mail() function to send emails.这里要注意一下,有的朋友的空间不支持mail()函数,通常是Windows环境的主机。如果不支持此函数,那么就选择上面的那个选项。SMTP OptionsSMTP服务器设置,也就是邮件发送服务器设置,如果设置错误就不会给留言的人发送邮件,当然,也不会把备份的数据文件发送到你的邮箱中。SMTP Host:QQ邮箱的是:SMTP.QQ.COM 谷歌的SMTP.GMAIL.COM 126邮箱是:SMTP.126.COM (大小写无所谓)SMTP Port:QQ邮箱的是:25谷歌的是587,126是25。QQ帮助里说端口号是465或587,试了没成功,不知道原因。Encryption:是否启用加密连接No encryption.无加密Use SSL encryption.采用SSL方式Use TLS encryption. This is not the same as STARTTLS. For most servers SSL is the recommended option.使用TLS方式.polaris提醒您,此处是关键。一会儿详细讨论这点。Authentication:用户验证No: Do not use SMTP authentication.Yes: Use SMTP authentication.如果你这里用的是免费邮箱,那么都是选择yes,如果不验证的话恐怕垃圾邮件就满天飞了吧.下面的这两项,就是你的用户名和密码。Username: 注意:这个用户名是全名,如我的:polaris_bjx@126.comPassword: 密码就不公布了,这个插件作者比较奇怪,密码域竟然是明文显示而不是***,着实让人不爽。update option全部填写后点此更新设置。Send a Test Email发送一个测试邮件To: (这里填写邮件地址)好了,设置完了,测试下结果。如果看到有:
Test Message SentThe result was:bool(true)那恭喜您,您的设置成功了。如果您测试失败,那请您接着往下看。
在网上可以看到,通过网上看到的方法设置,测试失败的比比皆是吧。polaris也一样,试了n多次都失败。不过幸好,最后终于成功了。在此分享两种失败解决方法:
在此引用柳絮轻飞的博文《配置 WP Mail SMTP 的一点经验》:
今天给wordpress博客增加评论回复邮件提醒功能,选中了WP Mail SMTP插件,配置QQ邮箱的参数一切正常,但是发送测试邮件的时候提示:ERROR: Failed to connect to server: Unable to find the socket transport “ssl” – did you forget to enable it when you configured PHP?既然是ssl错误,习惯性的从php.ini中相应行打开支持,(extension=php_openssl.dll),服务器是windows主机,重启iis发现竟然还是不支持?查明原因是php_openssl.dll这个链接库无法装入。
上网查了一下资料,原来openssl扩展是依赖于第三方库的。
要想开启OpenSSL支持,系统需要安装libeay32.dll和ssleay32.dll两个库
如果你以前安装过OpenSSL,那么你的系统目录中应该已经存在这两个文件;如果没有安装,PHP的windows发行包里同样附带了这两个文件,将其复制到%system%/system32目录下即可。
总结,windows主机如果碰到了类似 ERROR: Failed to connect to server: Unable to find the socket transport “ssl” – did you forget to enable it when you configured PHP? 这样的问题,不能只是修改php.ini了事,还要检查下libeay32.dll和ssleay32.dll两个库有没有正确安装。
BTW:但是新版本(0.8.2)的WP Mail SMTP和WP Thread Comment有冲突,请按照一下方法修改即可解决问题。
将../wp-content/plugins/wp-mail-smtp/wp_mail_smtp.php中第391-393行的以下代码注释掉或者删掉就可以了:
if ( $orig != $default_from ) { return $orig;}由于polaris租用别人的主机,让人检查libeay32.dll和ssleay32.dll库之类的有点麻烦,而且不一定能够很好的帮您解决,所以,polaris不曾测试柳絮轻飞的方法。不过polaris发现了一个更简单而且很有用的方法,不过不知道有没有缺点哦,您如知道请留言告之。
上面提到在配置Encryption时是个关键。网上很多人都说应该选择第二项:采用SSL方式。然而,polaris在选中该项后,换用各种邮箱都是失败,都有这种提示:ERROR: Failed to connect to server: Unable to find the socket transport “ssl” – did you forget to enable it when you configured PHP?这因为这个,polaris才找到了柳絮轻飞的解决方法。然而没有试验,而是另寻了一个方法。
这个方法呢,很简单,就是选中第一项:No encryption(无加密),一测试,成功了。真真高兴,折腾了半天终于成功了。没有写过WordPress相关的文章,解决了这个问题,欣喜之余便迫不及待地拿出来与大家分享,希望对您有用。
在windows下面还有比小乌龟更好用的图形化svn客户端吗?相信答案会极度统一:没有。subclipse再好用,也必须在eclipse里才行。
因此这是个必须解决的问题,google和百度了一番,没有符合我的情况。
于是大概分析了一下,加上之前还有不断的crash report不成功,于是选择了重新安装小乌龟时,取消 additional icon sets 和 crash report 选项,安装,搞定。
估计是兼容性的问题了,哎。
]]>首先感谢“丸子”提供的这个IE8的css hack;
关注过IE8的css hack的人相信大家都在使用这个hack,就是“9”的css hack:
<% codeblock lang:css %>
.test{
color:#000000; /* FF,OP支持 /
color:#0000FF9; / 所有IE浏览器(ie6+)支持 ;但是IE8不能识别“*”和“_”的css hack;所以我们可以这样写hack /
[color:#000000;color:#00FF00; / SF,CH支持 */
color:#FFFF00; / IE7支持 /
_color:#FF0000; / IE6支持 */
}
<% endcodeblock %>
包括我自己也是使用这种的,这是我前段时间整理的《主流浏览器的一些CSS hack》。
很多人再研究color:#0000FF9;中的为什么IE6-IE8支持“9”写法,和它的原理,我只是个工程师,不是科学家,我不懂为什么和它的真正原理,真的!很惭愧!
昨天在某个群里也看到部分前端工程师或网页重构师势利的一面,同样的一个解决方案,大公司有名的前端工程师或网页重构师写的东西都追捧,而小公司没名气的前端工程师或网页重构师写的解决方案却被反问:“css有这种写法吗?看来你连最基本的css的几个属性和属性值都没搞懂;就算你解决了问题你写的css也是不规范的,就是规范你跟我讲讲你解决方案的原理;”同样的一个解决方案,大公司有名的前端工程师或网页重构师写的这些反问质疑就全都没了,拼命的去研究他这个解决方案,呵呵,我觉得那些人很可笑。还有很多人问问题只有得到大公司有名的前端工程师或网页重构师的肯定回答后才放心而又开心的走了,甚至不留一句谢谢。当然没人(包括我)否认大公司有名的前端工程师或网页重构师在业界的影响力,他们为前端和重构业界做的贡献大家都是看得到的,只是觉得做人(特别是我们做技术的)不能太势利,多一点技术共享和探讨,多一点感激,学习成长才是最重要的。我承认我以前经常骂人,骂人家SB,内参国王说的对,骂人家SB就等于骂自己SB,我以前是很SB。不想探讨就看着呗,骂人是不对的!
扯远了,回到IE8的CSS hack,讲讲color:#0000FF9:
color:#0000FF9的hack支持IE6-IE8(其他版本没有测试),但是IE8不能识别“*”和“_”的css hack,所以我们可以使用
1 | color:#0000FF9; ;/*ie6,ie7,ie8*/ |
来区分IE的各个版本。
至于为什么使用“9”我真的不清楚原因,但是“丸子”测试了其他0-13的数字,最终结果如下:

其中:OP表示Opera,SA表示Safari,Ch表示Chrome;当然你如果还有耐心可以测试“14”,“15”,“16”。。。
从上面测试结果我们可以看出“\0”的写法只被IE8识别,ie6,ie7都不能识别,那么“\0”应该是IE8的真正hack。主流浏览器的CSS hack这样更好一些:
.test{ color:#000000; /* FF,OP支持 */ color:#0000FF\0; /* IE8支持*/ [color:#000000;color:#00FF00; /* SF,CH支持 */ *color:#FFFF00; /* IE7支持 */ _color:#FF0000; /* IE6支持 */ }其中:OP表示Opera,SA表示Safari,Ch表示Chrome;
]]>首先,要嵌入流媒体很简单,主要有以下2种方式:
1.** 标签型(严重推荐)**:
1 | <embed width=240 height=140 transparentatstart=true animationatstart=false autostart=true autosize=false volume=100 displaysize=0 showdisplay=true showstatusbar=true showcontrols=true showaudiocontrols=true showtracker=true showpositioncontrols=true balance=true src="[流媒体地址]"> |
当然,还有简化版的:
1 | <embed src="[流媒体地址]" style="height: 140px; width: 240px" type=audio/mpeg AUTOSTART="1" loop="0"> |
2. 综合型:
1 | <object classid=clsid:22D6F312-B0F6-11D0-94AB-0080C74C7E95 codebase="http://activex.microsoft.com/activex/controls/mplayer |
其次,非常重要的一个环节,就是停止播放和切换流媒体地址。也相当简单粗暴。
尝试过直接用js操作替换src内容,发现并不会发生变化。于是采用了移除原有的embed标签,新建一个包含新地址的embed在原来的div中,完美解决。
唯一不放心的是,不知道被移除标签中嵌入的流媒体在后台会不会继续。反正有人告诉我不会……
最后,是切换一页显示多少个视频,也就是布局问题。这个乍看好像有点麻烦,其实也再简单不过了。
先定义好最多有几个,并且给每个流媒体的div标签id赋值。然后按切换需要,隐藏div,并重新给div赋值进行布局(不要删除div,否则还原回多个摄像头画面时,原有的视频会消失,同时会影响布局时的操控,更复杂)。
没图说个XX,好吧,上代码……
1 |
|
不少国人的项目确实是要么没文档,要么文档不全,或者老死不更新。dwz的情况不比他们好多少,不过至少使用者还是很多的,基本用法的资料还是比较好查。
这次就碰到了表单提交响应的问题,对于客户端要传递什么内容,服务器要传回什么内容,demo和手册里实在没找到。上网上看了一下,大致有这个几个方面需要注意。
1. Form标签上增加onsubmit=”return validateCallback(*this, [navTabAjaxDone/dialogAjaxDone]*)”
1 | { |
而在原始代码中其实有相关的注释:
form提交后返回json数据结构statusCode=DWZ.statusCode.ok表示操作成功, 做页面跳转等操作. statusCode=DWZ.statusCode.error表示操作失败, 提示错误原因.
statusCode=DWZ.statusCode.timeout表示session超时,下次点击时跳转到DWZ.loginUrl
{“statusCode”:”200”, “message”:”操作成功”, “navTabId”:”navNewsLi”, “forwardUrl”:””, “callbackType”:”closeCurrent”}
{“statusCode”:”300”, “message”:”操作失败”}
{“statusCode”:”301”, “message”:”会话超时”}
callbackType设置为空,则可以只刷新当前页面,而不是关闭
顶部弹出的对话框不影响操作,过段时间会自动消失,但缺点是展示的时间过长,太容易吸引人去点它,影响体验。暂时还没找到在哪里修改。
不过现在看还是蛮喜欢的。
记得当时是沉迷于攻壳机动队TV版SAC,觉得塔其克玛的构造还是挺合理的,感觉的确比人型容易实现多了。

2.微信机器人框架 - WeRoBot
https://github.com/whtsky/WeRoBot
3.在SAE上搭建微信公众平台账号消息服务器
http://www.cnblogs.com/gzb1985/archive/2012/12/30/weixin-msg-server-based-on-sae-python.html
4.小蜗牛有道翻译小助手
http://blog.csdn.net/liushuaikobe/article/details/8453716
5.微信公众平台消息接口指南
http://mp.weixin.qq.com/wiki/index.php?title=%E6%B6%88%E6%81%AF%E6%8E%A5%E5%8F%A3%E6%8C%87%E5%8D%97
]]>
最近公司这边也一直很忙,以至于耽搁了装甲纵队的发布进度(毕竟这次的开发主要是Fenix同学,所以基本没耽搁开发进度)。公司的游戏也在紧张测试中,估计近两个月能上线。祝我们的游戏都能大卖啊!各位看官捧个场吧!
记得关注《装甲纵队》~
]]>在Windows 7中,我们可以通过网络与共享中心的“设置新的连接和网络”来创建一个无线热点,供手机或其他设备进行网络连接。但是,在Windows 8下,这个功能却找不到了。不过,我们依旧可以通过命令提示符来开启该功能。
在Win8系统屏幕的左下角单击右键唤出神秘菜单(快捷键Win + X ),选择“命令提示符(管理员)”。
首先查看设备是否支持创建ad-hoc。在命令提示符中输入netsh wlan show drivers,在结果中查看“支持的承载网络”,“是”才可创建热点。

▲支持的承载网络
接下来就可以创建无线热点了。
在命令提示符中输入netsh wlan set hostednetwork mode=allow ssid=jht2013 key=password。其中“ssid=”后面的为无线网络名称,“key=”后面的为无线网络密码,以上均可定义,但是密码至少需要8位。

▲设置用户名和密码
接下来,继续通过命令netsh wlan start hostednetwork开启无线热点。并可以在网络连接设备中找到如下虚拟网卡适配器。(名字自行更改)
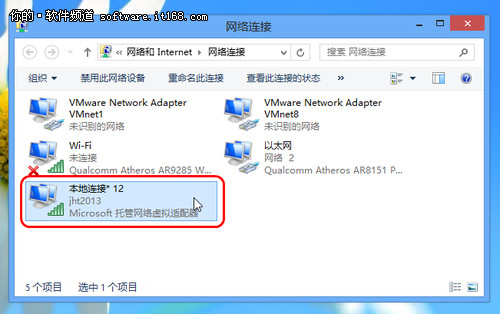
▲创建的连接
在本机正在连接的网络上将Internet连接共享。
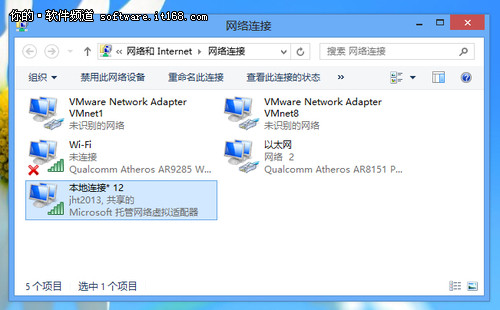
▲已经共享
此时,手机或其他设备已经可以通过该无线热点进行连接。
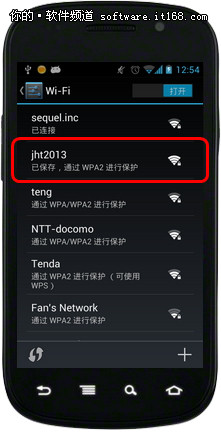
▲手机端的共享连接
若需要关闭无线热点可输入netsh wlan stop hostednetwork即可。
将CS6的通用破解覆盖补丁amtlib.framework,覆盖到程序目录:/Applications/Adobe Flash Builder 4.7/eclipse/plugins/com.adobe.flexide.amt_4.7.0.349722/os/macosx/Frameworks
没有cs6 amtlib.framework for mac吗,在这里可以下载:
]]>建议电脑要求
Windows 7, 32 / 64 bit
CPU Intel Core i5 / i7
内存 4GB 以上
硬盘 500GB 以上
由于虚拟机不支持 Apple Quartz Extreme/Core Image, 需要 Quartz Extreme 的应用软件例如 iBooks Author,Pages,Pixelmator,SketchBook 等不能在虚拟机下使用 。
安装步骤
⑴ 迅雷下载: http://kuai.xunlei.com/d/LMGYDWMVJWYI
VirtualBox-4.1.20-80170-Win.exe
Oracle_VM_VirtualBox_Extension_Pack-4.1.20-80170.vbox-extpack
HackBoot1.iso
HackBoot2.iso
OS X 10.8 Install DVD.iso
⑵ 双击安装 VirtualBox-4.1.20-80170-Win.exe 及 Oracle_VM_VirtualBox_Extension_Pack-4.1.20-80170.vbox-extpack
⑶.1 在 VirtualBOX 新建虚拟电脑
名称 Mac OS X 10.8
操作系统 : Mac OS X
版本 : Mac OS X Server (64 bit)
⑶.2 内存分配最好 2048 MB 以上
⑶.3 创建新的虚拟硬盘
⑶.4 选择 VDI (VirtualBox Disk Image)
⑶.5 选择 Dynamically allocated
⑶.6 设置虚拟硬盘位置及大小, 建议大小为 20 GB 至 (最好) 40 GB
⑷.1 打开 VirtualBOX 设置虚拟机,系统 -> 主板, 去掉 “软驱”,取消勾选 “启用 EFI”
⑷.2 系统 -> 处理器, 选择双核 CPU数量= 2
⑷.3 显示 -> 显卡 -> 显存大小设置到最大 128 MB
⑸.1 在 Storage -> IDE Controller 属性 CD / DVD Drive 右边的光盘图标 Choose a virtual CD/DVD disk file 选择 HackBoot1.iso 文件
⑸.2 在 HackBoot1.iso 的启动引导下, 如下 HackBoot 页面出现后
在虚拟机底右下状态位置-> 光盘图标 Choose a virtual CD/DVD disk file 选择 OS X 10.8 Install DVD.iso 文件,按键 F5 刷新后,回车开始安装系统
⑸.3 安装系统开始时,提示找不到任何有效的硬盘 , 使用菜单 Utilities -> Disk Utility 格式化虚拟硬盘, 左边点击硬盘, 选择 Erase, Name 录入 “Macintosh HD”, 然后点击 Erase
⑸.4 安装系统成功后, 关闭 Mac OS X 10.8 虚拟机, 在 Storage -> IDE Controller 属性 CD / DVD Drive 右边的光盘图标 Choose a virtual CD/DVD disk file 选择 HackBoot2.iso 文件
⑸.5 在 HackBoot2.iso 的启动引导下, 如下 HackBoot 页面出现后 , 使用右键选择启动 Macintosh HD
⑸.6 启动 Mac OS X 10.8 虚拟机文件后的 Mac OS X 设置
如需要更改语言 (左上角的 苹果菜单 -> 系统偏好设置(System Preferences) -> Language & Text), 重启后才更新
如需要更改时区 (左上角的 苹果菜单 -> 系统偏好设置(System Preferences) -> Date & Time)
⑸.7 在 苹果菜单 -> 系统偏好设置(System Preferences) -> “安全性与私隐” 里面选择 “任何来源” (用于安装 MultiBeast)
⑸.8 使用 Mac OS X 10.8 的 Safari, 下载及解压 MultiBeast-4.6.1.zip (用于解决虚拟机的声音问题)
迅雷下载 : http://kuai.xunlei.com/d/LDAYOTMGKBOO
⑸.9 解压后的文件夹内, 双击安装 MultiBeast 4.6.1.pkg, 安装时勾选如下 4项
UserDSDT Install
System Utilities -> Repair Permissions
AppleHDA Rollback
NullCPUPowerManagement

⑸.10 Finder 菜单,前往 -> 前往文件夹 /System/Library/Extensions/

删除 AppleGraphicsControl.kext 文件
⑸.11 Finder 菜单,前往 -> 前往文件夹 /Extra/ 
修改 org.Chameleon.boot.plist , 增加分辨率内容如下
<key>Graphics Mode</key>
<string>1440x768x32</string>

也可以选择以下分辨率
1152x720x32
1366x768x32
1440x900x32
⑸.12 关闭 Mac OS X 10.8 虚拟机, 在 Storage -> IDE Controller 属性 CD / DVD Drive 右边的光盘图标
选择 Remove disk from virtual drive 去退出 HackBoot2.iso 文件
⑸.13 在 Windows 下 cmd 执行
请根据 ⑶.1 虚拟电脑的名称 及 ⑸.11 选择的分辨率,执行
cd "C:Program FilesOracleVirtualBox"
VBoxManage setextradata "Mac OS X 10.8" "CustomVideoMode1" "1440x768x32"

⑸.14 启动虚拟电脑, 会直接启动 Mac OS X 10.8 虚拟硬盘, 以后并不需要Hackboot 光盘文件的引导
重新启动虚拟电脑后, 可选择在 苹果菜单 -> 软件更新
可选择更新 OS X Mountain Lion 10.8.2 http://support.apple.com/kb/DL1580?viewlocale=zh_CN
及 10.8.2 Supplemental Update http://support.apple.com/kb/DL1600?viewlocale=zh_CN
系统更新 10.8.2 后要重覆步骤 ⑸.9 至 ⑸.11 及关闭 Mac OS X 10.8 虚拟机后重新启动。
]]>1 | import com.greensock.TweenLite; |
1 | var inputPath = \"file:///E|/work/war_test/bin-debug/fla/fight/\"; |
EnterFrame会带来不少负担。最近公司的项目有不少小东西要处理,于是也稍微介入了一些程序的工作,发现其中用到了不少addFrameScript。看起来似乎很好用,于是到网上搜索了一下,大概整理出了以下资料。
1.基本用法
1 | mc.addFrameScript(frameIndex,function); |
2.需要一次过在多个帧上面添加不同的帧标记的时候,可以这样使用:
1 | mc.addFrameScript(1,fun1,5,fun2,10,fun3); |
3.frameIndex是从0开始的,而不是像gotoAndStop()函数是从1开始的,这里需要将实际的帧减1才是正确的。如果对同一帧重复添加帧代码,新的帧代码会自动替换旧的。addFrameScript(frameIndex, null)的方法可以清除frameIndex帧的代码。特别需要注意的是,一旦这个MC开始了播放,再次调用addFrameScript就会无效的了,所以需要在构造函数中就定义好。
目前已经把自己的用到代码中可以替换的都换掉了,但是网上也有人说不推荐使用这个方法,因为addFrameScript是flash的隐藏方法,与EnterFrame在底层实现机制是一样的。比较耸人听闻的还有,它有可能造成内存泄漏。先用着看吧。
结果安装时悲剧的弹出提示:Blizzard啟動程式:無法從[ http://zhCN.patch.battle.net:1119/patch ]取得安裝資料URL,請檢查你的網絡連接.

神马?是zhCN?
答案很明了,应该是安装魔兽世界的时候,被国服客户端写定下载地址了。
问了下度娘,删除C盘隐藏文件夹Program data里面 Battle.net和Blizzard Entertainment两个文件夹, 然后再重新安装就行了。
看2个小孩儿玩了一会,我和阿宝也去玩了一把。大致还是挺精准的,而且,非常累人……比wii锻炼多了……

阿宝说这个可以吸引到那些曾经幻想通过影子隔空取物、和羡慕科幻电影里面直接在空气中就能操纵电脑的人。嗯,想想还真有可能。百科在此:http://baike.baidu.com/view/3766855.htm 。
等着有钱了,回头自家也弄个玩。看了下网上的介绍,大概800大洋出头,但是还得有xb360先……
]]>1 | private function convertToGrayscale(image:DisplayObject):void |
这次在使用颜色滤镜 fl.motion.ColorMatrix 的时候,又遇到了问题。原来是因为FlashDevelop的AS3项目默认没有导入fl包,于是将FlashIDE 项目中的fl包拷贝到AS3项目中(复制FlashDevelopLibraryAS3frameworksFlashIDE下面的FL包到FlashDevelopLibraryAS3intrinsicFP10),这下就愉快的开始使用了。
但是!居然编译时报错了!告诉我找不到这个类!
原来这样操作以后,只是用来补全代码的吗?为这么一个小问题就把项目迁移到FB去完成,那太不值了!于是,我开始了搜索历程。
1.首先找到了一个很惊喜的东西,一个老外在做他的FDT项目时,也因为没有fl包,所以把这个包导出成了swc(猛击这里下载:http://apdevblog.com/wp-content/uploads/2008/02/fl_package.swc),当然,还有更猛的,连控件皮肤的资源都带上了(猛击这里下载:http://code.google.com/p/asform/downloads/list)。
测试效果如何呢?也许这可以满足一部分人的需求,但是我并不在内。因为这里面并没有把 fl.motion.ColorMatrix 打包进去。所以历程继续。
2.有人提到可以把fl包加入全局类路径( tools>Global Classpaths ),这个方法看上去就很可行。于是我按教程找到了 ..Adobe Flash CS5.5zh_cnConfigurationActionScript 3.0Classes,完成,编译……靠!还是失败?这是为毛?我循着路径到目录中,只看到了一个孤零零的mxml文件。虽然没有一下子找到,不过这种事情搜索一下就解决了。对于CS5.5,正确的路径应该是 ..Adobe Flash CS5.5CommonConfigurationActionScript 3.0projectsFlashsrc 。
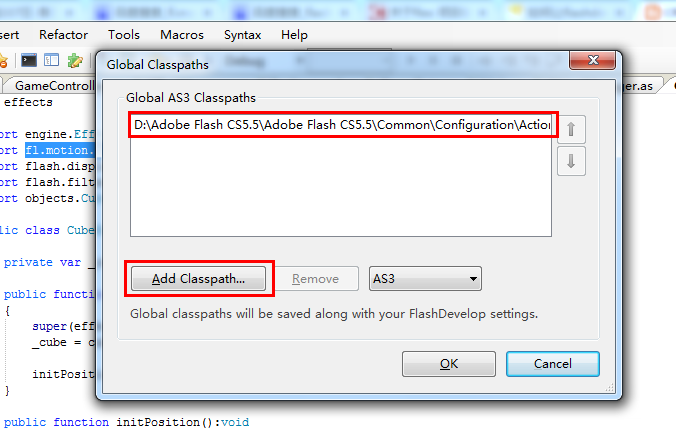
Shift+F8清理,F5编译完美通过,菜鸟工程继续!
]]>转自:http://blog.163.com/mdzhg@126/blog/static/1633215682010423113048711/
包 flash.filters
类 public final class ColorMatrixFilter
继承 ColorMatrixFilter BitmapFilter Object
使 用 ColorMatrixFilter 类可以将 4 x 5 矩阵转换应用于输入图像上的每个像素的 RGBA 颜色和 Alpha 值,以生成具有一组新的 RGBA 颜色和 Alpha 值的结果。 该类允许饱和度更改、色相旋转、亮度为 Alpha 以及各种其它效果。 您可以将滤镜应用于任何显示对象(即,从 DisplayObject 类继承的对象),例如 MovieClip、SimpleButton、TextField 和 Video 对象,以及 BitmapData 对象。
注意:对于 RGBA 值,最高有效字节代表红色通道值,其后的有效字节分别代表绿色、蓝色和 Alpha 通道值。
一、构造方法:
ColorMatrixFilter(matrix:Array = null);
二、matrix属性详解:
注意;这里的matrix并不是Matrix的实例,其实是一个Array;
matrix:Array [read-write]
由 20 个项目组成的数组,适用于 4 x 5 颜色转换。 matrix 属性不能通过直接修改它的值来更改(例如 myFilter.matrix[2] = 1;)。 相反,必须先获取对数组的引用,对引用进行更改,然后重置该值。
颜 色矩阵滤镜将每个源像素分离成它的红色、绿色、蓝色和 Alpha 成分,分别以 srcR、srcG、srcB 和 srcA 表示。 若要计算四个通道中每个通道的结果,可将图像中每个像素的值乘以转换矩阵中的值。 (可选)可以将偏移量(介于 -255 至 255 之间)添加到每个结果(矩阵的每行中的第五项)中。 滤镜将各颜色成分重新组合为单一像素,并写出结果。 在下列公式中,a[0] 到 a[19] 对应于由 20 个项目组成的数组中的条目 0 至 19,该数组已传递到 matrix 属性:
redResult = (a[0] * srcR) + (a[1] * srcG) + (a[2] * srcB) + (a[3] * srcA) + a[4]
greenResult = (a[5] * srcR) + (a[6] * srcG) + (a[7] * srcB) + (a[8] * srcA) + a[9]
blueResult = (a[10] * srcR) + (a[11] * srcG) + (a[12] * srcB) + (a[13] * srcA) + a[14]
alphaResult = (a[15] * srcR) + (a[16] * srcG) + (a[17] * srcB) + (a[18] * srcA) + a[19]
对于数组中的每个颜色值,值 1 等于正发送到输出的通道的 100%,同时保留颜色通道的值。
计算是对非相乘的颜色值执行的。 如果输入图形由预先相乘的颜色值组成,这些值会自动转换为非相乘的颜色值以执行此操作。
可使用两种经过优化的模式:
三、理解、体会;
matrix是一个长度为4*5=20的数组,其构成如下所示:
1 | var matrix:Array = new Array(); |
上面是matrix的初始状态。
下面我分先来分析一下其初始状态。
red通道的值:(1,0,0,0,0)表示,R通道的乘数是1(完全保留),别的道道的的乘数是0,(不加入别的通道的颜色),色彩偏移量off是0;
。。。
别的通道依次类推。
下面来做一些效果,增加对colorMatrixFilter的认识;
1、调整亮度:
亮度(N取值为-255到255)
1,0,0,0,N
0,1,0,0,N
0,0,1,0,N
0,0,0,1,0
我们只需要设置一下RGB的色彩偏移就能调节其亮度,是不是很简单呢。
2、颜色反向
-1,0,0,0,255
0,-1,0,0,255
0,0,-1,0,255
0,0,0,1,0
先解释一下颜色反向:就是把0变为255,255变为0,1变为254,254变为1…..
因此,我们只需把RGB通道的原通道乘数设为-1,然后再把色彩偏移量设为255就行了。
3、图像去色:
0.3086, 0.6094, 0.0820, 0, 0
0.3086, 0.6094, 0.0820, 0, 0
0.3086, 0.6094, 0.0820, 0, 0
0 , 0 , 0 , 1, 0
1)、首先了解一下去色原理:只要把RGB三通道的色彩信息设置成一样;即:R=G=B,那么图像就变成了灰色,并且,为了保证图像亮度不变,同一个通道中的R+G+B=1:如:0.3086+0.6094+0.0820=1;
2)、三个数字的由来:0.3086, 0.6094, 0.0820;
按理说应该把RGB平分,都是0.3333333。三个数字应该是根据色彩光波频率及色彩心理学计算出来的(本人是这么认为,当然也查询了一些资料,目前尚未找到准确答案。
在作用于人眼的光线中,彩色光要明显强于无色光。对一个图像按RGB平分理论给图像去色的话,人眼就会明显感觉到图像变暗了(当然可能有心理上的原因,也有光波的科学依据)另外,在彩色图像中能识别的一下细节也可能会丢失。我假想:可能绿色的一些东西会丢失。
下面是我从PS中对RGB都为255的明度对比图:

同样的RGB,给人的感觉是绿色最亮,红色次之,蓝色最暗。它们的比例大概是3:6:1,即:0.3086, 0.6094, 0.0820
所以,在给图像去色时我们保留了大量的G通道信息,使得图像不至于变暗或者绿色信息不至于丢失(我猜想)。
4、色彩饱和度
N取值为0到2,当然也可以更高。
0.3086*(1-N) + N, 0.6094*(1-N) , 0.0820*(1-N) , 0, 0,
0.3086*(1-N) , 0.6094*(1-N) + N, 0.0820*(1-N) , 0, 0,
0.3086*(1-N) , 0.6094*(1-N) , 0.0820*(1-N) + N 0, 0,
0 , 0 , 0 , 1, 0
分析:
1、当色彩饱和度低到一定成度的时候,就想当于给图像去色,所以跟第3条:图像去色,有着千丝万缕的联系,在此不想过多解释;
2、N为原有通道信息保留量;可以理解为百分之几,等于0时完全去色,小于1时降低色度,大于1时增加色度,等于2时色度翻一倍,等于3时……。注意:RGB的原有通道信息保留量都应该相等,不然会产生偏色。
3、为什么是这样的计算公式:
N是原通道色彩保留量:所以,在原通道中,我们都+ N,这是不能被别的通道瓜分的。剩余的就是(1-N),就让RGB按0.3086, 0.6094, 0.0820的比例还瓜分这个剩余量吧。
** 5、对比度**
N取值为0到10
N,0,0,0,128_(1-N)
0,N,0,0,128_(1-N)
0,0,N,0,128*(1-N)
0,0,0,1,0
分析:
所 谓对比度就是让红的更红,绿的更绿……或反之。初一想,我们只需要修改RGB的乘数(要一至,不然偏色)。可仔细一琢磨,不对。如果只增加乘数,那么整个 图像就会被漂白,(或反之)。好,有办法了,设置色彩偏移量,offset。具体要偏移多少呢,我们找到了一个折中的方案:128(1-N);即:一幅图 像,不论很亮或很黑,但对比度为0了,最终得到的都是一幅中性灰度的图像(128),
6、阈值
所谓阈值,就是以一个色度值为基准对图像作非黑即白的处理(注意没有灰色),由于不去除了彩色属性,因此,也离不开0.3086, 0.6094, 0.0820这三组神奇的数字。
(N取值为0到255)
下面的256也可以改成255;(那样就能看到图一和图五的小黑点和小白点);
0.3086_256,0.6094_256,0.0820_256,0,-256_N
0.3086_256,0.6094_256,0.0820_256,0,-256_N
0.3086_256,0.6094_256,0.0820_256,0,-256_N
0, 0, 0, 1, 0
分析:
先不看最后面的色彩偏移:-256*N
前 面我们提及过,当RGB三个通道的色彩信息一模一样时,图像就失去了色彩(去色),从 0.3086_256,0.6094_256,0.0820_256,0,-256_N可以看出:图像已经去色了,并且,(*256)亮度已经翻了256 倍(当然也可以是255);我们知道,RGB的有效值是0-255,即:0,1,2……255,把这些值乘以255以后会出现什么情况呢?但是除了0之 外,别的全都大于或等于255了,所以此时的图像除了剩有几个黑点外,其它的全都变成白色了如图一(N=0);那么现在我们再作色彩偏移处理:把RGB都 减去255;上次值为255(白色)的现在又变成0(黑色了)超过255的仍然是白色,我们不断的反复减255,图2,图3,图4,图5,分别是 N=64,N=128,n=192,n=255时的图像:

7、色彩旋转
所 谓色彩旋转就是让某一个通道的色彩信息让另一个通道去显示;比如,R显示G的信息,G显示B的信息,B显示R的信息,也可以只拿出一部份信息让给别的通道 去显示,至于参数的瓜分可以平分。不必太讲究,但是,始终要坚持的一个原则就是每一个通道中的RGB信息量之和一定要为1,不然将会生偏色,如果您要制作 偏色效果又另当别论;请偿试下面的参数:
0,1,0,0,0
0,0,1,0,0
1,0,0,0,0
0,0,0,1,0
//—————
0,0,1,0,0
1,0,0,0,0
0,1,0,0,0
0,0,0,1,0
8、只显示某个通道;
1,0,0,0,0
0,0,0,0,0
0,0,0,0,0
0,0,0,1,0
//上面是只显示红色通道。依次类推。
]]>经过Fenix的辛勤劳作,《装甲纵队(Battle Array)》网络版的第一个版本终于问世了,小小宣传一下!至于我做了神马……当然是更新官网了!(http://www.dashgame.com)
传送门:http://www.3366.com/flash/80693.shtml
从Fenix那里又学到了很多AS技巧,比如在做移动版本的时候,如果是基于原版,那么很多方法可以用protected,让移动版本继承原版的方法。想到原来自己做的纯粹数独移动版是完全独立的一个项目,感觉好费劲。
这个新的博客主题是因为更新博客的时候上一版主题挂掉了……不过也好,不破不立嘛!现在是用的现成主题FLAT,感觉很清爽,不错。有空再自定义一下吧。
至于公司的游戏,也在稳步推进中。有很多很多很多很多问题,不过还是看得到曙光。
]]>最近的工作需要在VISIO2003中绘制仪表的界面效果图,拿到前辈们画的文件,发现都不是以像素为单位的。为了方便,想设置成以像素为单位,自己折腾一番,未果。还好GOOGLE没有让我失望,下面就是一个不错的解决办法:
来自:http://complexdiagrams.com/2008/06/01/pixel-rulers-in-visio/
Should you be required to work in Visio, you may well find yourself, as I did, wishing to measure your drawing in pixels. I couldn’t figure out how do do it, though Visio does support such diverse measurements as Ciceros and Didots.
I finally found the definitive answer from Microsoft: For some types of drawings, you may want to change the measurement units to pixels. However, a pixel isn’t a unit of measurement. A pixel is just a dot on a screen and the size of the dot varies for different screens. To simulate pixels, set the measurement units to points.
Needless to say, this is not satisfying. It’s true a pixel is only an on-screen measure, and is clearly only useful for a few, obscure situations, such as when creating interface mockups, wireframes, or prototypes for software, the web, or any other sort of images meant to be viewed on a screen.
Luckily, Visio provides a set of features that allow a fairly simple, two step work-around. Warning: doing this on existing Visio documents may severely distort your existing drawings. I suggest working on duplicate files, not originals.
Step One Open the File > Page Setup menu and select the Page Properties tab. In the Measurement units field select Picas.
Step Two In the same dialog box, select the Drawing Scale tab. Select the Custom Scale radio button and set the ratio to 1 p = 16 p.
That’s it. Click OK and you’re all set to go.
Why it works Picas are 6 to the inch. By setting the ratio at 1:16, Visio presents a diagram at 96 picas per inch, the same as the Windows standard of 96 pixels per inch. You could set an appropriate ratio with any of the available units, but it works well with picas, and I find it useful that all units are labeled as p.
Here is a Visio file template with the units set properly.
连Ciceros and Didots这样奇怪单位都有的VISIO2003居然不能方便的以像素,诶。。。
]]>这个教程的原文在Abduzeedo官网上《Simple Underwater Scene in Photoshop》:http://abduzeedo.com/simple-underwater-scene-photoshop,我就不一一翻译了,用google的网页翻译已经足以看懂。
我做出来的效果是这样的:

大致总结了一下,有以下一些要点。尤其是教程中没有提到的,或者容易被遗漏的:
1、在第3步修改绿色的遮罩的时候,一定要注意周围边缘,透明度要压低,可以降低第4步时进行修饰的繁琐程度。
2、第6步的深蓝色需要好好修饰,尽量过度自然。不用拘泥于教程的方式。
3、第9步的泡泡千万记得要对画笔进行设置,不是简单的点上去就有很好的效果,起码【形状动态】和【散布】这两个选项是一定要调整的,因为需要不同的大小、密度和旋转角度。即便是设置了,也尽量多进行尝试,做设计得有耐心。
4、第11步中,一定记得,【斜面和浮雕】中的高光模式和投影模式应该设置成一样的,都得用白色,才有晶莹剔透的感觉。另外,根据自己字体的不同,尤其是大小和笔画宽度,应当自己调节一下,保证笔画中间可以透出背景颜色,边缘也有玻璃感觉。
5、第15步中,调整色阶的时候,要把黑白对比度拉开,才能看到水纹的效果,否则你将看到一片浮云。
6、第18步用到的素材还可以用在顶部,以还原原图效果。
PSD文件可以在这里下载:http://imgs.abduzeedo.com/files/tutorials/Simple_Underwater_Scene_in_Photoshop/Sample.psd.zip。出于空间容量的原因,我就不贴自己的PSD了……
]]>不过首先有件值得庆贺的事情,昨天终于处理好所有问题,疾风(http://www.dashgame.com)的新游戏《Battle Array》(中文名《装甲纵队》)终于正式上线了。因为一些问题,只发布了麻球和3366平台,贴个地址吧。这是Fenix的独立游戏,我只负责web版本的发布、平台接入和运营工作。以后还会不断更新,另外还有iOS版本,敬请期待 :)
版本发布并不算顺利,因为代码结构与之前不一样,在接入两个平台的时候都发生了意想不到的情况,折腾了2天。这是让我比较心烦的。
另外一个麻烦是关于网站设计,JS还是太不熟,操作网页元件出了各种问题,很是麻烦,至今未解决。
生活当中还有点小麻烦……不过跟前两个比起来都还好了。
还是告诉自己,总会好的 :)
整理一下,贴在这里吧。应该都是2008年左右的东西了。
·首先是可能第一次厚涂最成功的了,战锤40k里的Necron族代表。

·接着是国漫风自画像….

·再来是自己原来给自己设计的漫画形象

·613室长同学08年生日的时候给她涂的,涂得很随便……

·王国之心凯莉的涂鸦练习

·根据61式战车II型画的,当年似乎很流行娘化军械…

·曾经应邀设计的一台机体….完成稿要更好看一些……可惜已经没了
·在宏信做星球计划,还梦想着做原画的时代,给游戏设计的机体。受铁骑影响过重了。只是加了个变形。


应该是在趣游的时候,某天中午休息时,在渔场的涂鸦板鼠绘的。挺烂,哈哈,帽子像钢板做的。

今天实在忍无可忍,在易讯上看好了一个U盘,加入购物车,下决心在半个小时内无法解决就再买一个。
于是乎在百度文库搜到一篇通过量产修复的详文,找到了对应的量产程序,居然就修复了。果然,对自己要狠一点才行。
分享一下经验吧。
1.太平洋网上下了一个chipgenius-v4 b23工具(http://dl.pconline.com.cn/html_2/1/60/id=50720&pn=0&linkPage=1.html),找到U盘的主控芯片信息如下:
设备描述: [K:]USB 大容量存储设备(USB FLASH DRIVE)
设备类型: 大容量存储设备
协议版本: USB 2.00
当前速度: 高速(HighSpeed)
电力消耗: 200mA
USB设备ID: VID = 1005 PID = B113
设备序列号: 198A16521C6C
设备名称: USB FLASH DRIVE
设备修订版: 0110
产品型号: USB FLASH DRIVE
产品修订版: PMAP
芯片厂商: Phison(群联)
芯片型号: PS2251-32(PS2232) - F/W 01.05.10 [2008-01-26]
闪存识别码:2CD5943E - Micron(美光) [MLC-4K]
2.根据芯片的型号 PS2251-32(PS2232) 下载量产工具进行低格。我在优盘之家(http://www.upan.cc)上下的这个:群联低格工具 Formatter 2.9.0.6(PS2232,PS2251-32)(http://www.upan.cc/tools/repair/2011/Formatter_2.9.0.6_PS2232.html)。保证U盘插好,双击Formatter2.9.0.6(PS2232).exe,确定。不到30秒,格式化完毕。重新检测,一切如初。
]]>PS的矢量图形上,功力还是不足,不过美术方面本来也没打算朝这方面发展。Flash矢量和像素图才是我工具上的方向。
Fenix已经出了新游戏的Demo版了,感觉还不错,他的美术功底也越来越了得了。只是由于种种限制,不得不取消了很多之前的设计,可能玩法上会显得有点落俗了。但是总体感觉还是不错的。截图预告一个,哈哈。
图片托管站木有啦~
]]>
加了一些jQuery控制缓动效果,毕竟是初学者,代码写得很啰嗦,不过效果应该还算凑合。
IE6和IE8的效果没有专门调试,有点问题。不过现在都神马时代了,还在用IE6的童鞋们还是醒醒吧!
Fenix正在奋笔疾书新游戏中,8月20日,监督!
]]>传送门:http://www.3366.com/flash/90949.shtml
游戏是受到一个html5小游戏的启发。移动鼠标来控制自己的UFO,躲开敌人的UFO,吃掉能量方块。小创新是,吃掉能量方块到一定分数,可以激活子弹时间,减缓敌人移动速度5秒。吃掉普通蓝色方块得10分,吃掉带D字的绿色方块得20分。
做这个游戏还是又学习了一些新东西。之前一直没做过像素级碰撞检测,刚开始边学边摸索的自己写了个类,结果超过15个敌人就开始卡了。下载了别人写好的一个高效像素级碰撞检测类,发现用起来效率相当不错,1000HE小本上都是40个敌人才开始卡。内存控制方面还不熟悉,很多实现的思路都没太考虑到实际运行情况。不废话了,分享这个类。
1 | package |

特别兴奋,筹备了3年的计划终于要开始了,疾风游戏要开始正式运转了!就是现在,拼这一回,永远都不后悔。
想赢,不怕输。
]]>改版自WeisaySimple的Pure主题还有很多不完善的地方,尤其是IE8以下的兼容性问题。虽然各种事情很多,但是也在抽时间尝试修复,希望能有更好的东西展现在大家面前。
游戏进度很尴尬的暂停了,由于一些毫不相干的原因。挺可笑的,完全是我自己没有规划好一切,没准备备用方案。
帝都就是帝都,大家都在这里忙着实现自己的梦想,目标更加明确,行为更加纯粹。而这些天发现,雾都终究不是帝都,充满了抱怨、妒忌、懒散,曾经觉得全世界只有这里最美好、最天堂,现在变成了磨练意志和考验综合能力的地方。更深入的了解一切,更巧妙的应对一切,更熟练的掌握一切,我还有很多要学习的。
并不知道现在的这些行为和决定对以后有多少实际的用处,但是在自己目前的世界观和价值观体系下,我试着努力走向自己的目标。成败已经不重要,坚持变得更加关键。希望自己能够更加成熟。
]]>前两天为了修复疾风博客中的两个bug,由于jQuery特效都不是原创的,所以看了一下jQuery。把bug fix掉了,也顺道学了些效果。尝试了一下,之前不知道为什么js都没添加成功,但是这次没问题了,大致记录下。(碰到没有引入jQuery库的,在单独使用时要自行引入)
#1.回到顶部 转到底部
老生常谈的东西了,记下几个关键点:
1.css中 #回到顶部ID{position:fixed} 不能少,否则位置无法固定;
2.jQuery中要直接实现转到底部,只要 $(’html,body’) 来获取页面高度就可以了。如果是要转到某一个对象,那就替换成该对象ID或类名,也可以很方便的实现。
那么贴上我自己的jQuery部分的代码吧
1 | jQuery(document).ready(function($){ |
另外也贴上一个个人觉得很不错的代码,带 FadeIn 和 FadeOut 效果。(原文地址:http://my.oss.org.cn/space.php?uid=5499&do=blog&id=87655 )
CSS部分:
1 | #back-top { |
jQuery部分:
1 | <script type="text/javascript" src="http://ajax.googleapis.com/ajax/libs/jquery/1.4.3/jquery.min.js"></script> |
HTML部分:
1 | <p id="back-top"> |
#2.图片渐隐 图片渐现
几个要点:
1.图片显示的方式,是在css中使用background而不是直接在html中使用<img />,否则难以实现图片替换;
2.<span class=\”hover\”></span>要嵌入在<a></a>标签中;
3.用jQuery来控制span.hover的透明度。
CSS部分:
1 | #header .nav .sns{ |
jQuery部分:
1 | <script type="text/javascript"> |
HTML部分:
1 | <div class="sns"> |
3.FancyBox
插件类的就再简单不过了,直接参照使用说明,有2个要注意的小点:
1.在初始化的时候最好使用一个单独的类来区别使用fancybox效果的图片,例如,$(\’.fancybox\’).fancybox(),以免出现一些不可预见的问题;
2.我是直接引用官方的jQuery文件,有时加载速度会比较慢,有条件还是放在本地比较好,也能保证稳定性。
jQuery部分:
1 | <!-- Add fancyBox --> |
HTML部分:
1 | <img class="fancybox" img="yourimg" /> |
也好,正好网页设计班没有报wordpress部分,用了weisay的simple模板为底稿,还原了当初为blogbus做的一套风格。这次比原来节省了很多时间,一方面是熟练了,另外wordpress自身的优点也很重要。
针对原版,主要是增加了宽屏适应,修改了部分版面,进一步简化了侧边栏。FancyBox没用插件,毕竟使用不了那么多功能,就加载了一个JS就完了。以后这个风格还会继续完善,争取逐渐从weisay的模子中脱离出来。
凡事有弊有利,所有的博文都消失了。我得以重新审视自己的过去和现在有的知识。
继续进步,坚持不懈!
]]>